在 AI 问数项目上,我们的进展是缓慢的。起初我们认定“精确的问题才有精确的答案,模糊的问题只有模糊的答案”,后来我们不得不开始琢磨“怎样将模糊的问题变得精确”。这是一趟充满迷茫与挑战的旅程,在问数流程中像打补丁式衔接上一个又一个 LLM 节点,解决一个问题的同时可能会衍生更多问题。更多的 LLM 节点意味着,更多的错误积累,更多的 TOKEN 消耗,以及越来越复杂臃肿的流程。
到今天,我们将问数的核心流程拆分成以下两种。
第一,“快速问答”:用槽位处理的方式匹配 SQL 模板来生成 SQL,能问答的问题范围有限,但可以确保答案精准。
第二,“深度思考”:使用 LLM 来生成SQL,能回答的问题范围更广但无法保证 AI 的理解不会出错。
这两个流程中,将“快速问题”作为初始默认流程,确保可靠优于创新,但也给予用户自由切换不同流程的权限。
快速问答-填充槽位匹配 SQL 🔗
总体思路分为以下三个步骤:第一步,根据用户输入的问题匹配槽位名称、提取每个槽位的值、判断对应的表名称;第二步,根据转换槽位名称后的内容再去匹配对应的 SQL 模板;第三步,将第一步的槽位值、表名称填充到 SQL 模板中生成最终可执行的 SQL。
设定槽位有这样一些:机构名称(org_name)、时间段(query_time)、指标名称(select_fileds)、指标主题(topic)、表名称(table_name)等等,那么一个简单的栗子如下所示。
| 序号 | 步骤 | 输入内容 | 输出内容 |
|---|---|---|---|
| 1 | 提取槽位 | 河南个险从2024年3月开始最近三个月的API月达成率是多少? | {org_name}个险从{query_time}的{topic}{select_fileds}是多少? |
| 2 | 匹配 SQL 模板 | 上一步输出的结果、准备好的 SQL 模板 | "select 分公司, 月份, {select_fields} from {table_name} where 月份 in {query_time} and 分公司 in {org_name} order by 月份" |
| 3 | 生成最终 SQL | 上一步输出的结果、上上步提取的槽位值 | "select 分公司, 月份, 月达成率 from db.table_name where 月份 in ('2024-03','2024-04','2024-05') and 分公司 in ('河南') order by 月份" |
实际应用场景更为复杂,比如机构会扩展为多个层级,提取的槽位需要包括应绘制的图表类型,因而需要准备更为丰富的 SQL 模板,以下是一些穷举的思路。
首先,梳理需要穷举的事项。其一,问题类型分为三大类,分别是根据机构和时期筛选指标、筛选机构、筛选时期。其二,每大类问题下可组合的槽位,如下。
| 槽位名称 | 数量或类别 |
|---|---|
| 上级机构数量 | 0、一、多 |
| 下级机构数量 | 0、一、多 |
| 时期数量 | 一、多 |
| 指标数量 | 一、多 |
| 量纲 | 相同、不同 |
其次,穷举问题以及对应的 SQL 模板。
最后,根据实际应用场景丰富细节,比如提取每一个槽位的规则、用户问题中槽位缺失时默认取值、扩展同义词库等等。
深度思考-使用 LLM 写 SQL 🔗
此前的一个版本参照这里,将提取日期、机构也交由 LLM 处理。下面这一版本使用代码来划定语义模糊的边界,比如日期、机构、指标等,生成 SQL 的部分交给 LLM 处理。
查看绘图的 R 代码
library(DiagrammeR)
grViz(diagram = "digraph{
# 定义图形布局,从左到右
graph[rankdir = TB]
# 定义节点
node[shape = rectangle]
A[label = '开始']
B1[label = '提取日期范围\n节点:代码执行']
B2[label = '提取机构范围\n节点:代码执行']
B3[label = '提取主题和字段名称\n节点:代码执行']
C1[label = 'DDL:建表脚本\n节点:知识库']
C2[label = 'Q->SQL:常用 SQL 脚本库\n节点:知识库']
C3[label = 'DB:数据库字段描述\n节点:知识库']
C4[label = '指标释义\n节点:知识库']
D[label = '生成 SQL\n节点:LLM']
E[label = '执行 SQL\n工具:连接数据库']
F[label = '判断图表类型\n节点:代码执行']
G[label = '判断绘图还是制表\n节点:条件分支']
H[label = '提取绘图参数\n节点:代码执行']
I[label = '生成 Echarts 代码\n节点:代码执行']
J[label ='绘图\n节点:直接回复']
K[label = '提取 Markdown\n节点:代码执行']
L[label ='制表\n节点:直接回复']
# 定义线
edge[arrowsize = 1, style = solid, samehead = h1, sametail = t1]
A -> {B1, B2, B3, C1, C2, C3, C4};
{B1, B2, B3, C1, C2, C3, C4} -> D;
D -> E -> F -> G;
G -> H -> I -> J;
G -> K -> L;
}")
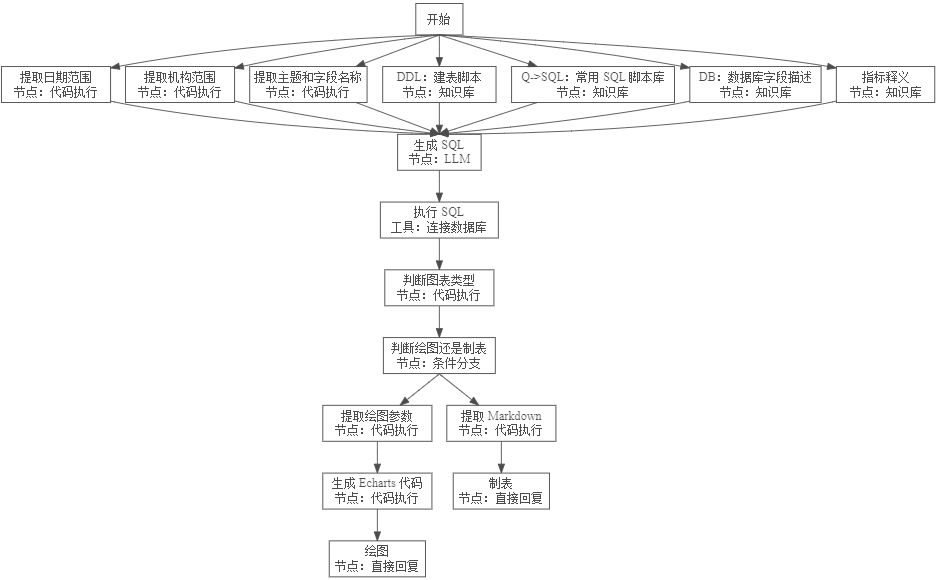
本流程是在 Dify 中创建了一个工作流(chatflow)。接下来依次详解各个节点的输入输出信息,以及对于需求的考量。
注:Python 代码都是让 Copilot(GPT-5)根据描述的需求来写的。
开始 🔗
通常为了对数据做权限控制,开始节点还需要输入其他参数,本文中且都忽略。
- 输入字段
- query 文本 String
提取日期范围 🔗
- 输入变量
- query: 开始/(x)query String
- 输出变量
- query_time: String
此节点的考量是,只用 LLM 似乎不能百分百每次都准确识别出“今年”、“当年”等词语的涵义,而日常工作中问数时有关统计时点、统计时段的句式几乎是固定的,因此这一步就是确立规则用代码来提取信息,试图“将模糊变精确”。相关需求点如下:
- 中文数字需要被识别,如零、一、二等等。
- 用代码提取当前时间,以及对应的年、月、日等。
- 识别日期相关句式,如最近n年、最近n个月、第几季度、某年某月、某年某月到某月、二位数年月、四位数年月、相对日期(今年/当年/本年/去年)、相对日期与绝对日期的组合(去年n月/今年前x季度)等。
- 匹配时仅保留最长子串,不重复(PS。AI理解后的说法是“最长优先 + 起始位置优先,选择非重叠命中”),如“今年3月”需要被识别为完整的“今年3月”,而不是“今年”和“3月”。
查看节点的 Python 代码
import re
import datetime
from typing import List, Optional
# ====== 中文数字处理 ======
_CN_DIGITS = {
"零": 0, "〇": 0, "○": 0, "O": 0,
"一": 1, "二": 2, "两": 2, "三": 3, "四": 4,
"五": 5, "六": 6, "七": 7, "八": 8, "九": 9
}
def parse_cn_int_1_99(s: str) -> Optional[int]:
if not s:
return None
if s.isdigit():
return int(s)
if s in _CN_DIGITS:
return _CN_DIGITS[s]
if s == "十":
return 10
if s.startswith("十") and len(s) == 2 and s[1] in _CN_DIGITS:
return 10 + _CN_DIGITS[s[1]]
if len(s) == 2 and s[0] in _CN_DIGITS and s[1] == "十":
return _CN_DIGITS[s[0]] * 10
if len(s) == 3 and s[0] in _CN_DIGITS and s[1] == "十" and s[2] in _CN_DIGITS:
return _CN_DIGITS[s[0]] * 10 + _CN_DIGITS[s[2]]
return None
def parse_cn_year(s: str) -> Optional[int]:
s = s.strip()
if re.fullmatch(r"\d{4}", s):
return int(s)
cn_digits_map = {**{k: str(v) for k, v in _CN_DIGITS.items()}}
# 全中文逐位年份:二零二五/二〇二五
if all(ch in cn_digits_map for ch in s) and len(s) == 4:
return int("".join(cn_digits_map[ch] for ch in s))
# 两位年份(阿拉伯):25 -> 2025
if re.fullmatch(r"\d{2}", s):
return 2000 + int(s)
# 两位年份(中文):二五 -> 2025
if len(s) == 2 and all(ch in cn_digits_map for ch in s):
return 2000 + int("".join(cn_digits_map[ch] for ch in s))
return None
def _months_range(year: int, start_m: int, end_m: int) -> List[str]:
return [f"{year}-{m:02d}" for m in range(start_m, end_m + 1)] # 修改为 yyyy-mm 格式
def _roll_recent_months(n: int) -> List[str]:
"""最近n个月(含当月),输出YYYY-MM,从最早到最新。"""
now = datetime.datetime.now()
y, m = now.year, now.month
acc = []
for i in range(n - 1, -1, -1):
yy = y
mm = m - i
while mm <= 0:
yy -= 1
mm += 12
acc.append(f"{yy}-{mm:02d}") # 修改为 yyyy-mm 格式
return acc
def _quarter_range(year: int, q_str: str) -> List[str]:
"""将季度中文序数映射为月份范围,支持 第一/第二/第三/第四 以及 一/二/三/四。"""
q_map = {
"第一": (1, 3), "第二": (4, 6), "第三": (7, 9), "第四": (10, 12),
"一": (1, 3), "二": (4, 6), "三": (7, 9), "四": (10, 12),
}
if q_str in q_map:
s, e = q_map[q_str]
return _months_range(year, s, e)
return []
def expand_date_expr(expr: str, base_year: int = None) -> List[str]:
if base_year is None:
base_year = datetime.datetime.now().year
expr = expr.strip()
# 绝对年月:2025年1月 / 二零二五年一月
m = re.fullmatch(r"([0-9]{4}|[零〇○O一二两三四五六七八九]{4})年([0-9]{1,2}|[一二两三四五六七八九十]{1,3})月", expr)
if m:
y = parse_cn_year(m.group(1))
mo = parse_cn_int_1_99(m.group(2))
if y is not None and mo is not None and 1 <= mo <= 12:
return [f"{y}-{mo:02d}"] # 修改为 yyyy-mm 格式
# 年+月份范围:2025年1-3月 / 二零二五年一到三月
m = re.fullmatch(
r"([0-9]{4}|[零〇○O一二两三四五六七八九]{4})年([0-9]{1,2}|[一二两三四五六七八九十]{1,3})(?:-|到|至)"
r"([0-9]{1,2}|[一二两三四五六七八九十]{1,3})月", expr)
if m:
y = parse_cn_year(m.group(1))
s = parse_cn_int_1_99(m.group(2))
e = parse_cn_int_1_99(m.group(3))
if y is not None and s is not None and e is not None and 1 <= s <= 12 and 1 <= e <= 12 and s <= e:
return _months_range(y, s, e)
# 全年:2025年全年 / 二零二五年全年
m = re.fullmatch(r"([0-9]{4}|[零〇○O一二两三四五六七八九]{4})年全年", expr)
if m:
y = parse_cn_year(m.group(1))
if y is not None:
return _months_range(y, 1, 12)
# 季度:绝对年份(支持 第一/第二/第三/第四)
m = re.fullmatch(r"([0-9]{4}|[零〇○O一二两三四五六七八九]{4})年(第一|第二|第三|第四)季度", expr)
if m:
y = parse_cn_year(m.group(1))
if y is not None:
return _quarter_range(y, m.group(2))
# 今年X-Y月
m = re.fullmatch(
r"(今年|当年|本年)([0-9]{1,2}|[一二两三四五六七八九十]{1,3})(?:-|到|至)([0-9]{1,2}|[一二两三四五六七八九十]{1,3})月",
expr)
if m:
s = parse_cn_int_1_99(m.group(2))
e = parse_cn_int_1_99(m.group(3))
if s is not None and e is not None and 1 <= s <= 12 and 1 <= e <= 12 and s <= e:
return _months_range(base_year, s, e)
# 去年X-Y月
m = re.fullmatch(
r"去年([0-9]{1,2}|[一二两三四五六七八九十]{1,3})(?:-|到|至)([0-9]{1,2}|[一二两三四五六七八九十]{1,3})月", expr)
if m:
s = parse_cn_int_1_99(m.group(1))
e = parse_cn_int_1_99(m.group(2))
if s is not None and e is not None and 1 <= s <= 12 and 1 <= e <= 12 and s <= e:
return _months_range(base_year - 1, s, e)
# 今年X月
m = re.fullmatch(r"(今年|当年|本年)([0-9]{1,2}|[一二两三四五六七八九十]{1,3})月", expr)
if m:
mo = parse_cn_int_1_99(m.group(2))
if mo is not None and 1 <= mo <= 12:
return [f"{base_year}-{mo:02d}"] # 修改为 yyyy-mm 格式
# 去年X月
m = re.fullmatch(r"去年([0-9]{1,2}|[一二两三四五六七八九十]{1,3})月", expr)
if m:
mo = parse_cn_int_1_99(m.group(1))
if mo is not None and 1 <= mo <= 12:
return [f"{base_year - 1}-{mo:02d}"] # 修改为 yyyy-mm 格式
# 今年/去年 + 中文序数季度(新增:一/二/三/四 也支持)
m = re.fullmatch(r"(今年|当年|本年)(第一|第二|第三|第四|一|二|三|四)季度", expr)
if m:
return _quarter_range(base_year, m.group(2))
m = re.fullmatch(r"去年(第一|第二|第三|第四|一|二|三|四)季度", expr)
if m:
return _quarter_range(base_year - 1, m.group(1))
# 相对时间
if expr in {"今年", "当年", "本年"}:
return _months_range(base_year, 1, 12)
if expr == "去年":
return _months_range(base_year - 1, 1, 12)
if expr == "本月":
now = datetime.datetime.now()
return [f"{now.year}-{now.month:02d}"] # 修改为 yyyy-mm 格式
if expr in {"今年前三季度", "前三季度"}:
return _months_range(base_year, 1, 9)
if expr == "上半年":
return _months_range(base_year, 1, 6)
if expr == "下半年":
return _months_range(base_year, 7, 12)
# 最近N年(整年)
m = re.fullmatch(r"最近([0-9]+|[一二两三四五六七八九十]{1,3})年", expr)
if m:
n = parse_cn_int_1_99(m.group(1))
if n and n > 0:
months = []
for y in range(base_year - n + 1, base_year + 1):
months.extend(_months_range(y, 1, 12))
return months
# 最近N个月(滚动)
m = re.fullmatch(r"最近([0-9]+|[一二两三四五六七八九十]{1,3})个月", expr)
if m:
n = parse_cn_int_1_99(m.group(1))
if n and n > 0:
return _roll_recent_months(n)
# 两位年:25年 / 二五年(解释为2000+)
m = re.fullmatch(r"([0-9]{2}|[零〇○O一二两三四五六七八九]{2})年", expr)
if m:
y = parse_cn_year(m.group(1))
if y is not None:
return _months_range(y, 1, 12)
# 今年前X季度 / 前X季度
m = re.fullmatch(r"(今年|当年|本年)?前([一二三四0-9])季度", expr)
if m:
q_map = {"一": 1, "二": 2, "三": 3, "四": 4}
q_str = m.group(2)
q_num = q_map.get(q_str, int(q_str)) if q_str in q_map or q_str.isdigit() else None
if q_num:
end_month = q_num * 3
return _months_range(base_year, 1, end_month)
# 未识别则原样返回
return [expr]
def extract_date_phrases(text: str) -> List[str]:
"""从文本中提取所有日期短语,保留最长匹配"""
cn_year = r"(?:[0-9]{4}|[零〇○O一二两三四五六七八九]{4})"
cn_year2 = r"(?:[0-9]{2}|[零〇○O一二两三四五六七八九]{2})"
cn_month = r"(?:[0-9]{1,2}|[一二两三四五六七八九十]{1,3})"
patterns = [
rf"{cn_year}年{cn_month}(?:-|到|至){cn_month}月",
rf"{cn_year}年(第一|第二|第三|第四)季度",
rf"(今年|当年|本年){cn_month}(?:-|到|至){cn_month}月",
rf"去年{cn_month}(?:-|到|至){cn_month}月",
rf"(今年|当年|本年){cn_month}月",
rf"去年{cn_month}月",
r"(今年前[一二三四0-9]季度|前[一二三四0-9]季度)", # 修改为通用前X季度
r"(上半年|下半年)",
rf"{cn_year}年{cn_month}月",
rf"{cn_year}年全年",
r"最近(?:[0-9]+|[一二两三四五六七八九十]{1,3})个月",
r"最近(?:[0-9]+|[一二两三四五六七八九十]{1,3})年",
r"(去年|今年|当年|本年|本月)",
rf"{cn_year2}年",
r"(今年|当年|本年)?前([一二三四1-4])季度",
]
raw_phrases = []
for pat in patterns:
for m in re.finditer(pat, text):
raw_phrases.append(m.group())
# 去掉短的子串,只保留最长匹配
phrases = []
for ph in raw_phrases:
if not any((ph != other and ph in other) for other in raw_phrases):
phrases.append(ph)
return phrases
# ====== Dify 节点入口 ======
def main(query: str) -> dict:
"""
query: 输入的用户查询文本
"""
base_year = None
phrases = extract_date_phrases(query)
months = []
for ph in phrases:
months.extend(expand_date_expr(ph, base_year))
query_time_str = ",".join(months)
return {
"query_time": query_time_str
}
提取机构范围 🔗
- 输入变量
- query: 开始/(x)query String
- 输出变量
- org_name: String
- sub_org_name: String
由于数据中准备了两个层级的机构数据,加上机构数量有限,因此将全部机构的名称作为词库放入代码中进行匹配。还会遇到两个问题,如下。
- 仅仅按名称匹配无法识别一些组合名称,如两广、两湖,还需要扩充一些同义词库。
- 同时出现两个层级的机构名称时,需要结合应用场景做规则调整。
查看节点的 Python 代码
# ====== 机构词库 ======
org_names = {'湖北', ...} # 分公司
sub_org_names = {'武汉', '宜昌', ...} # 中支
def _dedup_preserve_order(seq):
seen = set()
out = []
for x in seq:
if x not in seen:
seen.add(x)
out.append(x)
return out
# ====== Dify 节点入口 ======
def main(query: str) -> dict:
"""
query: 输入的用户查询文本
"""
import re
# 收集所有命中的词及其span
hits = []
for name in org_names:
for m in re.finditer(re.escape(name), query):
hits.append((m.start(), m.end(), name, "org"))
for name in sub_org_names:
for m in re.finditer(re.escape(name), query):
hits.append((m.start(), m.end(), name, "sub"))
# 最长优先 + 起始位置优先,选择非重叠命中
hits.sort(key=lambda x: (-(x[1] - x[0]), x[0]))
chosen = []
occupied = [False] * len(query)
for s, e, name, kind in hits:
if any(occupied[i] for i in range(s, e)):
continue
chosen.append((s, e, name, kind))
for i in range(s, e):
occupied[i] = True
# 保序输出各类名称
org_list = _dedup_preserve_order([name for _, _, name, kind in chosen if kind == "org"])
sub_list = _dedup_preserve_order([name for _, _, name, kind in chosen if kind == "sub"])
return {
"org_name": ",".join(org_list),
"sub_org_name": ",".join(sub_list),
}
提取主题和字段名称 🔗
- 输入变量
- query: 开始/(x)query String
- 输出变量
- topic: String
- select_field: String
行业中、公司内部所定义的指标名称是有限的,因此也在不断扩充丰富同义词库的基础上进行匹配。在设计可供问数的基础数据表时,应确保主题之间互不交叉、指标定义边界明确。
查看节点的 Python 代码
# ====== 主题与指标定义 ======
topics = {
"API": {"API", "标准保费"},...
}
indicators = {
"API": {
"月达成": {"月达成", "业绩达成"},
"年达成": {"年达成"},
"月达成率": {"月达成率"},
"年达成率": {"年达成率"},
"月同期": {"月同期"},
"年同期": {"年同期"},
"月同比": {"月同比"},
"年同比": {"年同比"},
},...
}
def _dedup_preserve_order(seq):
seen = set()
out = []
for x in seq:
if x not in seen:
seen.add(x)
out.append(x)
return out
# ====== Dify 节点入口 ======
def main(query: str) -> dict:
found_topics = []
topic_indicators = {}
# 遍历所有主题
for topic, synonyms in topics.items():
for syn in synonyms:
if syn in query:
found_topics.append(topic)
# 在该主题下匹配指标
inds = []
for ind, ind_syns in indicators[topic].items():
for syn2 in ind_syns:
if syn2 in query:
inds.append(ind)
topic_indicators[topic] = _dedup_preserve_order(inds)
break
# 拼接成字符串:主题:指标1,指标2;主题2:指标A
select_field_parts = []
for topic, vals in topic_indicators.items():
if vals:
select_field_parts.append(f"{topic}:{','.join(vals)}")
else:
select_field_parts.append(f"{topic}:")
result = {
"topic": ",".join(_dedup_preserve_order(found_topics)),
"select_field": ";".join(select_field_parts) # 字符串类型
}
return result
判断图表类型 🔗
- 输入变量
- query_data: 执行查询语句/(x)json Array[Object]
- 输出变量
- chart_type: String
- indicators: String
- months: String
- org_key: String
- orgs: String
在由 LLM 生成 SQL 并连接数据库执行后,根据获得的数据(query_data)来判断应绘制的图表类型(chart_type)。在本文涉及的应用场景中,query_data 解析以后里面通常会有月份、机构(分公司或中支)、除月份和机构以外的其他指标,判断 chart_type 有以下几种情况。
- 如果月份有大于等于2个连续的值,机构有一个或多个值,其他指标的数量只有一个,那么chart_type 应为 line1,对应多组机构的折线图;
- 如果月份有大于等于2个连续的值、机构仅有一个值,其他指标的数量有一个或多个,那么chart_type 应为 line2,对应多个指标的折线图;
- 如果月份有零个或一个,机构有一个或多个,其他指标的数量有一个,那么 chart_type 应为 bar1,对应普通柱状图;
- 如果月份有零个或一个,机构有一个或多个,其他指标的数量有大于等于2个,那么 chart_type 应为 bar2,对应多组机构的堆叠柱状图;
- 如果月份有大于等于2个值但不连续,机构有一个或多个,其他指标的数量有一个,那么 chart_type应为 bar3,对应多组时间的堆叠柱状图;
- 如果月份有大于等于2个值但不连续,机构有一个或多个,其他指标的数量有大于等于2个,那么 chart_type 应为 table;
如果想要绘制更多不同类型的图形,如饼图、散点图,也需要根据绘图所需数据来分别判断,即继续扩充需判断的规则。
查看节点的 Python 代码
import json
from typing import Any, Dict, List, Union
def main(query_data: Union[str, List[Dict[str, Any]], Dict[str, Any]]) -> dict:
# 1) 解析输入
if isinstance(query_data, str):
try:
parsed = json.loads(query_data)
except Exception as e:
raise ValueError(f"query_data 格式错误:{e}")
else:
parsed = query_data
# 2) 提取 data 列表
if isinstance(parsed, list):
if len(parsed) > 0 and isinstance(parsed[0], dict) and "data" in parsed[0]:
data_list = parsed[0]["data"]
else:
data_list = parsed
elif isinstance(parsed, dict):
if "data" in parsed and isinstance(parsed["data"], list):
data_list = parsed["data"]
else:
raise ValueError("query_data 中未找到 data 部分")
else:
raise ValueError("query_data 必须是列表或字典")
if not isinstance(data_list, list) or len(data_list) == 0:
raise ValueError("data 必须是非空列表")
keys = list(data_list[0].keys())
# 判断是否有月份、分公司、中支字段
has_month = "月份" in keys
has_branch = "分公司" in keys
has_subbranch = "中支" in keys
org_key = "分公司" if has_branch else ("中支" if has_subbranch else None)
# 提取月份、机构、指标
months = sorted(set(item["月份"] for item in data_list)) if has_month else []
orgs = sorted(set(item[org_key] for item in data_list)) if org_key else []
indicators = [k for k in keys if k not in ["月份", "分公司", "中支"]]
# 判断月份是否连续
def is_consecutive(values: List[int]) -> bool:
if not values: return False
sorted_vals = sorted(values)
return all(sorted_vals[i + 1] - sorted_vals[i] == 1 for i in range(len(sorted_vals) - 1))
chart_type = None
if len(months) >= 2 and is_consecutive([int(m) for m in months if str(m).isdigit()]):
if orgs and len(indicators) == 1:
chart_type = "line1"
elif (not orgs or len(orgs) == 1) and len(indicators) >= 1:
chart_type = "line2"
elif len(months) <= 1:
if orgs and len(indicators) == 1:
chart_type = "bar1"
elif orgs and len(indicators) >= 2:
chart_type = "bar2"
elif len(months) >= 2 and not is_consecutive([int(m) for m in months if str(m).isdigit()]):
if orgs and len(indicators) == 1:
chart_type = "bar3"
elif orgs and len(indicators) >= 2:
chart_type = "table"
return {
"chart_type": str(chart_type),
"months": json.dumps(months, ensure_ascii=False),
"orgs": json.dumps(orgs, ensure_ascii=False),
"indicators": json.dumps(indicators, ensure_ascii=False),
"org_key": str(org_key)
}
提取绘图参数 🔗
- 输入变量
- chart_type: 判断图表类型/(x)chart_type String
- query_data: 执行查询语句/(x)json Array[Object]
- indicators: 判断图表类型/(x)indicators String
- months: 判断图表类型/(x)months String
- org_key: 判断图表类型/(x)org_key String
- orgs: 判断图表类型/(x)orgs String
- 输出变量
- chart_type: String
- series_data: String
- x_name: String
- x_values: String
- y_name: String
由于现阶段绘图的图表类型还只写了折线图和柱状图,即限于直角坐标系,所以提取的绘图参数暂时只有数据系列(series_data)、X 轴名称(x_name)、X 轴轴标签(x_values)、Y 轴名称(y_name)等。如果需要绘制更多不同类型的图形,对应提取的绘图参数也要对应调整。
查看节点的 Python 代码
import json
from collections import defaultdict
from typing import Any, Dict
def main(
query_data: Any,
chart_type: str,
months: str = "[]",
orgs: str = "[]",
indicators: str = "[]",
org_key: str = None
) -> dict:
# 解析 JSON 字符串
months = json.loads(months)
orgs = json.loads(orgs)
indicators = json.loads(indicators)
# 解析 query_data
if isinstance(query_data, str):
parsed = json.loads(query_data)
else:
parsed = query_data
if isinstance(parsed, list):
if len(parsed) > 0 and isinstance(parsed[0], dict) and "data" in parsed[0]:
data_list = parsed[0]["data"]
else:
data_list = parsed
elif isinstance(parsed, dict):
data_list = parsed["data"]
else:
raise ValueError("query_data 必须是列表或字典")
series_data = []
x_key = None
x_values = []
if chart_type in ["line1", "line2"]:
x_key = "月份"
x_values = months
if chart_type == "line1":
grouped = defaultdict(list)
for item in data_list:
grouped[item[org_key]].append(item)
for gname, gitems in grouped.items():
gitems_sorted = sorted(gitems, key=lambda x: x["月份"])
for ind in indicators:
series_data.append({
"name": f"{gname}-{ind}",
"type": "line",
"data": [it[ind] for it in gitems_sorted]
})
elif chart_type == "line2":
sorted_data = sorted(data_list, key=lambda x: x["月份"])
for ind in indicators:
series_data.append({
"name": ind,
"type": "line",
"data": [it[ind] for it in sorted_data]
})
elif chart_type in ["bar1", "bar2"]:
x_key = org_key
x_values = orgs
for ind in indicators:
series_data.append({
"name": ind,
"type": "bar",
"data": [item[ind] for item in data_list if item[org_key] in orgs]
})
elif chart_type == "bar3":
x_key = "月份"
x_values = months
grouped = defaultdict(list)
for item in data_list:
grouped[item[org_key]].append(item)
for gname, gitems in grouped.items():
gitems_sorted = sorted(gitems, key=lambda x: x["月份"])
for ind in indicators:
series_data.append({
"name": f"{gname}-{ind}",
"type": "bar",
"data": [it[ind] for it in gitems_sorted]
})
elif chart_type == "table":
return {
"chart_type": "table",
"data": json.dumps(data_list, ensure_ascii=False)
}
return {
"x_name": str(x_key),
"y_name": ";".join([s["name"] for s in series_data]),
"x_values": json.dumps(x_values, ensure_ascii=False),
"series_data": json.dumps(series_data, ensure_ascii=False),
"chart_type": str(chart_type)
}
生成 Echarts 代码 🔗
- 输入变量
- chart_type: 提取绘图参数/(x)chart_type String
- series_data: 提取绘图参数/(x)series_data String
- x_name: 提取绘图参数/(x)x_name String
- x_values: 提取绘图参数/(x)x_values String
- y_name: 提取绘图参数/(x)y_name String
- 输出变量
- echarts_code: String
值得写一写的是,Echarts 绘图的细节也可以充实更多,比如现在绘制堆叠柱状图都是把各系列数据堆一堆,其实也可以调整成堆多堆。
查看节点的 Python 代码
import json
def main(x_values: str, series_data: str, x_name: str, y_name: str, chart_type: str) -> dict:
x_data = json.loads(x_values.replace("'", '"'))
series_raw = json.loads(series_data)
# 检查是否包含百分比或万元相关指标
is_percent = False
is_wanyuan = False
for s in series_raw:
# 转换百分比数据
if any(isinstance(v, str) and "%" in v for v in s.get("data", [])):
is_percent = True
s["data"] = [float(str(v).replace("%", "")) if isinstance(v, str) and "%" in v else v for v in s["data"]]
# 判断是否为万元相关指标
if any(key in s.get("name", "") for key in ["月达成", "年达成", "月同期", "年同期"]):
is_wanyuan = True
# 公共工具箱配置
toolbox_config = {
"show": 'true',
"feature": {
"dataZoom": {
"yAxisIndex": 'none',
"title": {
"zoom": "区域缩放",
"back": "区域缩放还原"
}
},
"dataView": {"readOnly": 'true',
"title": "查询结果",
"lang": ['查询结果', '关闭', '刷新']
},
"magicType": {"type": ['line', 'bar'],
"title": {
"line": "折线图",
"bar": "柱状图"
}
},
"restore": {
"title": "还原"
},
"saveAsImage": {
"type": "png",
"title": "另存为图片"
}
}
}
# tooltip formatter 根据情况调整(使用模板字符串)
tooltip_config = {"trigger": "axis"}
if is_percent:
tooltip_config["valueFormatter"] = "{value}%"
y_name = "%"
elif is_wanyuan:
tooltip_config["valueFormatter"] = "{value} 万元"
y_name = "万元"
# 基础配置
echarts_config = {
"tooltip": tooltip_config,
"legend": {"top": "bottom"},
"toolbox": toolbox_config,
"xAxis": {
"type": "category",
"name": x_name,
"data": x_data
},
"yAxis": {
"type": "value",
"name": y_name
},
"series": series_raw
}
# 针对 bar2 和 bar3 添加 stack 属性
if chart_type == "bar2":
for s in series_raw:
s["stack"] = "总量"
echarts_config["tooltip"]["axisPointer"] = {"type": "shadow"}
elif chart_type == "bar3":
for s in series_raw:
s["stack"] = "时间"
echarts_config["tooltip"]["axisPointer"] = {"type": "shadow"}
echarts_script = f"```echarts\n{json.dumps(echarts_config, ensure_ascii=False, indent=2)}\n```"
return {
"echarts_code": echarts_script
}
提取 Markdown 🔗
- 输入变量
- json: 执行查询语句/(x)json Array[Object]
- 输出变量
- markdown: String
执行SQL后输出的内容有三个部分,分别是 text 、files、json,其他处理数据的节点诸如“判断图表类型”、“提取绘图参数”都是解析 json 中的 data 部分,实际上 json 里面还有一个部分就是 markdown 格式,直接取出来就能制表。
测试运行整个工作流,输入 query 为:“查看2025年1月湖北、湖南、河北、河南等的NBEV年达成、月达成、月同期”。可以看到此节点输入的内容如下。
{
"json": [
{
"data": [
{
"NBEV_年达成": 1558,
"NBEV_月同期": 1937,
"NBEV_月达成": 1558,
"月份": "2025-01",
"机构名称": "河北"
},
{
"NBEV_年达成": 1070,
"NBEV_月同期": 1047,
"NBEV_月达成": 1070,
"月份": "2025-01",
"机构名称": "河南"
},
{
"NBEV_年达成": 555,
"NBEV_月同期": 482,
"NBEV_月达成": 555,
"月份": "2025-01",
"机构名称": "湖南"
},
{
"NBEV_年达成": 703,
"NBEV_月同期": 844,
"NBEV_月达成": 703,
"月份": "2025-01",
"机构名称": "湖北"
}
],
"markdown": "| 机构名称 | 月份 | NBEV_月达成 | NBEV_年达成 | NBEV_月同期 |\n| --- | --- | --- | --- | --- |\n| 河北 | 2025-01 | 1558 | 1558 | 1937 |\n| 河南 | 2025-01 | 1070 | 1070 | 1047 |\n| 湖南 | 2025-01 | 555 | 555 | 482 |\n| 湖北 | 2025-01 | 703 | 703 | 844 |\n",
"status": "success"
}
]
}
查看节点的 Python 代码
import json
from typing import Dict, Any
def main(query_data: Dict[str, Any] = None, **kwargs) -> dict:
"""
从输入中提取 markdown 表格字符串:
- query_data 允许为空(便于兼容仅用关键字参数的调用),随后用 kwargs 回填;
- 最终确保 query_data 存在,并且含有 json 列表;
- 优先使用首项中的 markdown 字段;如无,可选从 data 自动生成(默认关闭)。
"""
# 1) 初始化并回填 query_data
query_data = query_data or {}
# 将 kwargs 中的 json 回填进 query_data(Dify 常见:main(json=[...]))
if "json" in kwargs and "json" not in query_data:
query_data["json"] = kwargs["json"]
# 2) 校验结构
if "json" not in query_data or not isinstance(query_data["json"], list):
raise ValueError("输入数据格式错误:缺少 json 列表")
items = query_data["json"]
if len(items) == 0 or not isinstance(items[0], dict):
raise ValueError("输入数据格式错误:json 列表为空或首项不是对象")
first_item = items[0]
# 3) 优先提取已提供的 markdown 字段
if "markdown" in first_item and isinstance(first_item["markdown"], str):
return {"markdown": first_item["markdown"]}
# 4) 如无 markdown,可根据 data 生成(如需开启,取消注释)
# if "data" in first_item and isinstance(first_item["data"], list) and first_item["data"]:
# rows = first_item["data"]
# preferred_cols = ["机构名称", "月份", "API:月达成"]
# cols = preferred_cols if all(c in rows[0] for c in preferred_cols) else list(rows[0].keys())
# header = "| " + " | ".join(cols) + " |"
# sep = "| " + " | ".join(["---"] * len(cols)) + " |"
# lines = [header, sep]
# for r in rows:
# line = "| " + " | ".join(str(r.get(c, "")) for c in cols) + " |"
# lines.append(line)
# markdown_str = "\n".join(lines)
# return {"markdown": markdown_str}
# 5) 若既没有 markdown,也没有 data,则报错
raise ValueError("未找到 markdown 字段,且无法从 data 自动生成")
其他补充 🔗
正式上线后,随着用户使用日志的积累,以下方面还可继续优化。
- 扩展相似问:分析出日志中的高频问题,可以往流程中插入相似问题知识库。
- 扩展同义词库:比如更多的专业术语、用户日常使用习惯中常用的缩略词。
- 收集回答有误的问题……