时间来到2023年4月,有很多政府部门的2022年度报告已经公开,数据总能体现一些问题,挖个坑先。
笔者今晚无意中翻到了武汉市的2022年度住房公积金报告,里面显示2022年的实缴职工278.14万人。前几天笔者在整理《江村经济》的读书笔记时,顺手翻了翻七普数据,里面记载截止2020年我国总人口数是1409778727,其中20-59岁的人口数是819692431,占比为58%。2020年武汉市的常住人口数在1200万以上,若也按20-59岁的工作人口比例为58%来粗略算的话1,278.14万人显然不够。难道是因为武汉整体就业环境差,很多公司都不交公积金嘛?为了简单验证猜想,笔者顺手翻了北京、上海、武汉这三个城市的2022年度公积金报告。
先看这些报告里面的第一组数字:
- 北京:实缴单位436653个,实缴职工946.48万人,新开户职工73.68万人,净增职工2.42万人。
- 上海:实缴单位52.13万家,实缴职工936.20万人,新开户职工70.61万人,净增职工11.15万人。
- 武汉:实缴单位57114家,实缴职工278.14万人,新开户职工33.09万人,净增职工14.63万人。
由于各城市统计年鉴对人口的划分方式不完全一致,比如北京有按城乡分,但上海有按外来人口分,武汉直接统计从业人数,笔者并不是要做多么精确的推理,只是验证一个猜想,所以就简单粗暴地处理一下。下面的数据也许可以部分说明一些问题。
-
按北京2022年统计年鉴中的七普数据,20-59岁人口有1427.4万人,假如按城乡比例仅85%来算即1213万,那么实缴公积金的职工人数比例为78%。
-
按上海2022年统计年鉴中的七普数据,20-59岁人口有1590.9万人,也假如再乘以城乡比例85%即1352万人,那么实缴公积金的职工人数比例为69%。
-
按武汉2021年统计年鉴,2020年从业人数为603.79万,那么实缴公积金的职工人数比例为46%。
虽然说各城市统计年鉴上面,统计的大类相同小类相异,但是公积金年度报告的所有统计项是完全一致的,大大增加了可以比较的空间。(ps在三份报告里,北京在计算百分比时,仅算到小数点后一位,另两个都是算到小数点后两位。)粗略读完三份报告后,笔者将第五节社会经济效益中的数据拿出来瞅了瞅。
按收入划分 🔗
武汉的报告中有注释,中、低收入是“指收入在当地上年社会平均工资3倍以内”,高收入是“指收入在当地上年社会平均工资3倍(含)以上”,北京和上海的报告中没有针对中、低收入和高收入做注释,这里权且当定义是一致的。下面单元格里面,填充柱子的取值范围均为0-30%。
查看绘图的数据和 R 代码
.border-left {
border-left: 2px solid #555;
}
library(DT)
data <- data.frame(
value1 = c(88.7, 92.33, 98.06),
value2 = c(11.3, 7.67, 1.94),
value3 = c(97.3, 97.37, 99.57),
value4 = c(2.7, 2.63, 0.43),
value5 = c(77.3, 85.9, 99.36),
value6 = c(22.7, 14.1, 0.64)
)
colnames = htmltools::withTags(table(thead(tr(
th(rowspan = 2, colspan = 1, '城市'),
th(rowspan = 1, colspan = 2, '缴存职工'),
th(rowspan = 1, colspan = 2, '新开户职工'),
th(rowspan = 1, colspan = 2, '贷款职工')
),
tr(lapply(
rep(c('中、低收入', '高收入'), 3), th
)))))
datatable(
data,
rownames = c('北京', '上海', '武汉'),
escape = FALSE,
container = colnames,
options = list(
dom = 't',
scrollY = FALSE,
autoWidth = TRUE,
columnDefs = list(
list(targets = '_all', className = 'dt-center'),
list(targets = c(1, 3, 5), class = 'border-left')
)
)
) |>
formatCurrency(
columns = c(1:6),
digits = 2,
currency = '%',
before = FALSE
)|>
formatStyle(
columns = 2,
background = styleColorBar(c(data$value2, 0, 30), '#44A57CFF'),
backgroundSize = '100% 90%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center'
) |>
formatStyle(
columns = 4,
background = styleColorBar(c(data$value4, 0, 30), '#58A449FF'),
backgroundSize = '100% 90%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center'
) |>
formatStyle(
columns = 6,
background = styleColorBar(c(data$value6, 0, 30), '#CEC917FF'),
backgroundSize = '100% 90%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center'
)
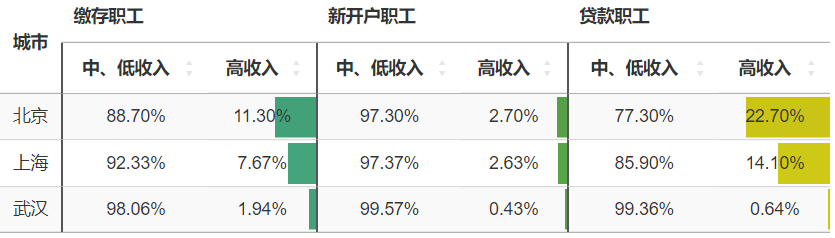
为撒在武汉的缴存、贷款职工中,高收入人群的比例那么低呢?是因为高收入人群本就少么?
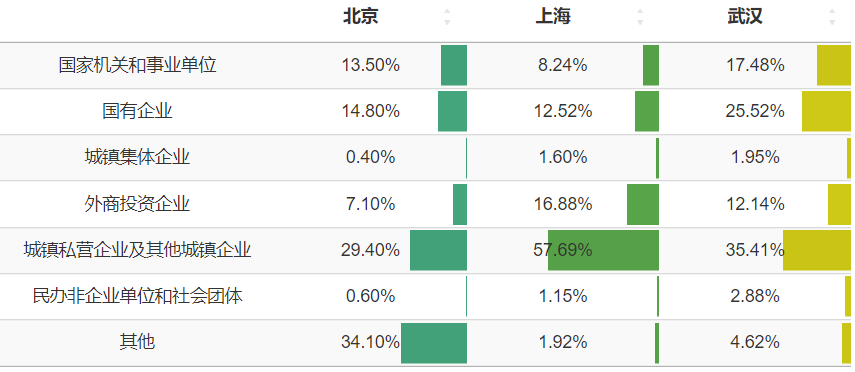
按缴存单位性质划分 🔗
上海有单独统计灵活就业人员,由于比例较低,笔者将其并入“其他”这项中。看武汉的数据,国企事业单位加起来有43%,而北京是28.3%,上海是20.76%。虽然没有数据支撑,但根据常识,私企的职工人数应该是远多于国企事业单位的职工人数的,武汉的数据可能可以表明,有许多私企是不给职工缴存公积金的?
查看绘图的数据和 R 代码
library(DT)
data <- data.frame(
value1 = c(13.5, 14.8, 0.4, 7.1, 29.4, 0.6, 34.1),
value2 = c(8.24, 12.52, 1.6, 16.88, 57.69, 1.15, 1.92),
value3 = c(17.48, 25.52, 1.95, 12.14, 35.41, 2.88, 4.62)
)
datatable(
data,
rownames = c(
'国家机关和事业单位',
'国有企业',
'城镇集体企业',
'外商投资企业',
'城镇私营企业及其他城镇企业',
'民办非企业单位和社会团体',
'其他'
),
colnames = c('北京', '上海', '武汉'),
escape = FALSE,
options = list(
dom = 't',
scrollY = FALSE,
autoWidth = TRUE,
columnDefs = list(
list(targets = '_all', className = 'dt-center'),
list(width = '200px', targets = 0)
)
)
)|>
formatCurrency(
columns = c(1:3),
digits = 2,
currency = '%',
before = FALSE
) |>
formatStyle(
columns = 1,
background = styleColorBar(c(data$value1, 0, 100), '#44A57CFF'),
backgroundSize = '100% 90%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center'
) |>
formatStyle(
columns = 2,
background = styleColorBar(c(data$value2, 0, 100), '#58A449FF'),
backgroundSize = '100% 90%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center'
) |>
formatStyle(
columns = 3,
background = styleColorBar(c(data$value3, 0, 100), '#CEC917FF'),
backgroundSize = '100% 90%',
backgroundRepeat = 'no-repeat',
backgroundPosition = 'center'
)
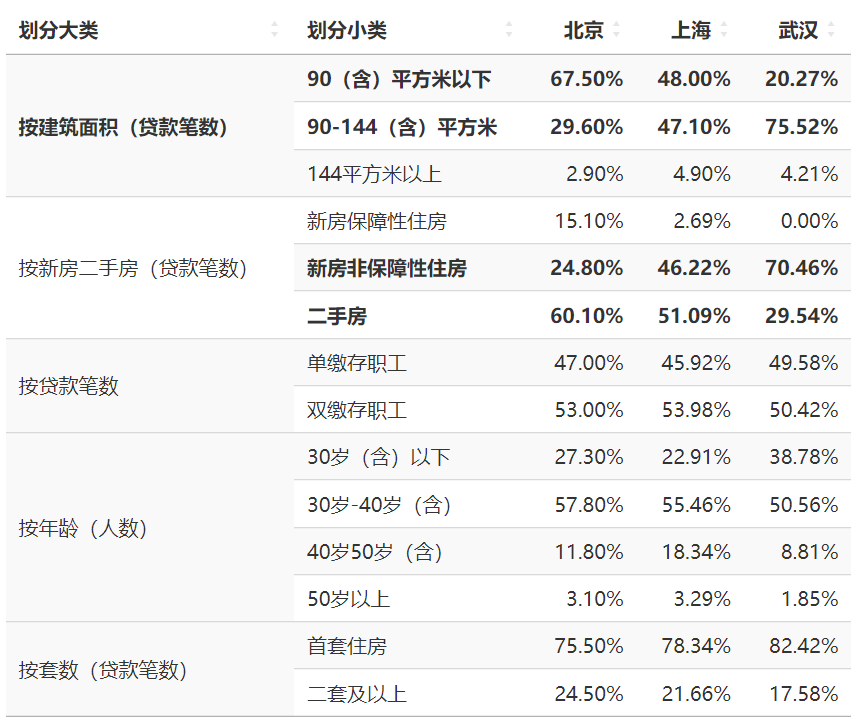
其他划分方式 🔗
北京、上海有统计贷款笔数中新房保障性住房的比例,武汉市没列示这一项,笔者手动填为0。下面的数据看起来挺有意思的,且先把坑挖了放着。
查看绘图的数据和 R 代码
library(DT)
data <- data.frame(
merge=c('按建筑面积(贷款笔数)','按建筑面积(贷款笔数)','按建筑面积(贷款笔数)',
'按新房二手房(贷款笔数)','按新房二手房(贷款笔数)','按新房二手房(贷款笔数)',
'按贷款笔数','按贷款笔数',
'按年龄(人数)','按年龄(人数)','按年龄(人数)','按年龄(人数)',
'按套数(贷款笔数)','按套数(贷款笔数)'),
rownames = c(
'90(含)平方米以下',
'90-144(含)平方米',
'144平方米以上',
'新房保障性住房',
'新房非保障性住房',
'二手房',
'单缴存职工',
'双缴存职工',
'30岁(含)以下',
'30岁-40岁(含)',
'40岁50岁(含)',
'50岁以上',
'首套住房',
'二套及以上'
),
value1 = c(
67.5,
29.6,
2.9,
15.1,
24.8,
60.1,
47,
53,
27.3,
57.8,
11.8,
3.1,
75.5,
24.5
),
value2 = c(
48,
47.1,
4.9,
2.69,
46.22,
51.09,
45.92,
53.98,
22.91,
55.46,
18.34,
3.29,
78.34,
21.66
),
value3 = c(
20.27,
75.52,
4.21,
0,
70.46,
29.54,
49.58,
50.42,
38.78,
50.56,
8.81,
1.85,
82.42,
17.58
)
)
datatable(
data,
rownames = FALSE,
colnames = c('划分大类', '划分小类', '北京', '上海', '武汉'),
callback = htmlwidgets::JS(
"
function mergeRows(table) {
if (!table.tBodies) return;
const tbody = table.tBodies[0];
// 先验证每一行的单元格数量是否相同;若不同,就不尝试合并了(可能已经合并过)
const rows = [...tbody.rows], nrow = rows.length;
if (nrow < 2) return;
let ncol = rows[0].cells.length;
for (let i = 1; i < nrow; i++) {
if (rows[i].cells.length !== ncol) return;
}
let delCells = []; // 待移除的重复单元格
// 寻找每一列上下相同的相邻单元格,并用 rowspan 属性合并之
for (let j = 0; j < ncol; j++) {
// 第 j 列里的所有单元格
let cells = tbody.querySelectorAll('tr > td:nth-child(' + (j + 1) + ')');
let k = 0; // 计数,看有几个相邻单元格相同
for (let i = 1; i < nrow; i++) {
// 向顶层单元格添加 rowspan 属性
function addRowSpan(i) {
if (k > 0) rows[i].cells[j].rowSpan = k + 1;
}
if (cells[i].innerHTML === cells[i - 1].innerHTML) {
k++; // 两行相同的话,计数器 k 加一
delCells.push(cells[i]); // 事后删除当前单元格
// 若到达最后一行,至此合并
if (i == rows.length - 1) addRowSpan(i - k);
} else {
// 若相邻两行不同,那么着手合并之前找到的相同单元格
addRowSpan(i - 1 - k);
k = 0; // 重置计数器
}
}
}
delCells.forEach(cell => cell.remove());
}
document.querySelectorAll('table').forEach(table => mergeRows(table));"),
options = list(dom = 't',
pageLength = 14)
) |> formatCurrency(
columns = c(3:5),
digits = 2,
currency = '%',
before = FALSE
) |> formatStyle(
columns = 2,
target = 'row',
fontWeight = styleRow(rows = c(1, 2, 5, 6), values = 'bold')
)
住房贡献率 🔗
这些报告里面有许多数据都特别有意思,比如从业人员多少,在编多少人,非在编多少人,人员经费花了几个亿。当然啦,如果能有更细致、更多维度交叉的数据,比如国企事业单位的缴存额、私企的缴存额等,会更有意思。不过,仅从住房贡献率这个指标来看,武汉的公积金池子已经开始入不敷出了。
- 北京:2022年,住房公积金个人住房贷款发放额、公转商贴息贷款发放额、项目贷款发放额、住房消费提取额的总和与当年缴存额的比率为85.1%,比上年减少7.3个百分点。
- 上海:2022年,个人住房贷款发放额、住房消费提取额的总和与当年缴存额的比率为89.07%,比上年减少23.45个百分点。
- 武汉:2022年,个人住房贷款发放额和住房消费提取额的总和与当年缴存额的比率为109.75%,比上年减少6.81个百分点。
-
武汉市统计局也发布了武汉市第七次全国人口普查公报,但是年龄划分只分了0-14岁、15-59岁、60岁及以上,所以暂且粗略按全国的比例来估算。 ↩︎