最近在翻国家统计局的普查数据,想着根据人口普查和经济普查数据来做些浅浅的分析,由于本人好奇心重,所以页面上其他普查数据也是会点进去瞅瞅的。话说看人口普查、经济普查数据的时候,我其实没细看数据,因为交叉维度丰富,就只是先走马观花看看目录,然后记录一下想要做进一步分析的数据章节,打算回头再抽完整的时间一口气把数据搜集完。不过在翻到第三次农业普查数据的时候简直是惊呆了,居然一共只有24页,那当然是可以一页一页慢慢看的了。很快我就决定先着手捋捋农业普查的数据,目的并不在于分析,而是想要验证一些我深刻感受到的农村印象的变化:
-
农民进城、耕地流失或荒废。我们村属于平原地带,倒是没见过谁家的地直接荒掉的,有听老家在山区的同事讲她们那边村里很多地荒废了。村子里对于土地归属的划分是在我爷爷的年代完成的,倘若和我爷爷一辈的老人生了多个儿子,又刚好多个儿子都还留在村里种地,那么他们能种的地是不够的,又倘若儿子们又生了更多儿子继续留在村里种地,那么他们能种的土地就更加不够。另一方面,有些人家全家都搬到了乡镇上或者城市里,或者长年在外打工,家里只有老人,老人们年纪大了以后种不了多少地,会将所拥有土地的地面使用权卖给承保商。
-
386199,农村留守人口问题。38指三八妇女节,61指六一儿童节,99指九九重阳节,386199是留守妇女、留守儿童、留守老人的总称。我小时候就是正宗的留守儿童,村子里绝大多数同龄人也是。仅以我们村的情况来看,现在的年轻夫妇会一起出去打工,有些会把孩子带在身边上学,也有些仍然是把孩子交给家中老人来带,留守妇女比较少见,留守老人多于留守儿童。
-
修路、用水、环保。一个村路修得好不好,可能要看村中管理干部的良心和责任心。在过去的许多年,政府有拨款给农村修路,最早是政府出一部分、每家每户出一部分,不过附近许多村子修的路的路面宽度是不一样的,我们村的路并不算是最窄的。很早以前修路是铺石子路,后来变成水泥路,这两年附近别的村子修了沥青路,预计我们村也快了。前些年村里通了自来水,人们告别了河边取水、井边取水的年代。家门前的那条河早就被污染了,小时候家家户户往河里倒垃圾,现在是每天有人收垃圾,并且垃圾需要扔在指定位置。
既然确立了简单的分析方向,那下一步自然就是开始收集数据,在这个过程中,我不断想起另一个疑惑了近一年的问题:只有两个点,到底能不能分析趋势?
- 依全国人口普查条例:
第八条 人口普查每10年进行一次,尾数逢0的年份为普查年度,标准时点为普查年度的11月1日零时。
第十二条 人口普查主要调查人口和住户的基本情况,内容包括姓名、性别、年龄、民族、国籍、受教育程度、行业、职业、迁移流动、社会保障、婚姻、生育、死亡、住房情况等。
- 依全国农业普查条例:
第八条 农业普查每 10 年进行一次,尾数逢 6 的年份为普查年度,标准时点为普查年度的 12 月 31 日 24 时。
第十二条 农业普查内容包括:农业生产条件、农业生产经营活动、农业土地利用、农村劳动力及就业、农村基础设施、农村社会服务、农民生活,以及乡镇、村民委员会和社区环境等情况。
- 依全国经济普查条例:
第七条 经济普查每5年进行一次,标准时点为普查年份的12月31日。
第十三条 经济普查的主要内容包括:单位基本属性、从业人员、财务状况、生产经营情况、生产能力、原材料和能源消耗、科技活动情况等。
全国性质的普查往往需要耗费大量人力物力,人口普查、农业普查是每10年一次、经济普查是每5年一次,那么能够与之匹配的翔实数据自然也只有普查年份才有。现如今获取数据的方法非常多样,人们要分析数据时所面临的大多不会是数据缺失,而是数据泛滥。而一旦将想要分析的范围放大到一个国家,那么数据往往是珍贵的,且可能有缺失的。所以,我很理解宏观数据的缺失。许多时候,我们分析数据的目的并不是分析数据,而是想要洞察数据背后隐藏的真相。其实我的日常工作中基本接触不到宏观数据,因此很少思考数据分析、分析数据、数据、分析这些词语的差异。当我开始着手搜集梳理宏观数据以后,我开始反思过往,数据分析这件事其实很侧重分析工具,而分析数据这件事则更侧重分析视角,重点都放在了分析,数据既重要又相对不那么重要了。看那些宏观数据的时候,我的心态常常都是略微有点沉重的,同时也开始谨慎地使用分析工具,避免使用魔法而扭曲数据,更多地偏重于展示数据。那个令我疑惑的问题,并没有得到一个确切的答案,只是时时想起,提醒我要警惕对分析工具的倚重、对分析视角的惯性依赖。
耕地面积 🔗
我们国家事实上已经进行了三次全国农业普查,在国家统计局网站能查到部分公开的数据,1996年第一次农业普查,2006年第二次农业普查,2016年第三次农业普查,但是三普数据似乎没有公开全部内容的电子版,只能找到一些主要成果的报告。仅仅只使用这三份数据的话,无法满足我的简单需求,因此还收集了我们国家自然资源局发布的国土调查数据,如第三次全国国土调查、第二次全国土地调查,还有我们国家自然资源部公布的一系列自然资源公报,整理结果如下:
| 统计年度 | 耕地面积(万公顷) | 数据来源 |
|---|---|---|
| 2022 | 12760.1 | 2022年中国自然资源统计公报 |
| 2019 | 12786.19 | 第三次全国国土调查主要数据公报 |
| 2016 | 13492.09 | 2017中国土地矿产海洋资源统计公报、第三次全国农业普查主要数据公报 |
| 2015 | 13499.87 | 2017中国土地矿产海洋资源统计公报、2016中国国土资源公报 |
| 2014 | 13505.73 | 2017中国土地矿产海洋资源统计公报、2016中国国土资源公报、2015中国国土资源公报 |
| 2013 | 13516.34 | 2017中国土地矿产海洋资源统计公报、2016中国国土资源公报、2015中国国土资源公报、2014中国国土资源公报 |
| 2012 | 13515.84 | 2017中国土地矿产海洋资源统计公报、2016中国国土资源公报、2015中国国土资源公报、2014中国国土资源公报、2013中国国土资源公报 |
| 2011 | 13523.86 | 2016中国国土资源公报、2015中国国土资源公报、2014中国国土资源公报、2013中国国土资源公报 |
| 2010 | 13526.83 | 2015中国国土资源公报、2014中国国土资源公报、2013中国国土资源公报 |
| 2009 | 13538.46 | 2014中国国土资源公报、2013中国国土资源公报 |
| 2008 | 12171.6 | 2008中国国土资源公报 |
| 2007 | 12173.52 | 2008中国国土资源公报、2007中国国土资源公报 |
| 2006 | 12177.59 | 2008中国国土资源公报、2006中国国土资源公报 |
| 2005 | 12208.27 | 2008中国国土资源公报、2005中国国土资源公报 |
| 2004 | 12244.43 | 2008中国国土资源公报 |
| 2003 | 12339.22 | 2008中国国土资源公报、2003中国国土资源公报 |
| 2002 | 12593 | 2008中国国土资源公报、2002中国国土资源公报 |
| 2001 | 12761.58 | 2008中国国土资源公报、2001中国国土资源公报 |
其中,2008年的耕地面积12171.6万公顷是根据当年国土资源公报公布的18.2574亿亩除以15换算得到。需要注意的是,在2013年12月30日公布的第二次全国国土调查主要数据公报中提及,2008-2009年耕地面积数据大幅变化的原因在于统计口径有调整。
二次调查数据显示,2009年全国耕地13538.5万公顷(203077万亩),比基于一次调查逐年变更到2009年的耕地数据多出1358.7万公顷(20380万亩),主要是由于调查标准、技术方法的改进和农村税费政策调整等因素影响,使二次调查的数据更加全面、客观、准确。
查看绘图的数据和 R 代码
library(echarts4r)
data <- data.frame(
year = c(
2022,
2019,
2016,
2015,
2014,
2013,
2012,
2011,
2010,
2009,
2008,
2007,
2006,
2005,
2004,
2003,
2002,
2001
),
value = c(
12760.1,
12786.19,
13492.09,
13499.87,
13505.73,
13516.34,
13515.84,
13523.86,
13526.83,
13538.46,
12171.6,
12173.52,
12177.59,
12208.27,
12244.43,
12339.22,
12593,
12761.58
)
)
data |>
e_chart(year) |>
e_bar(value, name = '耕地面积', color = '#58A449FF') |>
e_x_axis(
type = 'category',
axisLabel = list(interval = 0),
name = "统计年度",
nameLocation = "center",
nameGap = 30
) |>
e_y_axis(
min = 12000,
max = 13600,
interval = 800,
name = '万公顷',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE)
) |> e_labels(
show = TRUE,
rotate = 90,
align = "left",
verticalAlign = "middle",
position = "insideBottom",
rich = list(name = list())
) |> e_title(
subtext = '注意:纵轴的起点为12000万公顷(18亿亩)',
top = '4%',
right = '10%',
subtextStyle = list(fontWeight = 'bolder')
)
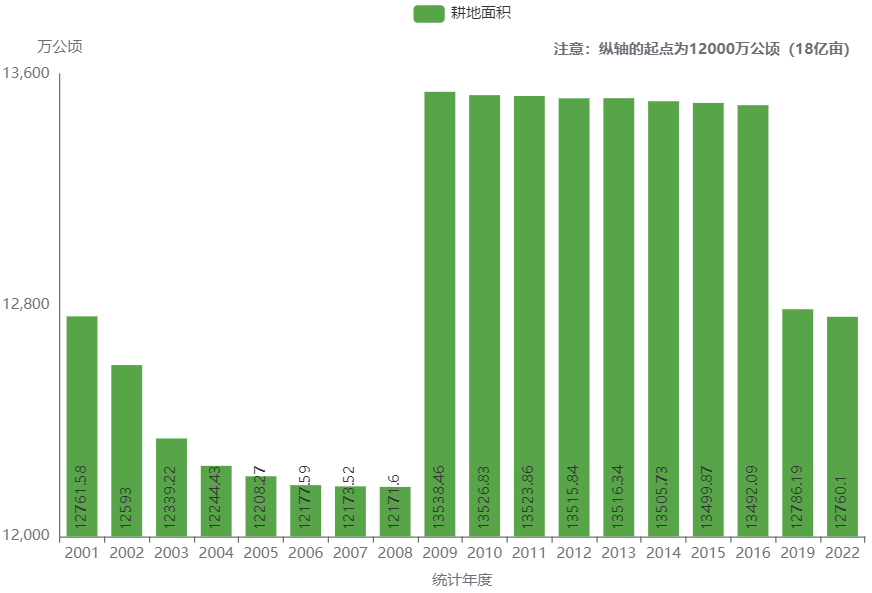
即便在2009年有过口径调整,但2001-2008和2009年以后的耕地面积变化趋势也符合我最初的印象,耕地在流失。讲真,最初搜集完这份耕地面积的数据后,我心里第一反应是产生了一点阴谋论的想法,照着2001-2008年的数据变化趋势,18亿亩(12000万公顷)的耕地红线没几年就会守不住了,心底里便止不住地怀疑修改统计口径的背后动因。不过我又想起了三水曾经说的一句话,大意就是如果有些事我不会昧着良心去做的话,那么就假定别人也不会那么做。这样想好像有点天真,但其实有一个很大的好处。对我来说,做数据分析是要“大胆假设、小心求证”的,可是一旦我脑子里充斥着那些阴谋论的想法,很快就会变成“大胆猜疑、不想求证”了,之所以会变得“不想求证”,大概是因为被阴谋论的想法吞噬以后,立马会幻想着混沌之中存在着一股无法对抗的模糊力量,脑子里也会被进一步幻想出来的重重阻碍吓退。所以呀,在数据分析这件事上,保留一点天真,也许就刚刚好不会被洞悉的部分真相遮蔽心眼,能继续做到尽量去求证,去伪求真。
留守人口 🔗
我想验证的两点印象是农民进城、农村留守人口结构有变化,因此主要搜集了以下三份数据。
- 其一,根据2016年第三次全国农业普查主要数据公报,表5-1农业生产经营人员数量,单位为万人。
| 2016 | 全国 | 东部地区 | 中部地区 | 西部地区 | 东北地区 |
|---|---|---|---|---|---|
| 农业生产经营人员 | 31422 | 8746 | 9809 | 10734 | 2133 |
| 按性别划分农业生产经营人员数量 | |||||
| 男性 | 16494 | 4581 | 5162 | 5593 | 1158 |
| 女性 | 14927 | 4165 | 4647 | 5140 | 975 |
| 按年龄划分农业生产经营人员数量 | |||||
| 年龄35岁及以下 | 6023 | 1537 | 1765 | 2347 | 375 |
| 年龄36-54岁 | 14848 | 3894 | 4674 | 5217 | 1063 |
| 年龄55岁及以上 | 10551 | 3315 | 3370 | 3170 | 695 |
- 其二,根据2006年第二次全国农业普查资料汇编,第二部分 各地区农业生产者和农业从业人员 一、合计 2-1-7各地区农业从业人员数量、 2-1-9各地区按性别分的住户农业从业人员数量、2-1-11各地区按年龄分的住户农业从业人员数量,单位为人。
| 2006 | 全国 | 东部地区 | 中部地区 | 西部地区 | 东北地区 |
|---|---|---|---|---|---|
| 农业从业人员 | 344000134 | 93523780 | 101080394 | 122170424 | 27225536 |
| 按性别划分住户农业从业人员 | 342463995 | 93189942 | 100987949 | 121977083 | 26309021 |
| 男性 | 160412772 | 41875053 | 46156262 | 59286973 | 13094484 |
| 女性 | 182051223 | 51314889 | 54831687 | 62690110 | 13214537 |
| 按年龄划分住户农业从业人员 | |||||
| 20岁以下 | 18224674 | 3890375 | 4899243 | 7754894 | 1680162 |
| 21-30岁 | 51179041 | 12576228 | 13965714 | 20105657 | 4531442 |
| 31-40岁 | 82761216 | 20507933 | 24730185 | 30835861 | 6687237 |
| 41-50岁 | 78985149 | 23373971 | 23774932 | 25189993 | 6646253 |
| 51-60岁 | 72829640 | 21824037 | 22093692 | 23803911 | 5108000 |
| 60岁以上 | 38484275 | 11017398 | 11524183 | 14286767 | 1655927 |
- 其三,根据国家统计局提供的全国人口数据。
| 指标 | 2016年 | 2006年 |
|---|---|---|
| 年末总人口(万人) | 139232 | 131448 |
| 男性人口(万人) | 71307 | 67728 |
| 女性人口(万人) | 67925 | 63720 |
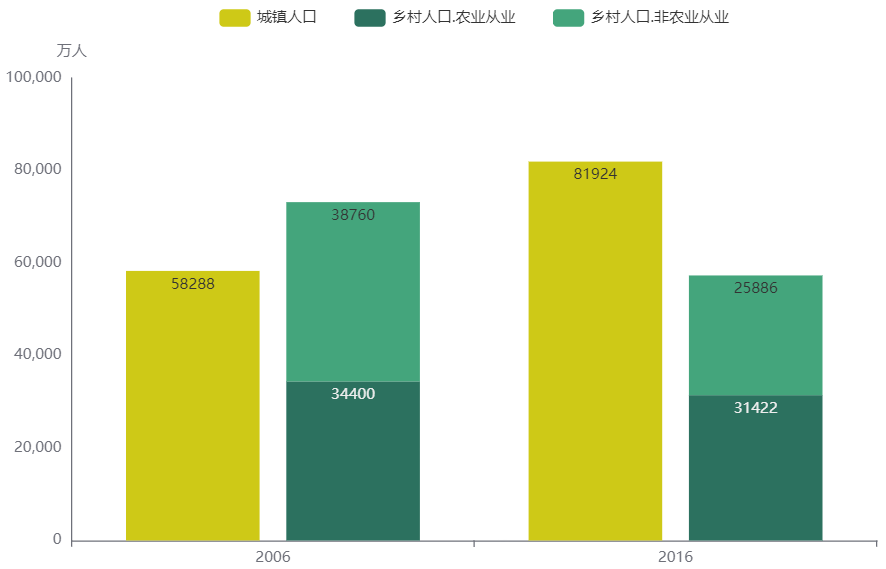
| 城镇人口(万人) | 81924 | 58288 |
| 乡村人口(万人) | 57308 | 73160 |
| 0-34岁 | 527598 | 568971 |
| 35-54岁 | 377446 | 396836 |
| 55岁及以上 | 252976 | 226859 |
| 0-19岁 | 254260 | 325303 |
| 20-29岁 | 185765 | 150270 |
| 30-39岁 | 168058 | 207350 |
| 40-49岁 | 199353 | 192277 |
| 50-59岁 | 157246 | 158884 |
| 60岁以上 | 193338 | 158582 |
-
其四,在使用以上三份数据时,有三点需要注意:
- 在2006年的普查资料中,农业从业人员分为住户农业从业人员和农业生产经营单位农业从业人员,而按性别、年龄划分的都是住户农业从业人员。
- 第三次和第二次全国农业普查对四大地区1的划分保持一致。
- 2006年、2016年并非全国人口普查年份,全国人口数据实为年度人口抽样调查推算数据。
2006年,全国总人口是131448万人,2016年,全国总人口是139232万人。在这十年时间里,相对13亿人的基数,全国总人口的增幅不算大,仅6%,其中城镇人口增加了40%,乡村人口减少了21%,这当然是由于乡村人口向城镇人口的迁移造成的。在2016年,有31422万乡村人口在农村从事农业生产,也有25886万乡村人口没有留在农村从事农业,这就是庞大的进城务工的农民工人队伍,其中就包括我的父母亲族。
查看绘图的数据和 R 代码
data1 <- data.frame(
year = c(2016, 2006),
`全国总人口` = c(139232,131448),
`城镇人口` = c(81924,58288),
`乡村人口` = c(57308,73160),
`乡村人口.农业从业` = c(31422,34400),
`乡村人口.非农业从业` = c(25886,38760))
data1 |>
e_charts(year) |>
e_bar(`城镇人口`, color = '#CEC917FF') |>
e_bar(`乡村人口.农业从业`, stack = 'grp', color = '#2C715FFF') |>
e_bar(`乡村人口.非农业从业`, stack = 'grp', color = '#44A57CFF') |>
e_x_axis(type = 'category') |>
e_labels(position = 'insideTop') |>
e_y_axis(
name = '万人',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE)
) |>
e_legend(itemGap = 30)
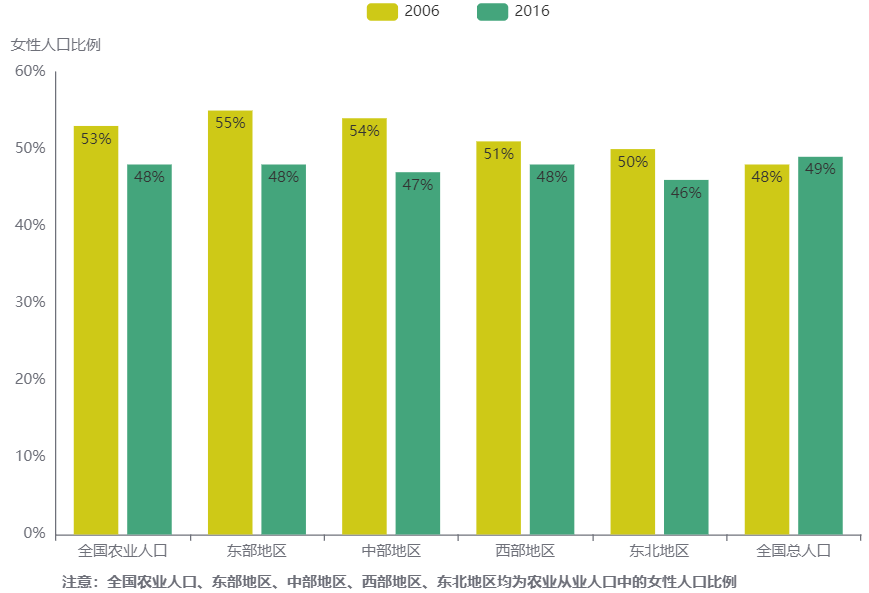
在农村出生长大的人,留在农村无法生存下去,为谋生路便要去城市里打工。农民进城务工,若农民的孩子、父母无法一起进城生存,那么多半仍然留守农村,这便形成了农村留守人口的问题。由于没有找到2016年第三次农业普查资料汇编的电子版,因此暂时无法从性别和年龄结构的交叉维度上对比2006年和2016年的数据。从下图可以看出,农业人口中女性人口的比例下降了,但不足以得出农村留守妇女问题有所改变的结论。
查看绘图的数据和 R 代码
library(data.table)
data2 <- data.table(
year = c(rep(2016, 5), rep(2006, 5), 2016, 2006),
area = c(rep(
c('全国农业人口',
'东部地区',
'中部地区',
'西部地区',
'东北地区'), 2
), rep('全国总人口', 2)),
male = c(
16494,
4581,
5162,
5593,
1158,
16041.2772,
4187.5053,
4615.6262,
5928.6973,
1309.4484,
71307,
67728
),
female = c(
14927,
4165,
4647,
5140,
975,
18205.1223,
5131.4889,
5483.1687,
6269.011,
1321.4537,
67925,
63720
)
)
data2[, ':='(female_prob = round(female / (female + male), 2) * 100)] |>
group_by(year) |>
e_charts(area) |>
e_bar(female_prob) |>
e_x_axis(type = 'category') |>
e_color(color = c('#CEC917FF', '#44A57CFF')) |> #设置调色盘
e_y_axis(
name = '女性人口比例',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
formatter = '{value}%'
) |>
e_legend(itemGap = 30)|>
e_labels(position = 'insideTop', formatter = '{@[1]}%')|>
e_title(
subtext = '注意:全国农业人口、东部地区、中部地区、西部地区、东北地区均为农业从业人口中的女性人口比例',
bottom = '4%',
left = '10%',
subtextStyle = list(fontWeight = 'bolder')
)
需要事先说明的是,2006年和2016年的普查数据对年龄结构的划分不一致,2006年农普数据的年龄结构分为20岁以下/21-30岁/31-40岁/41-50岁/51-60岁/60岁以上,2016年农普数据的年龄结构分为35岁及以下/36-54岁/55岁及以上。而国家统计局在人口年龄结构的划分方式是0-4岁/5-9岁……,如此每5岁划分一档,于是对照2006年只能分为0-19岁/20-29岁/30-39岁/40-49岁/50-59岁/60岁以上,对照2016年也只能分为0-34岁/35-54岁/55岁及以上,稍有错位,但为了比较之便,依然把农普数据和全国人口数据放在一起,并且依照农普数据的年龄结构进行展示。
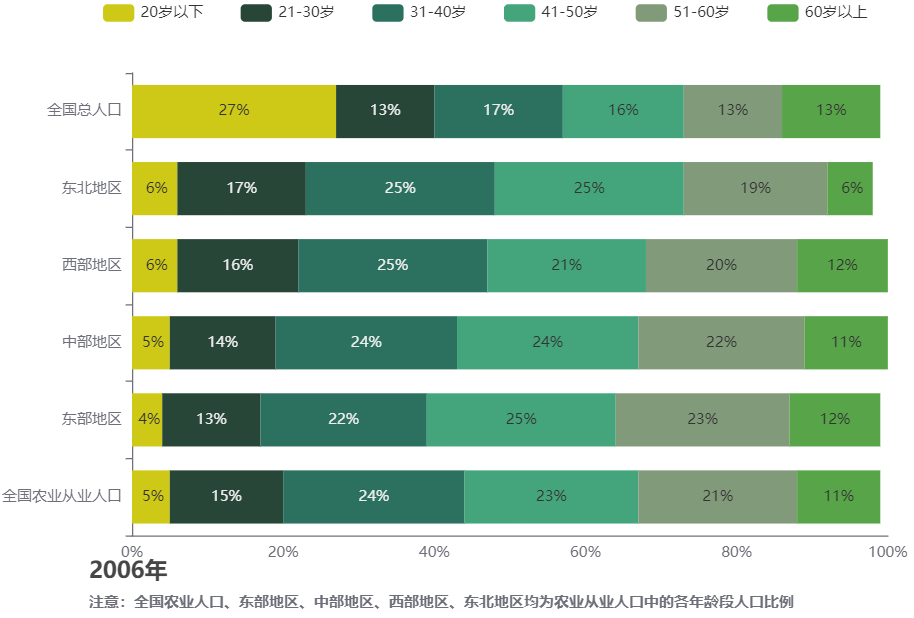
以下是2006年全国总人口与全国农业从业人口、各地区农业从业人口的年龄结构比例图。绘制此图之前,我的印象是2006年的时候农村有大量的留守儿童,那么最小年龄段的人口比例应该较高。绘制此图以后,却发现20岁以下的人口比例意外地低。当然,我第一反应是不是工具(R) 不靠谱,或者数据在从资料里粘贴过来的时候贴错了,于是手动计算核对了一遍,确实没有算错。我忽然想起来,刚上小学的时候,村子里确实是有很多同龄的小孩跟我一起读书,大家都是留守儿童,后来继续读着读着村里同龄的小孩就慢慢变少了。是我,觉得自己是留守儿童,是我,上了大学,于是在分析这个问题的时候,理所当然地以为农村留守儿童们在20岁的时候都跟我一样还在上学……我的表姐表妹表哥表弟们大多都是很早就辍学出去打工了,去年过年我的一位表姐还跟我提过,她读书的时候学习成绩特别好,但是小学毕业以后才12岁就被父母送出去打工了。但这里也不能下结论说,就是因为20岁以下农村人口都出去打工才造成这个年龄段的人口比例远低于全国,因为下图中统计的是农村的农业从业人口,这里并不知晓农村的非农业从业人口的年龄结构数据。
查看绘图的数据和 R 代码
data3.2006 <- data.table(
type = c('全国农业从业人口',
'东部地区',
'中部地区',
'西部地区',
'东北地区',
'全国总人口'),
`20岁以下` = c(1822.4674,
389.0375,
489.9243,
775.4894,
168.0162,
32530.3),
`21-30岁` = c(5117.9041,
1257.6228,
1396.5714,
2010.5657,
453.1442,
15027),
`31-40岁` = c(8276.1216,
2050.7933,
2473.0185,
3083.5861,
668.7237,
20735),
`41-50岁` = c(7898.5149,
2337.3971,
2377.4932,
2518.9993,
664.6253,
19227.7),
`51-60岁` = c(7282.964,
2182.4037,
2209.3692,
2380.3911,
510.8,
15888.4),
`60岁以上` = c(3848.4275,
1101.7398,
1152.4183,
1428.6767,
165.5927,
15858.2)
)
data3.2006[, ':='(prob1 = round(`20岁以下` / (`20岁以下` + `21-30岁` + `31-40岁` + `41-50岁` + `51-60岁` + `60岁以上`),2) * 100,
prob2 = round(`21-30岁` / (`20岁以下` + `21-30岁` + `31-40岁` + `41-50岁` + `51-60岁` + `60岁以上`),2) * 100,
prob3 = round(`31-40岁` / (`20岁以下` + `21-30岁` + `31-40岁` + `41-50岁` + `51-60岁` + `60岁以上`),2) * 100,
prob4 = round(`41-50岁` / (`20岁以下` + `21-30岁` + `31-40岁` + `41-50岁` + `51-60岁` + `60岁以上`),2) * 100,
prob5 = round(`51-60岁` / (`20岁以下` + `21-30岁` + `31-40岁` + `41-50岁` + `51-60岁` + `60岁以上`),2) * 100,
prob6 = round(`60岁以上` / (`20岁以下` + `21-30岁` + `31-40岁` + `41-50岁` + `51-60岁` + `60岁以上`),2) * 100)] |>
e_charts(type) |>
e_bar(prob1,
name = '20岁以下',
stack = 'group',
color = '#CEC917FF') |>
e_bar(prob2,
name = '21-30岁',
stack = 'group',
color = '#274637FF') |>
e_bar(prob3,
name = '31-40岁',
stack = 'group',
color = '#2C715FFF') |>
e_bar(prob4,
name = '41-50岁',
stack = 'group',
color = '#44A57CFF') |>
e_bar(prob5,
name = '51-60岁',
stack = 'group',
color = '#819A7AFF') |>
e_bar(prob6,
name = '60岁以上',
stack = 'group',
color = '#58A449FF') |>
e_labels(position = 'inside', formatter = '{@[0]}%') |>
e_y_axis(
name = '',
max = 100,
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
formatter = '{value}%'
) |>
e_flip_coords() |>
e_title(
text = '2006年',
subtext = '注意:全国农业人口、东部地区、中部地区、西部地区、东北地区均为农业从业人口中的各年龄段人口比例',
bottom = '1%',
left = '10%',
subtextStyle = list(fontWeight = 'bolder')
) |>
e_legend(itemGap = 30) |>
e_grid(left = 120)
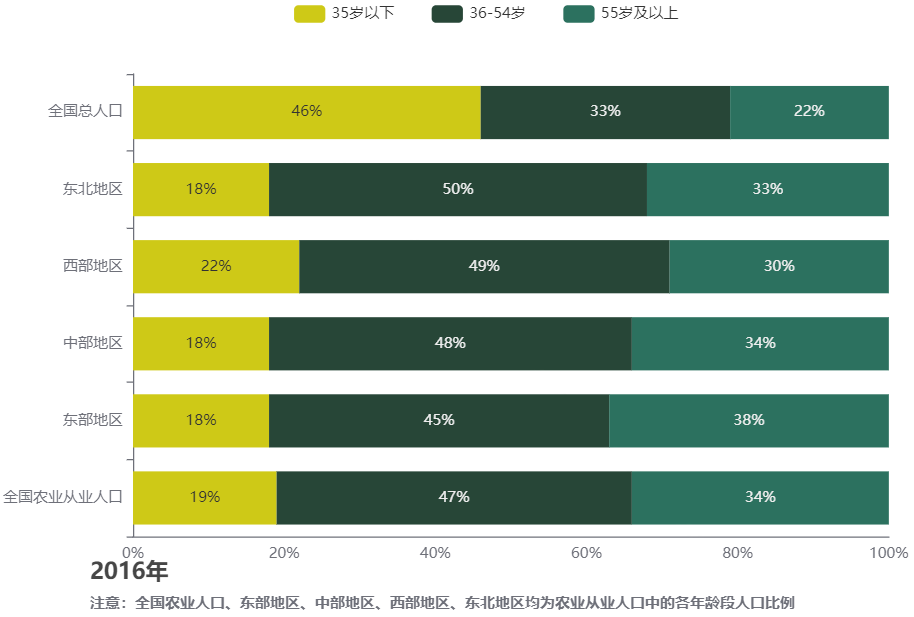
再看2016年的数据,农业从业人口的年龄结构和全国总人口的差异也很大。到这里,我才终于反应过来,2016年农普数据中的“35岁及以下”和2006年农普数据中的“20岁以下”并没有说明这个年龄段的起始年龄,而我拿全国总人口来比对时最小年龄段的起始年龄是0岁。
查看绘图的数据和 R 代码
data3.2016 = data.table(
type = c('全国农业从业人口',
'东部地区',
'中部地区',
'西部地区',
'东北地区',
'全国总人口'),
`年龄35岁及以下` = c(6023,
1537,
1765,
2347,
375,
52759.8),
`年龄36-54岁` = c(14848,
3894,
4674,
5217,
1063,
37744.6),
`年龄55岁及以上` = c(10551,
3315,
3370,
3170,
695,
25297.6))
data3.2016[,':='(
prob1 = round(`年龄35岁及以下` / (`年龄35岁及以下` + `年龄36-54岁` + `年龄55岁及以上` ),2) * 100,
prob2 = round(`年龄36-54岁` / (`年龄35岁及以下` + `年龄36-54岁` + `年龄55岁及以上` ),2) * 100,
prob3 = round(`年龄55岁及以上` / (`年龄35岁及以下` + `年龄36-54岁` + `年龄55岁及以上` ),2) * 100
)]|>
e_charts(type) |>
e_bar(prob1,
name = '35岁以下',
stack = 'group',
color = '#CEC917FF') |>
e_bar(prob2,
name = '36-54岁',
stack = 'group',
color = '#274637FF') |>
e_bar(prob3,
name = '55岁及以上',
stack = 'group',
color = '#2C715FFF') |>
e_labels(position = 'inside', formatter = '{@[0]}%') |>
e_y_axis(
name = '',
max = 100,
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
formatter = '{value}%'
) |>
e_flip_coords() |>
e_title(
text = '2016年',
subtext = '注意:全国农业人口、东部地区、中部地区、西部地区、东北地区均为农业从业人口中的各年龄段人口比例',
bottom = '1%',
left = '10%',
subtextStyle = list(fontWeight = 'bolder')
) |>
e_legend(itemGap = 30) |>
e_grid(left = 120)
最后,这篇博客看起来真是连半成品也算不上的残次品呐。本来以为想要分析的只是极简单的趋势变化,大概两三天就能鼓捣完,没想到在搜集数据这方面有点卡关,在解读数据这方面更加卡关,再加上晚上回去总是忍不住拿起游戏机……就鼓捣了一个星期。唯一的收获是,下次鼓捣人口普查数据时一定要更加谨慎。
-
四大地区:东部地区包括北京市、天津市、河北省、上海市、江苏省、浙江省、福建省、山东省、广东省、海南省。中部地区包括山西省、安徽省、江西省、河南省、湖北省、湖南省。西部地区包括内蒙古自治区、广西壮族自治区、重庆市、四川省、贵州省、云南省、西藏自治区、陕西省、甘肃省、青海省、宁夏回族自治区、新疆维吾尔自治区。东北地区包括辽宁省、吉林省、黑龙江省。 ↩︎