这是一次失败的尝试,整个过程中时常感到题目太大而力所不能及,虽然所得所获甚少,但明白了一个无用的结论——用政府公开的数据不足以分析出党政关系的全貌。之所以仍然要坚持写完这篇文章,这是因为,是因为,因为……为了耕点什么。
数据来源 🔗
根据使用 R 抓取网页数据的方法,可以得到中国政府网公开的政策文件信息,最后会整理成一个结构化数据集,其中包含的一些字段名称及释义如下。
pcode:发文字号。title:标题。summary:摘要。index:索引号。url:网页链接。childtype:主题分类。puborg:发文机关。label:文件类别,分为国务院文件、国务院部门文件、国务院公报1等三种。ptime_date:成文日期。pubtime_date:发布日期。content:文件内容。
本文使用的数据为文件的成文日期截止于2024年7月1日。
library(data.table)
library(echarts4r)
library(DT)
data <- fread('~/gov_zhengce_20240701_content.csv',encoding = 'UTF-8')
#年
data$year <- ifelse(
as.Date(data$ptime_date) == '1970-01-01',
year(data$pubtime_date),
year(data$ptime_date)
)
# 修改因子顺序
data$label <- factor(data$label, levels = c('国务院文件', '国务院部门文件', '国务院公报'))
# 观察主题分类字段,提取\\符号前的内容为主题大类
data$childtype_1 <- sapply(strsplit(
sub("\\\\", "-", data$childtype),
split = "-",
fixed = TRUE
), "[", 1)
成文日期 🔗
这份数据中涉及日期或年份的字段有五个,分别是发文字号、成文日期、发布日期、索引号、网页链接,但是对应的五个年份信息并不完全一致。
-
如下表序号1,发文字号、成文日期、索引号为1984年,发布日期、网页链接为2018年,从文件内容看确实是国务院在1984年给各级人民政府发布通知,而在2018年才正式在网上公开。
-
如下表序号2,发文字号为空,成文日期为1970年,发布日期、索引号、网页链接为2020年,从文件内容看成文日期实际上缺失,而发布的内容是2020的。
-
如下表序号3,发文字号、索引日期为空,成为日期为1970年,发布日期、网页链接为2023年,从文件内容看成文日期实际是2022年,抓取数据时缺失,发布的办法在2023年开始施行。
| 序号 | 发文字号 | 成文日期 | 发布日期 | 索引号 | 网页链接 |
|---|---|---|---|---|---|
| 1 | 国发〔1984〕126号 | 1984-09-20 | 2018-04-17 | 000014349/1984-00023 | http://www.gov.cn/zhengce/zhengceku/2018-04/17/content_5281674.htm |
| 2 | 1970-01-01 | 2020-04-03 | 000014349/2020-00025 | https://www.gov.cn/zhengce/zhengceku/2020-04/03/content_5498472.htm | |
| 3 | 1970-01-01 | 2023-02-10 | http://www.gov.cn/gongbao/content/2023/content_5741254.htm |
若只基于以上观察,暂无法肯定后续应该使用哪个字段的时间信息进行分析,但可以得到一些初步结论。其一,当成文日期缺失时,抓取下来的成文日期被自动填充为1970-01-01。其二,存在成文日期早但公开发布日期晚的情况。
进一步探索分析后,得到两条新线索。其一,发文字号与索引号中包含的年份更加准确,但基本只有国务院文件有索引号,也基本只有国务院文件、国务院部门文件有发文字号,国务院公报既没有发文字号也没有索引号。其二,根据索引号得到的年份,按年汇总得到国务院文件数量的变化趋势,与按成文日期汇总的趋势基本一致,而与按发布日期汇总的趋势差异较大。
综合以上数条线索可知,成文日期更加准确,但需要对自动填充为1970-01-01的部分进行特殊处理。那么,后文涉及日期的分析时均使用成文日期,当成文日期为1970-01-01时替换为发布日期。
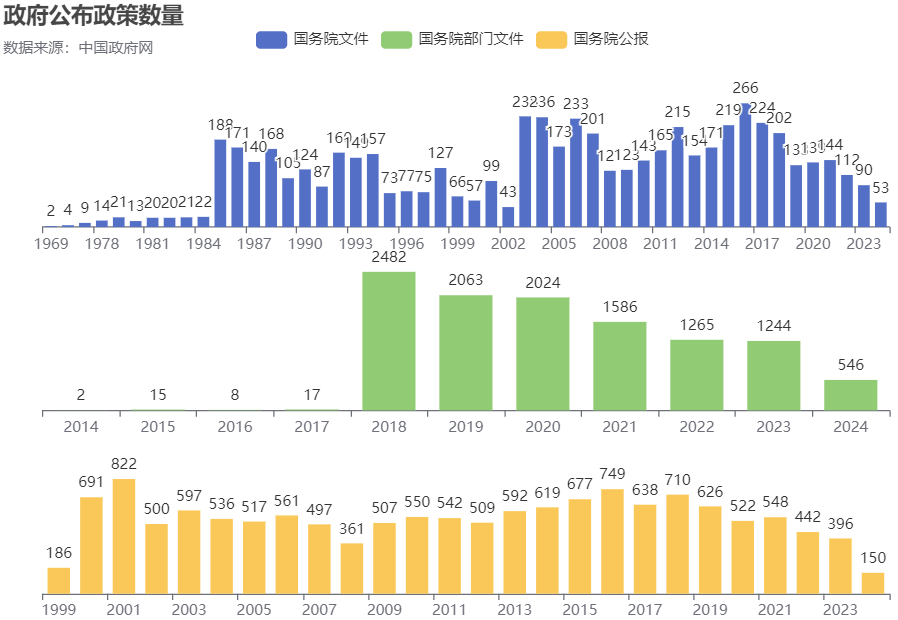
如下按年份汇总文件数量,查看不同文件类别下的变化趋势,可以得到以下几个初步结论。
- 国务院文件,公开文件的成文日期从1969年至今,总体数量上最少。
- 国务院部门文件,虽然公开文件的最早成文日期为2014年,但文件数量的量级开始大幅变化出现在2018年。
- 国务院公报,《国务院公报》是从1955年创办并开始出版,历史公报可查到1954-1966年、1980-1999年的历史存档,这说明在1999年及以前公开的并不是全部,而1999年以后公开的是否齐全也未可知。
查看绘图的 R 代码
data[, by = .(year, label), .(freq = .N)]|>
group_by(label) |>
e_chart(year) |>
e_bar(freq) |>
e_tooltip(trigger = 'axis') |>
e_x_axis(type = 'category') |>
e_y_axis(show = FALSE) |>
e_title(text = '政府公布政策数量',
subtext = '数据来源:中国政府网',
left = 'left') |>
e_legend(top = 20) |>
e_labels(position = 'top') |>
e_facet(
rows = 3,
# 分面的行数
cols = 1,
# 分面的列数
legend_pos = "top",
# 图例的位置
legend_space = 12 # 图例与图形区域之间的距离
)
党和最高领导人的存在 🔗
计算政府公开文件的文本内容中含“党”字的比例,绘制此比例按年变化的趋势图形,见下图中的上半部分。其中,“国务院文件”在1989年含“党”字的比例为0,而“国务院公报”在2007年至2015年含“党”字的比例为0(2006年含“党”字比例为0.18%)。若将此比例为0看做正常,那么可以推导出的结论是“国务院文件”在1989年的公开文件中从来不曾提到任何与党相关的词语,而“国务院公报”在2007年至2015年也是这样。若将此比例为0看做异常,那么可以推导出的结论是“国务院文件”和“国务院公报”所公开的文件并非全部。
查看绘图的 R 代码
data$content_contain <- ifelse(grepl("党", data$content) , "Y", "N")
data$content_contain1 <- ifelse(grepl("毛泽东|邓小平|江泽民|胡锦涛|习近平", data$content) , "Y", "N")
e1 <- data[, by = .(year, label), .(prob1 = round(uniqueN(id[content_contain == 'Y']) /
(.N), 4))] |>
group_by(label) |>
e_charts(year) |>
e_area(prob1) |>
e_tooltip(trigger = 'axis') |>
e_x_axis(type = 'category') |>
e_y_axis(min = 0, max = 1) |>
e_title(text = '政府公布政策文件内容中含“党”字的比例',
subtext = '数据来源:中国政府网',
left = 'left') |>
e_legend(top = 20) |>
e_labels(show = FALSE) |>
e_facet(
rows = 1,
# 分面的行数
cols = 3,
# 分面的列数
legend_pos = "top",
legend_space = 12
)
e2 <- data[, by = .(year, label), .(prob2 = round(uniqueN(id[content_contain1 == 'Y']) /
uniqueN(id[content_contain == 'Y']) , 4))] |>
group_by(label) |>
e_charts(year) |>
e_area(prob2) |>
e_tooltip(trigger = 'axis') |>
e_x_axis(type = 'category') |>
e_y_axis(min = 0, max = 1) |>
e_title(text = '政府公布政策文件内容中,含历届最高领导人姓名除以含“党”字的比例',
subtext = '数据来源:中国政府网',
left = 'left') |>
e_legend(top = 20) |>
e_labels(show = FALSE) |>
e_facet(
rows = 1,
# 分面的行数
cols = 3,
# 分面的列数
legend_pos = "top",
legend_space = 12
)
e_arrange(e1,e2,cols = 1,rows = 2)
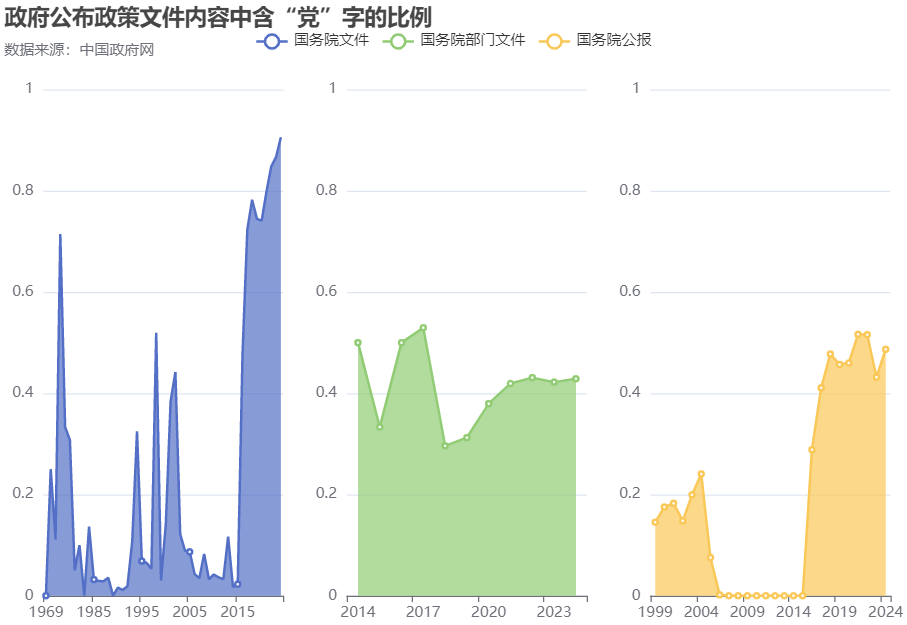
从当前已得的数据来看,政府公开文件中含“党”字的比例总是变化的,在三个文件类别下的共同现象是,此比例近些年均有增长,只是增长开始发生的年份有远近、增长幅度也各有不同。
-
国务院文件,此比例存在多个极值,较大的极值有1978年的71%、1994年的32%、1998年的52%、2002年的44%、2018年的78%、2024年(截止7月1日)的91%,且从2016年开始有大幅度的增长,近几年此比例维持着较高的数值。
-
国务院部门文件,此比例从2018年开始有明显的增长趋势,但整体数值维持在50%以下。
-
国务院公报,此比例从2016年开始有大幅度的增长,其在1999年至2005年的平均值为16.7%,在2016至2024年的平均值为44.9%。
虽然国务院文件、国务院部门文件、国务院公报这三个文件类别各自含有“党”字的比例也有高低之分,但是仅探索到这一步还不能分析出什么,因为还不知道这三种文件有什么差异。
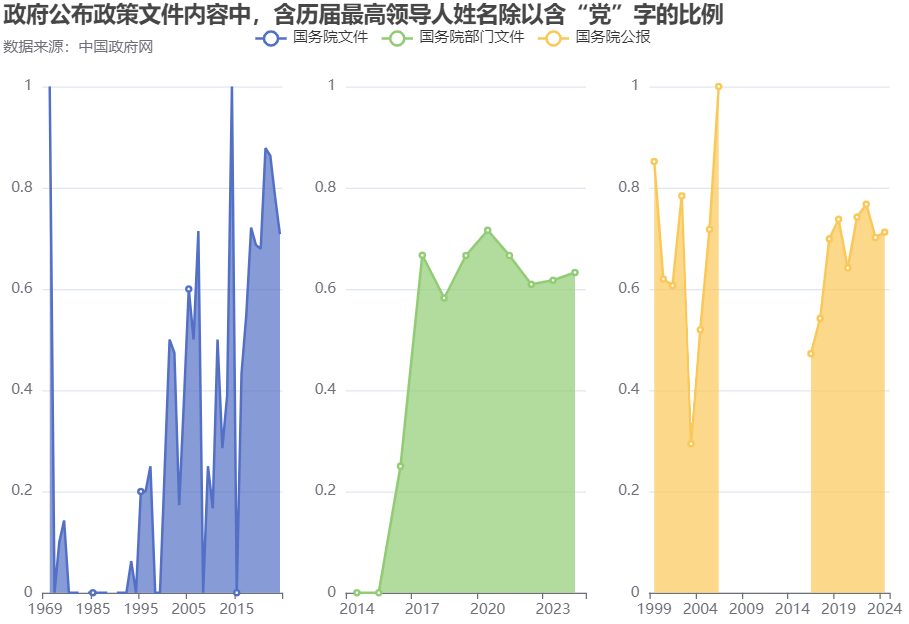
根据政府公开文件的文本内容,进一步计算含历届最高领导人姓名除以含“党”字的比例,绘制此比例按年变化的趋势图形,见上图中的下半部分。若在“国务院部门文件”和“国务院公报”下对比两个比例的数值,会发现下半部分图形中的数值总是更高的,但这也不能清楚地说明什么,还需继续探索。
国务院公报 🔗
在基础数据中新增一个字段——“来源”:把标题或发文机关中含有“中共中央”标记来源为“中共中央”,把标题或发文机关中含有“中央军委”标记来源为“中央军委”,把标题或发文机关中含有“国务院”标记来源为“国务院”,剩下的标记为“其它”。
计算不同来源下各文件类别的比例,发现每种来源中占比最大的文件类别各有不同。
- 中共中央:国务院公报占比超过90%,说明中共中央发文主要是发在国务院公报。
- 中央军委:国务院文件占比超过70%,说明中央军委发文大多是发在国务院文件。
- 国务院:国务院文件占比超过50%;国务院公报占比超过40%,说明国务院极少发文在国务院部门文件上。
查看绘图的 R 代码
# 区分来源
data$source <-
ifelse(
grepl("中共中央", data$title) | grepl("中共中央", data$puborg),
"中共中央",
ifelse(
grepl("中央军委", data$title) | grepl("中央军委", data$puborg),
"中央军委",
ifelse(
grepl("国务院", data$title) | grepl("国务院", data$puborg),
"国务院",
"其它"
)
)
)
data$source <- factor(data$source, levels = c('中共中央', '中央军委', '国务院', '其它'))
#table(data$label, data$source)
dcast(data[, by = .(source, label), .(freq = .N)], label ~ source, value.var = 'freq') |>
e_charts(label) |>
e_pie(`中共中央`, radius = "30%", center = c("30%", "30%")) |>
e_pie(`中央军委`, radius = "30%", center = c("70%", "30%")) |>
e_pie(`国务院`, radius = "30%", center = c("30%", "70%")) |>
e_pie(`其它`, radius = "30%", center = c("75%", "65%")) |>
e_labels(position = 'outside', formatter = '{b}\n{c}, {d}%') |>
e_legend(right='right') |>
e_title(text = '不同来源下各文件类别的比例', subtext = '左上-中共中央;右上:中央军委;\n\n左下:国务院;右下:其它')
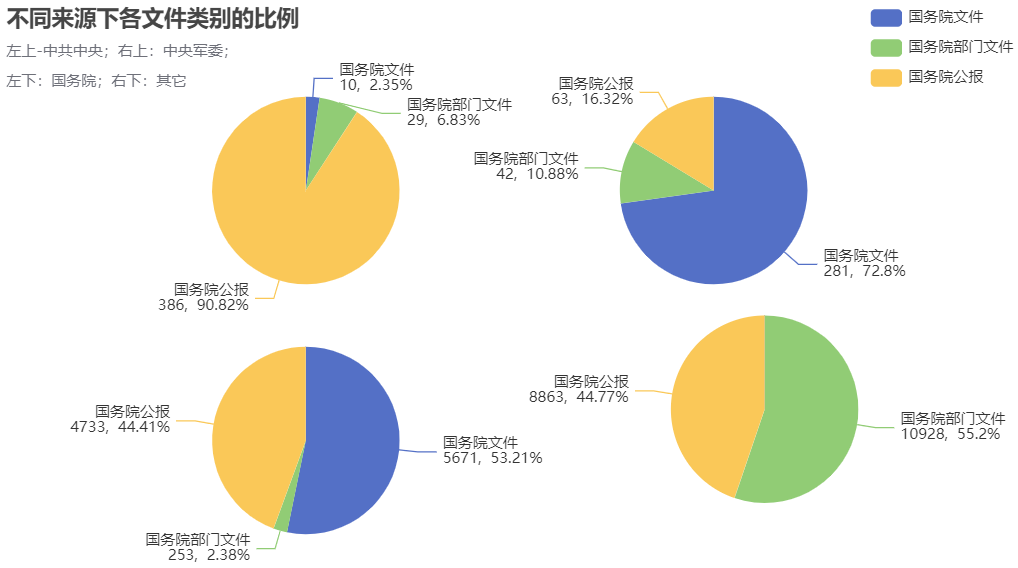
在来源为中共中央的文件中,其标题同时含有“国务院”的比例是93.2%。这说明中共中央发文的特点是,至少在形式上需要联合国务院一起发文,而在文件标题的内容顺序上,都是中共中央在前、国务院在后2。
国务院文件 🔗
在文件类别为“国务院文件”的数据中,按发文机关汇总如下。
| 序号 | 发文机关 | 发布文件数量 |
|---|---|---|
| 1 | 国务院 | 2874 |
| 2 | 国务院、中央军委 | 223 |
| 3 | 国务院办公厅 | 2791 |
| 4 | 国务院办公厅、中央军委办公厅 | 43 |
| 5 | 国务院办公厅秘书局 | 1 |
| 6 | 国务院抗震救灾总指挥部 | 2 |
| 7 | 国务院应对新型冠状病毒感染肺炎疫情联防联控机制 | 12 |
| 8 | 国务院应对新型冠状病毒感染疫情联防联控机制、中央农村工作领导小组 | 1 |
| 9 | 国务院应急管理办公室 | 15 |
| 10 | 中央应对新型冠状病毒感染肺炎疫情工作领导小组 | 5 |
这里将一些职责接近的发文机关名称进行合并,便于后续分析不同发文机关发布文件数量的变化趋势,合并前后的内容如下。
- 国务院,国务院办公厅,国务院办公厅秘书局 -> 国务院
- 国务院、中央军委,国务院办公厅、中央军委办公厅 -> 国务院、中央军委
- 国务院应对新型冠状病毒感染肺炎疫情联防联控机制,国务院应对新型冠状病毒感染疫情联防联控机制、中央农村工作领导小组,中央应对新型冠状病毒感染肺炎疫情工作领导小组 -> 应对新冠疫情
- 国务院抗震救灾总指挥部,国务院应急管理办公室 -> 应急管理
查看绘图的 R 代码
data[, puborg := ifelse(
puborg %in% c("国务院", "国务院办公厅", "国务院办公厅秘书局"),
"国务院",
ifelse(
puborg %in% c("国务院、中央军委", "国务院办公厅、中央军委办公厅"),
"国务院、中央军委",
ifelse(
puborg %in% c(
"国务院应对新型冠状病毒感染肺炎疫情联防联控机制",
"国务院应对新型冠状病毒感染疫情联防联控机制、中央农村工作领导小组",
"中央应对新型冠状病毒感染肺炎疫情工作领导小组"
),
"应对新冠疫情",
ifelse(puborg %in% c("国务院抗震救灾总指挥部", "国务院应急管理办公室"), "应急管理", puborg)
)
)
)][label == '国务院文件', by = .(year, puborg), .(freq = .N)] |>
group_by(puborg) |>
e_charts(year) |>
e_line(freq) |>
e_x_axis(
type = 'value',
min = 1969,
max = 2024,
axisLabel = list(
formatter = htmlwidgets::JS("function(value) { return value.toString().replace(',', ''); }")
)
) |>
e_tooltip(trigger = 'axis') |>
e_y_axis(
show = TRUE,
splitNumber = 3,
axisLabel = list(inside = TRUE, rotate = -90)
) |>
e_title(text = '各发文机关公布政策文件数量',
subtext = '数据来源:中国政府网',
left = 'left') |>
e_legend(top = 20) |>
e_facet(
rows = 4,
# 分面的行数
cols = 1,
# 分面的列数
legend_pos = "top",
# 图例的位置
legend_space = 12 # 图例与图形区域之间的距离
)
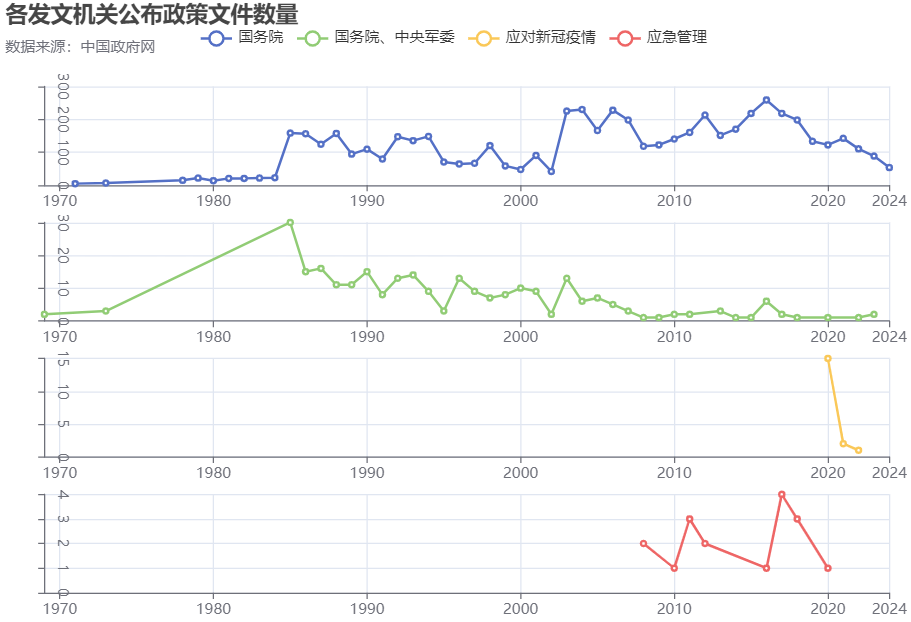
从当前的数据可以观察到,国务院文件主要是由国务院(即最高人民政府)发布的文件,其中包括一部分国务院、中央军委联合发布的文件,而这一类联合发布文件数量从1985年开始减少。至于1985年之前的情况如何,这份公开的数据里没有答案,真正的答案记在别处。
国务院文件涉及的主题大类共有22个,而其中发文机关为国务院、中央军委的涉及主题大类共有14个。在这14个主题大类中,文件数量排名第一的主题大类是工业、交通,主要是对新建民用机场或军民合用机场的批复;排名第二的主题大类是公安、安全、司法,主要涉及武警、军、兵;排名第三的主题大类是国防,主要涉及军队。结合我国党政体制下“党管政府”和“党管军队”的基本原则,可以推断出,政府不是军队的上级,军队不是政府的下级,政府不能直接管理涉及军队的事务,涉及军务的政务需要国务院联合中央军委共同商讨处理。
国务院部门文件 🔗
在文件类别为“国务院部门文件”的数据中,一共出现过437个不同名称的发文机关,若按单个发文机关名称汇总2018年至今的总发文数量,查看其分位数及对应数量,可知在已公开的文件中多数发文机关发文数量极少。
查看 R 代码
# 替换不规则的分隔符为普通空格
data[, puborg := gsub("\u2002|、| |,", " ", puborg)]
# 去掉一些字词,便于后面合并
chars_to_remove <- c("办公厅", "等", "办公室", "和", "综合司", "员会", "国家")
pattern <- paste(chars_to_remove, collapse = "|")
data[, puborg := gsub(pattern, "", puborg)]
# 定义 col_split_count 函数
col_split_count <- function(dt, year) {
dt[, col_split := strsplit(puborg, " ")]
dt_long <- dt[, .(col_split = unlist(col_split)), by = .(id)]
dt_long[, .(count = .N), by = .(col_split)]
}
# 应用 col_split_count 函数并合并结果
years <- 2018:2024
puborg_data_list <- lapply(years, function(y) {
dt <- col_split_count(data[label == '国务院部门文件' & year == y], y)
dt[, year := y]
dt
})
puborg_data <- rbindlist(puborg_data_list)
rm(puborg_data_list)
quantile(puborg_data[, by = .(col_split), .(freq = sum(count))]$freq, probs = seq(0, 1, 0.1))
## 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
## 1.0 1.0 1.0 1.0 1.0 2.0 3.0 8.0 17.0 64.6 1829.0
再看每年公布政策文件数量排名前五的发文机关,“财政部”很自然地突出。这点很符合普通国民的常态认知,政府要发展、要改革或者施行新政,总离不开财政的支撑。
查看绘图的 R 代码
puborg_data[, rank := rank(-count, ties.method = "first"), by = year][rank <= 5] |>
e_charts(year) |>
e_scatter(
serie = count,
size = count,
bind = col_split,
itemStyle = list(opacity = 0.8),
scale_js = "function(data){ return 12*(Math.sqrt(data[2]) + 0.1);}"
) |>
e_x_axis(
type = 'category',
name = '发文年份',
nameLocation = 'center',
nameGap = 20
) |>
e_y_axis(name = '发文数量',
nameLocation = 'center',
nameGap = 30) |>
e_labels(
position = 'inside',
formatter = '{b}',
labelLayout = list(moveOverlap = 'shiftY')
) |>
e_title(text = '各发文机关每年公布政策文件数量-排名前五',
subtext = '数据来源:中国政府网',
left = 'left') |>
e_legend(show = FALSE)
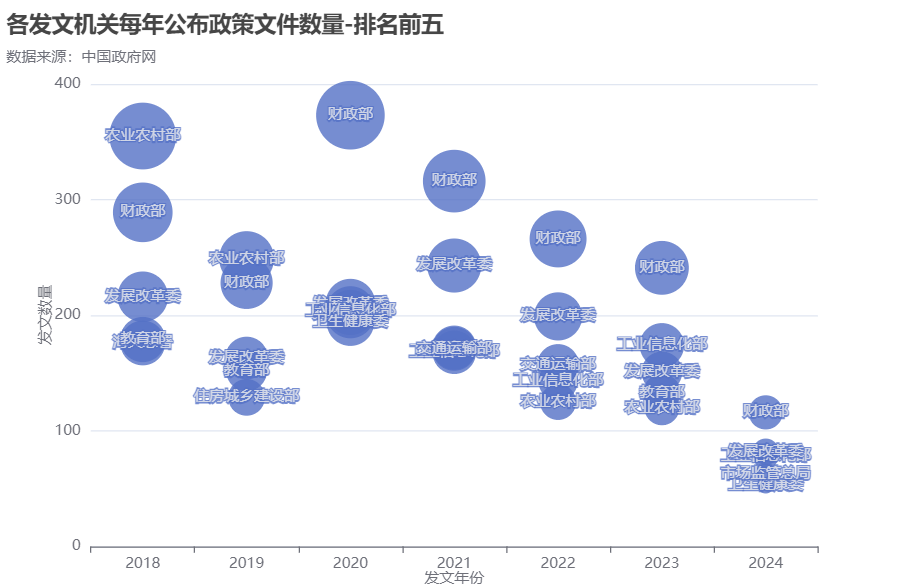
财政支持分轻重 🔗
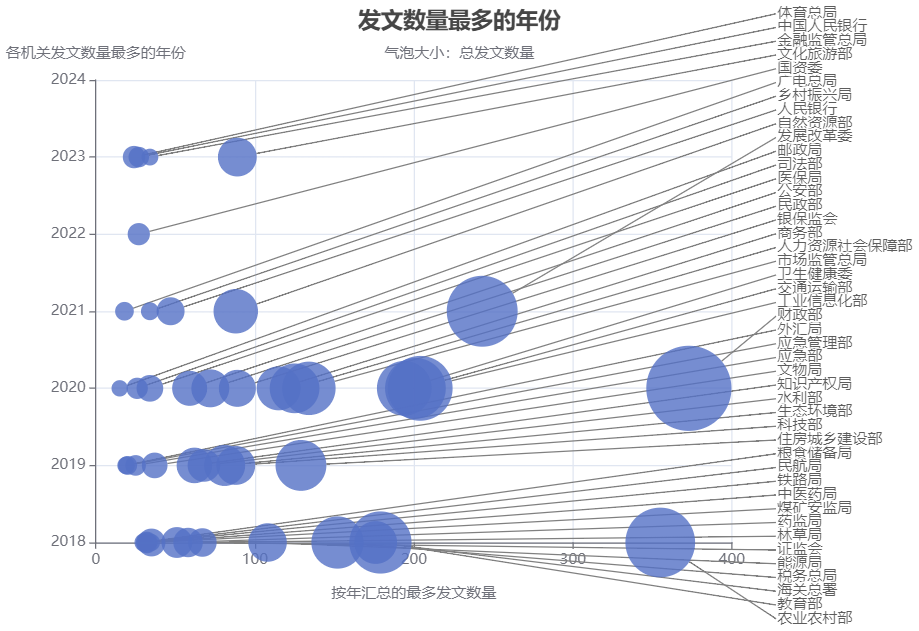
在总发文数量前90%的发文机关中,计算各个发文机关发文数量最多的年份,可以看出较多集中在2018-2020年间,这点符合整体趋势——国务院部门文件总发文数量从2018至今逐年减少。也有在此趋势之外的发文机关,如文化旅游部、体育总局、中国人民银行、金融监管总局,此四类机关至今发文数量最多的年份在2023年。
查看绘图的 R 代码
# 每年发文数量最多的机关
result <- puborg_data[, .SD[which.max(count)], by = year]
# 计算每个 str 数量最大的年份及其对应的数量
max_year_count <- puborg_data[, .(year = year[which.max(count)], max_count = max(count)), by = col_split]
# 计算总数
sum_all <- puborg_data[, by = .(col_split), .(freq = sum(count))]
sum_all[max_year_count, on = .(col_split)][freq >= 60][order(year)] |>
e_charts(max_count) |>
e_scatter(
serie = year,
size = freq,
bind = col_split,
itemStyle = list(opacity = 0.8),
scale_js = "function(data){ return 5*(Math.sqrt(data[2]/10) + 0.1);}",
label = list(show = TRUE, formatter = '{b}'),
labelLayout = list(x = "85%", moveOverlap = "shiftY"),
labelLine = list(show = TRUE, lineStyle = list(color = "gray")),
emphasis = list(focus = "self")
) |>
e_y_axis(
type = 'value',
min = 2018,
max = 2024,
name = '各机关发文数量最多的年份',
axisLabel = list(
formatter = htmlwidgets::JS("function(value) { return value.toString().replace(',', ''); }")
)
) |>
e_x_axis(name = '按年汇总的最多发文数量',
nameLocation = 'center',
nameGap = 35) |>
e_tooltip(
padding = 5,
borderWidth = 1,
trigger = "item",
formatter = htmlwidgets::JS(
"function(params){
return('<strong>发文机关:' + params.name +
'</strong><br />按年汇总的最多发文数量: ' + params.value[0] +'次'+
'<br />发文数量最多年份: ' + params.value[1] +'年'+
'<br />总发文数量: ' + params.value[2] +'次')}"
)
) |>
e_title(text = '发文数量最多的年份',
subtext = '气泡大小:总发文数量',
left = 'center') |>
e_legend(show = FALSE) |>
e_grid(left = '10%', right = '20%')
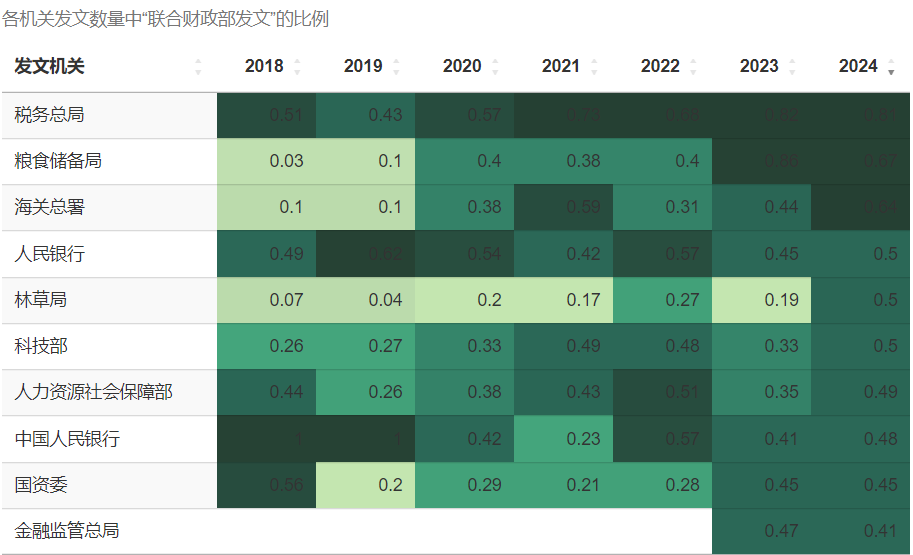
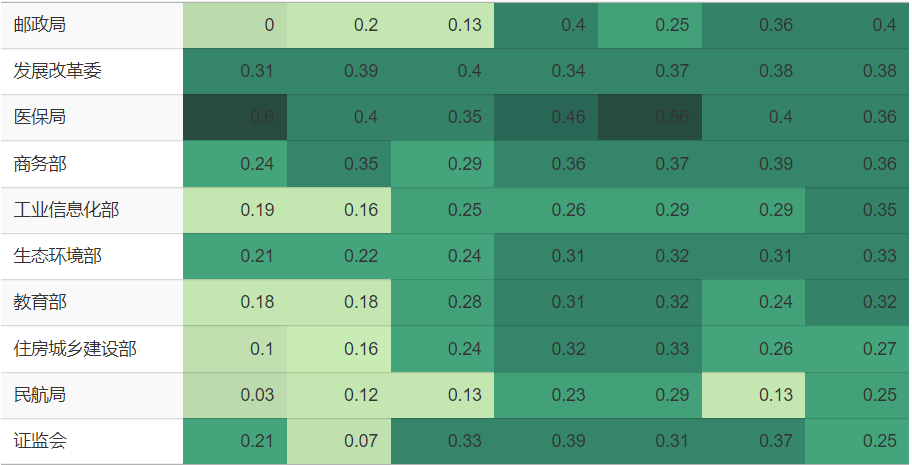
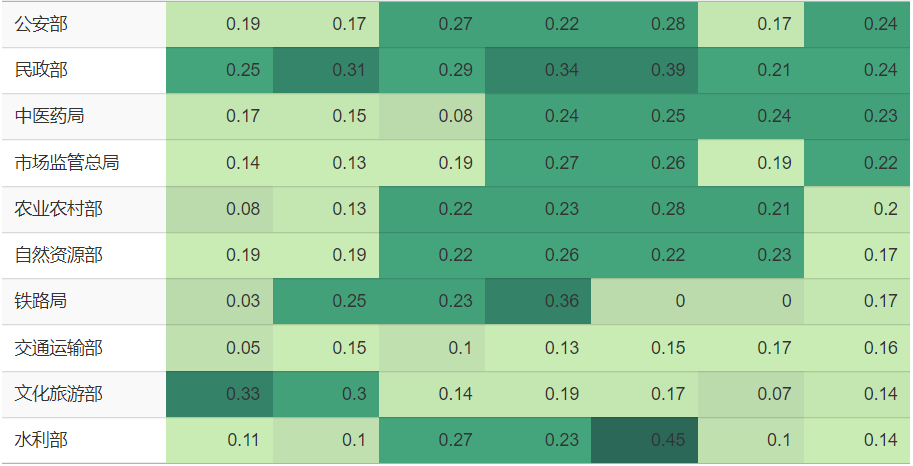
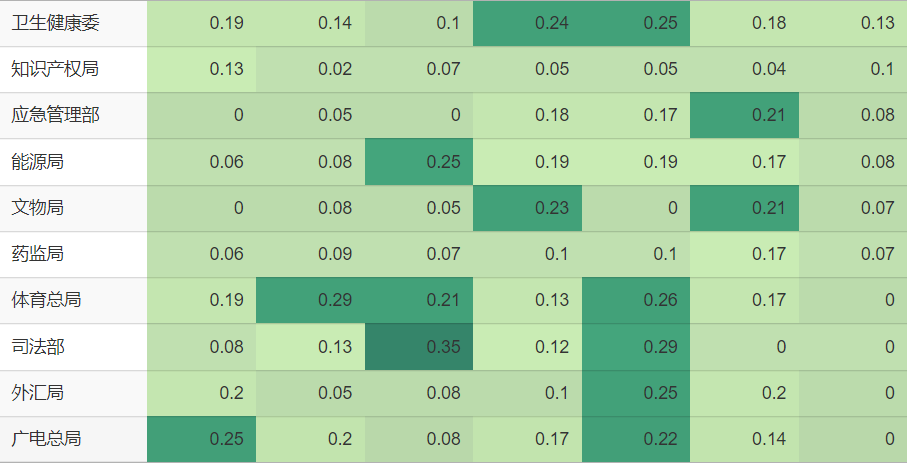
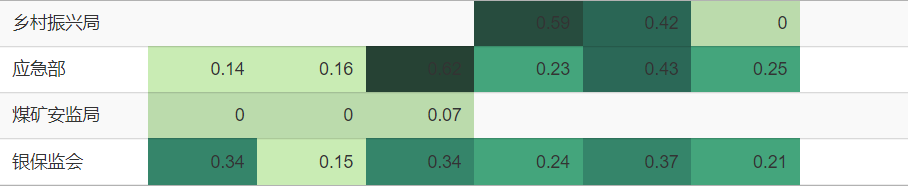
若再进一步探究各发文机关发布的政策文件中“联合财政部发文”的比例变化,仅以此衡量财政部对各机关的支持,也有轻重之分。但这轻重之别也并不固定,孰轻孰重是随时间起伏变化的。下表中,用单元格填充颜色由浅入深来代表“联合财政部发文”的比例由小到大,7种颜色分别对应由0.1、0.2、0.3、0.4、0.5、0.6这6个数字来划分的区间。比如粮食储备局,从2018年至今其“联合财政部发文”的比例逐年升高,其单元格颜色从左至右逐渐加深。又比如乡村振兴局,前身为国务院扶贫开发领导小组办公室,于2021年成立为单设的副部级国家局,在完成扶贫攻坚的历史任务后,又于2023年重新并入农业农村部,其单元格颜色从左至右先加深后变浅。
查看绘图的 R 代码
# 需要计算总发文数量排名前90%的发文机关
departments <- sum_all[freq >= 60, col_split]
# 对每个部门进行计算,但不直接修改 puborg 列,最后合并结果时通过 dept 区分
result_list <- lapply(departments, function(dept) {
data[label == '国务院部门文件' &
puborg %like% dept, by = year, # 只按年份分组
.(
freq1 = .N, # 各部门发文数量
freq2 = uniqueN(id[puborg %like% '财政']), # 联合财政的发文数量
prob = round(uniqueN(id[puborg %like% '财政']) / (.N), 2)
)][, department := dept] # 计算后添加部门列
})
# 将所有部门的结果合并
combined_data <- rbindlist(result_list)
quantile(combined_data$prob, probs = seq(0, 1, 0.1))
datatable(
dcast(combined_data[year >= 2018 &
!(department == '财政部')], department ~ year, value.var = 'prob'),
rownames = FALSE,
colnames = c('发文机关', 2018:2024),
caption = '各机关发文数量中“联合财政部发文”的比例',
options = list(
dom = 'tp',
order = list(7, 'desc')
)
) |>
formatStyle('2018', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))|>
formatStyle('2019', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))|>
formatStyle('2020', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))|>
formatStyle('2021', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))|>
formatStyle('2022', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))|>
formatStyle('2023', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))|>
formatStyle('2024', backgroundColor = styleInterval(
c(0.1, 0.2, 0.3,0.4,0.5, 0.6),
c('#c0e0b0',"#c9ecb4",'#44A57C','#35856A','#2B6857','#284E3F','#264234')
))
政务主题分大小 🔗
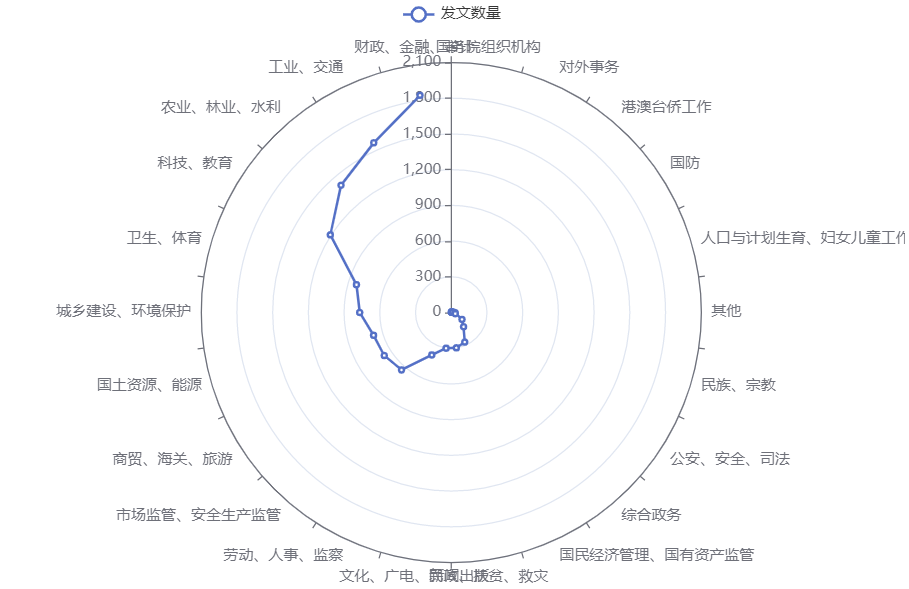
仅以主题大类汇总发文数量,最少的前五个类别分别是国务院组织机构、对外事务、港澳台侨工作、国防、人口与计划生育妇女儿童工作。其中,对外事务和国防两个主题大类自2021年起发文数量为0,这说明此两类主题的文件可能没有全部公布,或者不是公布在国务院部门文件之中,或者此两类主题的政务本身就不由国务院的部门来处理。
查看绘图的 R 代码
data[label == '国务院部门文件',by=.(childtype_1),.(freq=.N)][is.na(childtype_1)==FALSE][order(freq)]|>
e_charts(childtype_1) |>
e_polar() |>
e_angle_axis(childtype_1) |>
e_radius_axis() |>
e_line(freq, name = "发文数量", coord_system = "polar")
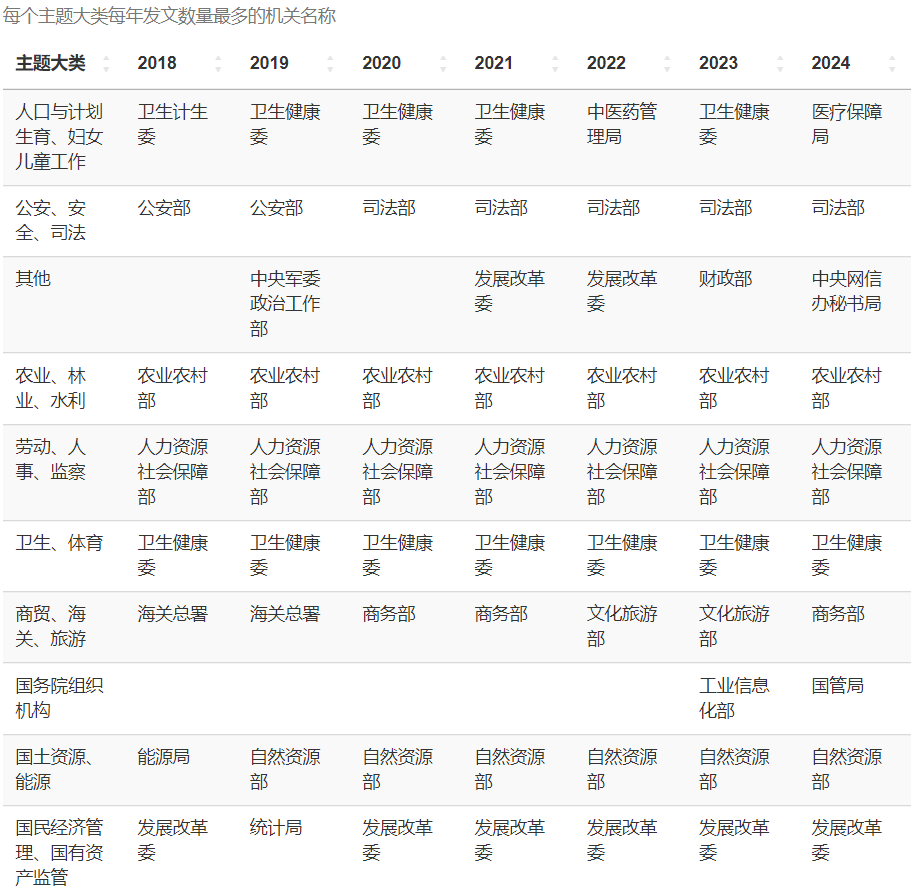
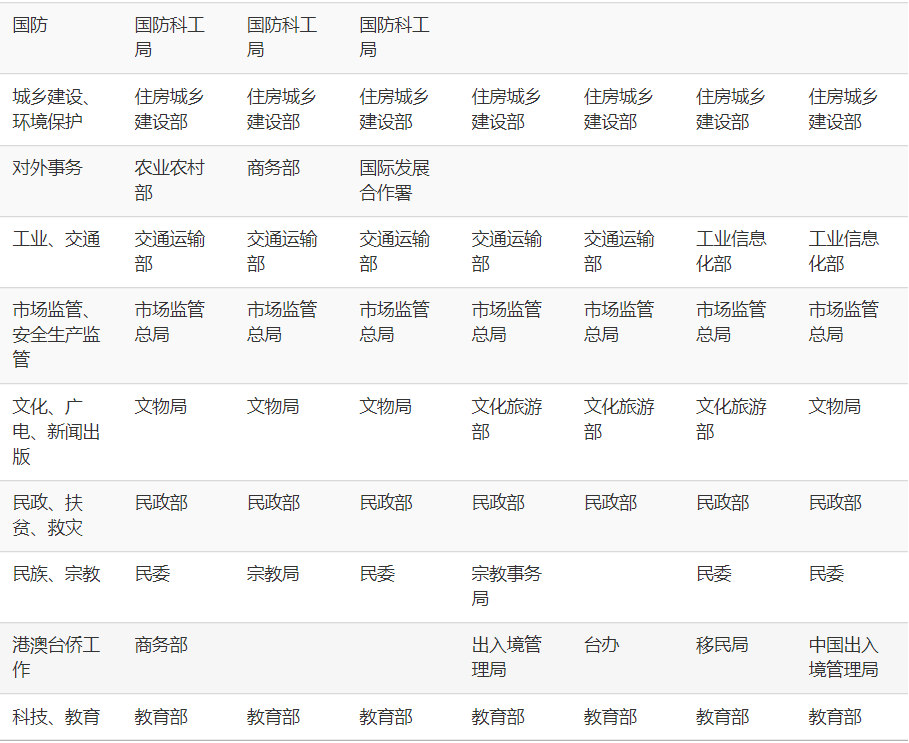
普通民众无从知晓各个机关部门之间的权力交迭如何变化,若只是观察每个主题大类每年发文数量最多的机关名称,可以得知有些主题大类下发文最多的机关没有改变,而有些有过改变。比如在“公安、安全、司法”这一主题大类下,2018至2019年是公安部发文最多,而2020年至今是司法部发文最多。又比如在“工业、交通”这一主题大类下,2018至2022年是交通运输部发文最多,而其后是工业信息化部发文最多。
查看绘图的 R 代码
# 拆分发文机关列
n <- nrow(data[label == '国务院部门文件'])
childtype_data <- data[label == '国务院部门文件'][, list(
childtype_1 = rep(childtype_1, lengths(puborg)),
year = rep(year, lengths(puborg)),
puborg = unlist(strsplit(puborg, " "))
), by = 1:n]
# 计算每个主题大类和年份的发文机关数量
dt_count <- childtype_data[year>=2018, .N, by = .(childtype_1, year, puborg)]
# 选择每个主题大类和年份中数量最多的发文机关
dt_max <- dt_count[dt_count[, .I[N == max(N)], by = .(childtype_1, year)]$V1]
dt_max_dcast <- dcast(
dt_max,
childtype_1 ~ year,
value.var = c('puborg'),
fun.aggregate = max
)
colnames(dt_max_dcast)[1] <-"主题大类"
datatable(
dt_max_dcast[is.na(`主题大类`) == FALSE],
rownames = FALSE,
options = list(pageLength = 20, dom = 't'),
caption = '每个主题大类每年发文数量最多的机关名称'
)
延伸 🔗
在陈明明与李松两位老师写的这篇当代中国党政体制的沿革:路径与逻辑中,有这样几段文字,摘录如下。
中国党政体制改革所欲达致的理想制度形态是“党的领导、人民当家作主和依法治国的有机统一”,即在三者之间建立相对独立而又相互支持的一体化关系。但由于市场经济、社会结构和利益格局及思想观念的多元化复杂化,党政体制的改革实际上一直在两个重心——分权逻辑和集权逻辑之间进行调整,从而显现出两种不同的改革思路及其结果。
至少在改革开放前30年,分权改革是一个大趋势,因为改革开放就是为了克服原有计划体制高度集权的弊端。这见诸邓小平的一系列讲话和党的十三大文献。市场化的分权改革取得了伟大的成就,繁荣了社会,富裕了人民,增强了国家的总体实力。但是毋庸讳言,就前述党政体制的三重特征以及党和国家、社会关系而言,市场化进程一度削弱了党对社会各方面的控制能力,也弱化了党对干部的控制能力……这种情况反映在党的决策部门,就是几届中央领导集体一度面临“多年想做而没有做成的事情”“多年想解决而没有解决的问题”的艰难局面。
党的十八大后,中央领导集体的重大共识是:(1)中国共产党的领导是解决当代中国社会发展问题的唯一方法;(2)改革开放30余年,中国共产党的领导在取得重大成就的同时也面临着严峻的挑战;(3)有必要重新强化中国共产党在中国社会各个领域的领导和调控。党政体制改革回到了集权逻辑的重心。民主的对立面是专制。集权不是民主的对立面,集权的对立面是分权,集权逻辑兴起的直接原因是分权的底限无法适应大型复杂社会的治理。国家治理体系和治理能力现代化并不排斥分权,民主化和法治化的过程也需要分权予以支持。但是,在单一制国家结构和民主集中制政体原则的制度约束下,集权是分权的制度边界,即分权所分之权从根本上说来自中央权力基于有效管辖所需的授予,分权之大和分权之用以不能削弱中央的集中统一领导为前提。因此,在国家治理体系和治理能力现代化的进程中,分权是集权体制为克服自身不足及改善集权效率品质的“调适器”,其本身的推进和实现也依赖集权而存在。在当代中国的政治约束下,集权是通过中国共产党的“集中统一”和“全面领导”体现和实现的。
首先表现为对中国共产党领导制度的重申和强化……
其次表现为对中国共产党政治建设的强化和全力推进……
再次表现为对意识形态工作及其领导权的重视和掌握……
最后表现为对新型政党制度概念的论证和落实……
以上文字简要总结的话就是,党的十八大后,中央的一个重大共识是“要坚持和加强党的全面领导”。这里的全面领导并不只是党对政府的政治领导,对党组织和党员干部的组织领导,还包含在社会文化领域中对群众的思想领导。这个加强领导的逻辑,或许可以用来解释一种数据上的表象:在对中国政府网公开的政策文件的探索之中,在“国务院文件”这个类别下,文件内容中含有“党”字的比例从2016年开始有大幅度的增长,近几年此比例维持着较高的数值,2024年(截止7月1日)此比例达到了91%。而在“国务院部门文件”这个类别下,尽管文件内容中含有“党”字的比例也从2018年开始有增长趋势,但此比例并未超过50%,可以解释这一数据表象的逻辑可能是,强化领导和调控并不等于全部控制,发挥国家治理效能仍然需要政府在既定的制度框架之内能够有限度地独立运行。
在三个文件类别下,内容含有“党”字的文件里面含有历届最高领导人名字的比例数值都较大,2024年(成文日期截止7月1日)“国务院文件”中此比例为71%、“国务院部门文件”中此比例为63%、“国务院公报”中此比例为71%。这一数据表象可能是一种偶然,也可能是一种存在因果逻辑的必然(PS这句真不是废话)。抓取下来的数据在许多年份极有可能都存在缺失,但因何原因造成的缺失不可知,无法确认2018年至今的数据是否也存在缺失,因而是否偶然是不确定的。
若是非要强行从必然的角度去解释什么因果逻辑,可以这样推理一番3。
-
改革开放三十年使得市场经济繁荣,市场化进程弱化了党对组织干部和社会各方面的控制的能力,而党的十八大后中央要加强党的全面领导就是将分出去的权力重新集中,这种转变若要真正从上到下都实践起来,需要最高领袖本身就拥有最高级别的专断决策权力,这样从上至下的各层级政府官僚才会执行转变的任务。
-
最高领袖拥有的最高级别专断权力并不是凭空产生的,也不仅仅只是最高领袖的位置所赋予的,领袖的权威有一个合法性基础——人民的支持。而人民的支持也需要意识形态领域的控制,民意稳定的基石是党的使命是实现中华民族的伟大复兴、通过奋斗让全国人民共同富裕。在此之上历届最高领导人都需要在各自的时代提出同一源流下的新理论,并进行延续,于是中央政策文件上依次会写上“坚持马克思列宁主义、毛泽东思想、邓小平理论、‘三个代表’重要思想、科学发展观,全面贯彻习近平新时代中国特色社会主义思想”。
-
最高领袖的权威与最高领袖提出的思想深刻关联是一种政治制度,原起于……毛泽东通过群众对其个人魅力的认可与忠诚追随发起文化大革命,文化大革命的进行又使得所有权力集于一身,在文化大革命结束后中央领导反思了权力集中在一个决策者身上所带来的危害,但依然要继承最高领袖的个人魅力来维持民意的稳定,而后历届政府持续塑造最高领袖的个人魅力也是维护最高领袖所拥有权威的合法性基础。
-
要在意识形态领域持续塑造最高领袖的个人魅力,路径就是宣传,使最高领袖提出的思想融于党的精神,变成规范、变成制度,变成主流意识形态。
这样就解释了为何含有“党”字的政策文件中会有较高的比例含有历届最高领袖的名字。
-
中国政府网对国务院公报有这样三段介绍,摘录如下。《中华人民共和国国务院公报》(简称《国务院公报》)是1955年经国务院常务会议决定创办,由国务院办公厅编辑出版的面向国内外公开发行的政府出版物。《国务院公报》集中、准确地刊载:国务院公布的行政法规和决定、命令等文件;国务院批准的有关机构调整、行政区划变动和人事任免的决定;国务院各部门公布的重要规章和文件;国务院领导同志批准登载的其他重要文件。《中华人民共和国立法法》规定:在国务院公报上刊登的行政法规和规章文本为标准文本。在国务院公报上刊登的各类公文与正式文件具有同等效力。 ↩︎
-
前几天看完的小说《食南之徒》中有这样一个情节,大汉使节出使南越国,一定要从正门入而不能从偏门入。从汉朝开始统治者施行的“独尊儒术”政策将“名正言顺”撒入社会洪流,名与实结合一体。那么在政策文件标题上,中共中央与国务院的先后顺序就必须是固定的,名非虚,名也是实。 ↩︎
-
写博客的时候歌单放到 Hi-Fi Set 唱的《Sky Restaurant》,联想到了声音相似的 Rie fu 的《Life Is Like A Boat》,又联想到了曾经感到惊艳的一些动画歌曲,有新世纪福音战士的《come on, sweet death》、钢之炼金术师的《LET IT OUT》,听了以后想起一些印象深刻的故事情节,好像从二次元世界里获得了一些内心力量。接着又联想到了安室奈美惠给犬夜叉唱的《Four Seasons》,又去听了她的《Baby Don’t Cry》。写到这里的时候,今天已经在电脑前枯坐了四五个小时,脑中思绪纷繁杂乱、此起彼伏,想得多但写出来的文字很少,不过终于快把这篇写完了,脑子也变得清明些了。 ↩︎