本次 AI 问数项目使用 Dify 搭建完成。
一、流程介绍 🔗
一般的问答流程可简单描述为:人类提问 -> AI 思考或检索 -> AI 回答。这回是第一次做问数项目,知识库也是从零开始积攒,流程编排上整体有点重,下面分成两个部分来介绍。
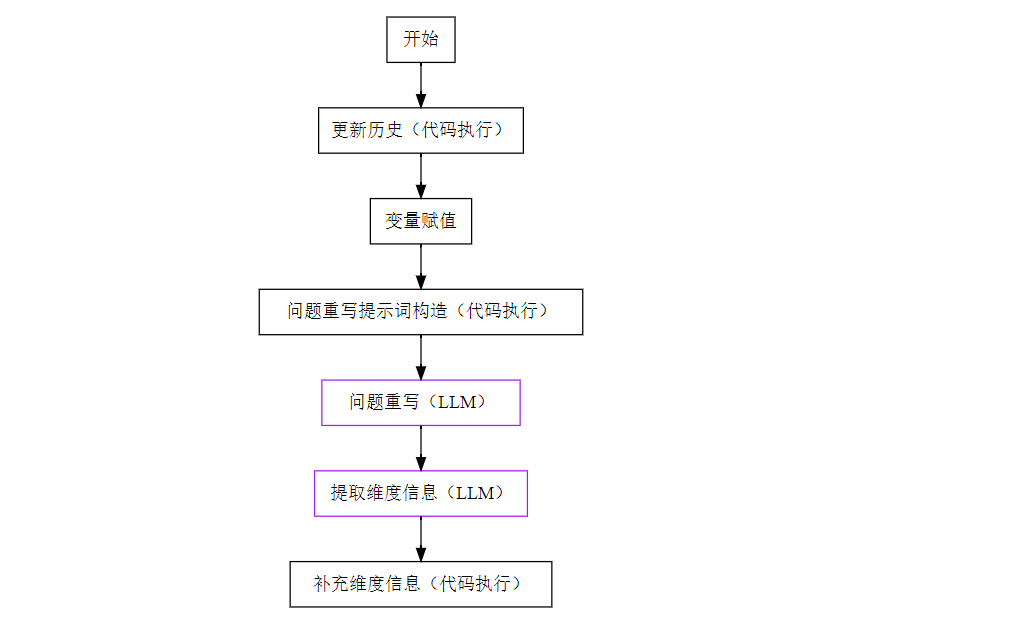
1.1. 问题重写 🔗
第一部分主要是重写、补充用户的问题,调用了两次 LLM(大语言模型,下同)来完善用户提出的问题。
下面所有的“代码执行”节点都是调用 Python3,在“更新历史”的节点中设定输入一个名为memory的会话变量,存储3轮上下文会话信息,随后连同构造的提示词一并输入“问题重写”节点,这里是第一次调用 LLM。
由于用户通常都不了解后台数据库中的表结构、可提问的指标范围,在提问时可能会只给出模糊的问题,缺少一些维度的信息,比如询问某指标数据时缺少地理区域范围、统计时间范围等。如果是文本问答,按照“模糊的问题给出模糊答案、精确的问题给出精确答案”是可行的,但是对于数据问答是不可行的,因此这里第二次调用 LLM 提取各类维度信息,并且再次调用 Python 在提取维度为空时填充默认值。这一步或许还可以发挥另一个作用,即实现行级或列级的权限控制。
查看绘图的 R 代码
library(DiagrammeR)
grViz(diagram = "digraph{
# 定义图形布局,从上到下
graph[rankdir = TB]
# 定义节点
node[shape = rectangle]
A[label = '开始']
B[label = '更新历史(代码执行)']
C[label = '变量赋值']
D[label = '问题重写提示词构造(代码执行)']
E[label = '问题重写(LLM)', color = 'purple']
F[label = '提取维度信息(LLM)', color = 'purple']
G[label = '补充维度信息(代码执行)']
# 定义线
edge[arrowsize = 1,style = solid]
A -> B -> C -> D -> E -> F -> G
}")
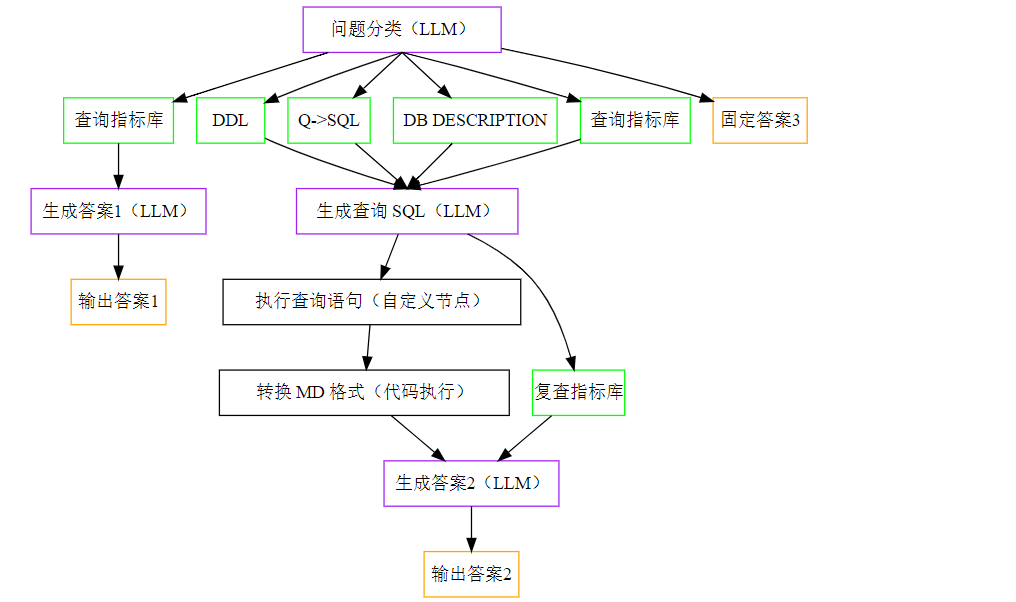
1.2. 生成 SQL 🔗
这一部分节点较多,稍微有些复杂,为便于查看,下面将所有调用 LLM 的节点设置为紫色方框,将所有进行“知识检索”的节点设置为绿色方框,将所有输出答案的节点设置为橙色方框。
改写的问题经过分类节点后会流向三条线路:
- 第一,仅询问指标的释义、计算口径等,在检索知识库后由 LLM 生成答案后输出。
- 第二,查询数据,在检索各类知识后生成 SQL,从数据库中查询数据,最终再由 LLM 给出最终答案。
- DDL,数据库建表信息。
- Q->SQL,常用的 SQL 脚本库。
- DB DESCRIPTION,表名称、字段含义等信息。
- 指标知识库,除了有更详细的指标口径,还有对某些词语概念上的释义,比如对“累计”的定义。
- 第三,其他无关的闲聊,直接指定回复固定的话术。
查看绘图的 R 代码
library(DiagrammeR)
grViz(diagram = "digraph{
# 定义图形布局,从左至右
graph[rankdir = TB]
# 定义节点
node[shape = rectangle]
A[label = '问题分类(LLM)', color = 'purple']
B1[label = '查询指标库', color = 'green']
C1[label = '生成答案1(LLM)', color = 'purple']
D1[label = '输出答案1', color = 'orange']
B2_2[label = 'DDL', color = 'green']
B2_3[label = 'Q->SQL', color = 'green']
B2_4[label = 'DB DESCRIPTION', color = 'green']
B2_5[label = '查询指标库', color = 'green']
B2_6[label = '生成查询 SQL(LLM)', color = 'purple']
B2_7[label = '执行查询语句(自定义节点)']
B2_8[label = '转换 MD 格式(代码执行)']
B2_9[label = '复查指标库', color = 'green']
C2[label = '生成答案2(LLM)', color = 'purple']
D2[label = '输出答案2', color = 'orange']
D3[label = '固定答案3', color = 'orange']
# 定义线
edge[arrowsize = 1, style = solid]
A -> B1 -> C1 -> D1
B2_6 -> B2_7 -> B2_8 -> C2 -> D2
B2_6 -> B2_9 -> C2
A -> D3
edge[samehead = h1, sametail = t1, style = solid]
A -> {B2_2,B2_3,B2_4,B2_5}
{B2_2,B2_3,B2_4,B2_5} -> B2_6
}")
还有一个细节值得说明一下,可以把“提取维度信息”和“补充维度信息”这两个节点放到“问题分类”节点后面,这样的话询问指标含义和无关闲聊这两条线可以少走一个 LLM 节点,效率会更高。
二、数据与测试集 🔗
AI 问数大致包含三种功能:其一,根据问题查询数据;其二,根据数据作图表展示;其三,根据数据进行分析。
键者之前试用过阿里的 Quick BI,这款产品提供简洁美观的图表展示,也可以继续进行几项简单的数据分析,但是在查询数据的能力上偏弱,是根据用户的问题去匹配数据集中的指标,似乎仅支持单表问数,不能进行多表关联查询。而本项目的重点在于根据复杂问题查询数据,另外键者也发现如果把生成答案节点的 LLM 替换成推理模型,输出的答案就会带有分析性质。
2.1. 需求规划 🔗
阿里的 Quick BI 把数据集划分为三种类型,分别是明细表(每行一条记录,不限维度或指标)、多指标周期值、键值对表,大致形式如下。
| 订单 ID | 用户 ID | 订单日期 | 订单金额 |
|---|---|---|---|
| 0001 | c0001 | 2025-01-01 | xxx |
| 统计日期 | 地区 | 近7天累计销售额 | 近15天累计销售额 | 近30天累计销售额 |
|---|---|---|---|---|
| 2025-01-01 | 华中 | xxx | xxx | xxx |
| 统计日期 | 指标名称 | 目标值 | 实际值 |
|---|---|---|---|
| 2025-01-01 | 月度复购率 | xxx | xxx |
| 2025-01-01 | 产品差评率 | xxx | xxx |
最开始键者以为大厂出品,至少理念是经过市场检验的,打算按照这三类来规划数据,后来发现做项目的时候还是需要“具体问题具体分析”。在实际应用场景中,同一类维度需要划分出不同的级别,比如地域维度(机构)可分成总公司、分公司、中心支公司等不同级别,而时间维度也会按照数据更新的频率划分成日更新、月更新、季度更新等。当维度与度量指标组合时,又会衍生出不同的含义,因这含义本身而产生限制。比如时间维度的指标可划分成按统计时点、按统计时期汇总,展开举例就是如每月截止月底客户数是不可以求和的,又如指标本身就是按月统计的年累计指标也不可以求和。考虑到项目刚起步,后来在最终的需求规划中,放弃做大宽表,改为简化后的小表,放入一些基础指标,而需要衍生计算的指标将计算口径和计算方式放入知识库中。
保险公司通常较为关注业绩达成情况,也有多个不同的业绩指标,比如 API(年化保费收入,用于衡量保费规模)、NBEV(新业务价值,用于衡量新业务未来盈利能力)等,同类型的指标可以都按同一套表结构来导入数据。由于此表中既有按月汇总的统计时期数据,又有年累计的统计时点数据,因此要在知识库中额外对“累计”一词写明汇总的规则。
| 月份 | 分公司 | 月达成 | 月达成率 | 月同期 | 月同比 | 年同期 | 年同比 |
|---|---|---|---|---|---|---|---|
| 2025-01 | 湖北 | xx | xx | xx | xx | xx | xx |
| 2025-02 | 河南 | xx | xx | xx | xx | xx | xx |
除了业绩,保险公司也会特别关注 VIP 客户的情况,因为这个行业也符合“二八法则”,即少数客户贡献更多业务价值。这张表需要在指标知识库中详细描述指标释义,即客户数量是指截止到月底的统计时点数据,而另外两个是统计月份内新增或流失的统计时期数据。
| 月份 | 分公司 | 客户数量 | 新增数量 | 流失数量 |
|---|---|---|---|---|
| 2025-01 | 湖北 | xx | xx | xx |
| 2025-02 | 河南 | xx | xx | xx |
另外,也需要关注队伍质量,这才是提升竞争力的关键,保险公司通常根据代理人的业绩达成情况而划分不同级别,比如金星人数、钻星人数等。
| 月份 | 分公司 | 日均出勤 | 金星人力 | 钻星人力 | 出勤率 | 金星率 | 钻星率 |
|---|---|---|---|---|---|---|---|
| 2025-01 | 湖北 | xx | xx | xx | xx | xx | xx |
| 2025-02 | 河南 | xx | xx | xx | xx | xx | xx |
2.2. 准备测试集 🔗
测试用的问题有两个来源,一是人类测试过程中产生,二是由 AI 根据表结构生成。由于测试集中每个问题的正确答案还是需要键者人工确认一遍(PS至少要把 AI 生成的 SQL 语句丢到数据库里执行),若是准备的测试集问题太多也很耗费人力,因此键者根据自身经验以及 AI 生成的问题总结了一些问题的方向,也许某种程度上重复的问题可以不用再测。
- 筛选
- 筛选维度
- 2025年1月河南的 API 达成率是多少?
- 河南最近三个月的 API 达成率是多少?
- 河南从2024年3月开始最近三个月的 API 达成率是多少?
- 单表单项条件筛选
- 当前 API 月达成率超过100%的分公司是哪几个?
- 2025年1月 API 月达成在1千万到3千万之间的分公司是哪些?
- VIP客户数低于1千的分公司有哪些?
- 2024年3月API月同比出现负增长的分公司有哪些?(知识库中需定义“负增长”)
- 单表多项条件筛选
- 金星率和钻星率均超过20%的分公司有哪些?
- 哪些分公司同时完成了NBEV和API的月达成目标?
- 六星部数占比和三星组数占比均达标的分公司是哪些?(知识库中需定义“达标”)
- 多表关联条件筛选
- 在2025年1月,哪家分公司的金星人力超过300,且 VIP 客户数超过1000?
- 去年哪些分公司同时完成了 NBEV 和 API 的月达成目标?
- 排除条件
- 没有钻星人力的分公司有哪些?
- VIP 客户只流失、不新增的是哪个?
- 筛选维度
- 排序
- 单排名
- 当前钻星人力数量排名前三的分公司是哪些?
- 24年,API 月达成率排名后五的分公司是哪些?
- 2025年 API 前十的机构有哪些?它们的 API 数据分别是多少?
- 多排名
- 现在哪些分公司的 NBEV 与金星人力数量均排名前五?
- 单排名
- 汇总
- 求和
- 25年全系统累计 NBEV 是多少?
- 2024年湖北 NBEV 年累计达到多少?
- 求最值,最大,最小
- 2024年2月出勤率最低的分公司是哪个?
- 钻星人力数量与金星人力数量的差值最大的分公司是哪个?
- NBEV 月达成金额同比增长率最高的月份是哪个?
- 求和
- 统计时间
- 统计时点
- 湖北今年2月的 VIP 客户数量
- 北京去年的新增 VIP 客户数量
- 统计时期,连续/不连续时间段
- 湖北去年四季度流失了多少 VIP 客户?
- 22年、23年全系统 VIP 客户新增多少?
- 去年一季度和今年一季度,NBEV 分别累计达成多少?
- 统计时点
- 更加复杂的情况
- 比较
- 年同期 API 达成金额与当前达成金额差距最大的分公司是哪个?(比较同一指标不同时点)
- 江西和福建2024年 NBEV 哪个大?(比较同一指标不同机构)
- 三星组数占比高的分公司是否金钻人力数量也较高?(比较不同指标)
- VIP 客户新增数量与日均出勤人数是否有相关性?(比较分析指标相关关系)
- 总部数超过200的分公司中,NBEV 月达成率是否普遍更高?(比较分析指标因果关系)
- 统计时期变动趋势
- 客户数量连续三个月增长的分公司有哪些?
- 近12个月流失客户数量的波动情况如何?
- 2024年3月与前三个月相比,API达成率有何变化?
- 2024年全年各月 NBEV 的变化趋势如何?
- 根据基础指标计算新增指标
- VIP 客户数量年同比增长超过20%的分公司有哪些?
- 2024年第一季度综合业绩(NBEV+API)排名前三的分公司是哪些?
- 2024年2月新增数量与流失数量的比值最高的分公司是哪个?
- 当前 VIP 客户流失率是多少?
- 问题不够精确(如未指定统计时期范围)
- 年同期 NBEV 达成金额超过5000万元的分公司有哪些?
- 月达成率低于去年同期月达成率的分公司有哪些?
- 流失客户数量最多的分公司是哪个?
- 2024年第一季度六星部数占比是否有提升?
- 比较
三、测试与评估 🔗
此项目流程中调用 LLM 的节点有四种,分别是问题重写、问题分类、生成 SQL、生成答案。由于 Dify 不会把流程中每个节点的信息都输出,若要测试各个节点的效果,需要在原流程的基础上分别改造不同的流程,或者构造不同的测试集来完成。
3.1. 测试问题重写 🔗
问题重写相关流程可以调整修改的节点只有两种:其一是调用 LLM 的节点,可以修改提示词、调试可选的模型参数、切换不同的模型;其二是“代码执行”的节点,可以修改 Python 代码。
本小节的重点在于调用 LLM 提取上下文中的维度信息(PS其实应该先判断用户的问题是否精确,但这点还没想好怎么实现),在其缺失时填充默认值。由于只是要测试问题中的信息有没有补充完整,尚且不需要批量测试,只需要另建一个新的流程,在补充维度信息后直接连接到回复答案的节点,其他多余节点都去掉,这样人类提问后,AI 的答案就是重写后的答案。
在提取维度信息(LLM)节点中,需要设置一些提示词,以及要求 LLM 提取信息的示例,如下所示(PS这是在他人的成果上修改的)。
<instructions>
1. 从聊天记录中提取用户提到的机构名称、统计时间点或统计时间段。
2. 机构名称是河南,湖北等名称;统计时点是'2025-03'、'今年2月'、'2025年2月'等。
3. 如果用户在多条聊天记录中提到机构名称,提取最新的一条记录中的机构名称;如果用户在多条聊天记录中提到时间,提取最新一条记录中的时间。
4. 如果聊天记录中没有提到机构名称,输出null;如果聊天记录中没有提到时间,输出 null。
5. 输出结果时,不要包含任何 XML 标签。
6. 聊天记录中如果询问排序或者范围,比如哪家,最高,最低,前几,累计等,输出 not。
注意事项:
- 确保提取的机构名称是用户明确提到的。
- 确保提取的时间(任何统计时间点或统计时间段)是用户明确提到的。
- 如果用户没有提到机构名称,输出 null;如果用户没有提到时间,输出 null。
- 确保输出的格式清晰且易于理解。
</instructions>
<examples>
<example>
<chat>
用户: 2025年2月河南个险的 API 达成率是多少?。
用户: 什么是 API。
</chat>
<output>
河南
</output>
</example>
<example>
<chat>
用户: 什么是 NBEV?
</chat>
<output>
null
</output>
</example>
<example>
<chat>
用户: 2025年2月 API 达成率最高的机构是哪个?
</chat>
<output>
not
</output>
</example>
<example>
<chat>
用户: 在2025年2月,哪家分公司的金星人力超过300?
</chat>
<output>
not
</output>
</example>
</examples>
在 Dify 中执行 Python 代码实现填充默认值的功能时,需要额外注意两个细节。
- 在 Dify 的流程中,所有需要调用 Python 时输入的变量应该在全局的会话变量中进行定义,变量名称在代码中应保持一致。
- 若用 LLM 提取多项维度信息,似乎只能输出一个字符串,而不能作为多个变量分别输出。因此在补充多项信息时需要先拆分然后再填充默认值。
在补充维度信息(执行代码)节点中,应分别设置代码的输入变量、输出变量和 Python 代码。其中输入变量分别来源于“问题重写”节点的query和源于“提取维度信息”节点的org_name,而输出变量就是result(PS以下代码是键者使用 AI 帮忙生成,经过多次调试后确定)。
from datetime import datetime, timedelta
def main(query: str, org_name: str) -> dict:
user_org = '湖北' # 机构默认值
default_time = '' # 时间默认值
# 拆分 org_name,按换行符 `\n` 拆分成两个部分
org_parts = org_name.split("\n")
# 处理机构名称
extracted_org = org_parts[0] if len(org_parts) > 0 else 'null'
if extracted_org.lower() == 'null' or extracted_org.strip() == '':
print("机构为空,使用默认值")
extracted_org = user_org
# 处理时间
extracted_time = org_parts[1] if len(org_parts) > 1 else 'null'
if extracted_time.lower() == 'null' or extracted_time.strip() == '':
print("时间为空,使用默认值(上个月)")
today = datetime.today()
first_day_of_this_month = today.replace(day=1)
last_month = first_day_of_this_month - timedelta(days=1)
extracted_time = last_month.strftime('%Y-%m') # 格式:YYYY-MM
# 检查 query 是否已经包含机构或时间,避免重复拼接
result_parts = []
if extracted_time not in query:
result_parts.append(extracted_time)
if extracted_org not in query:
result_parts.append(extracted_org)
result_parts.append(query) # query 始终需要保留
result = ' '.join(result_parts) # 使用空格拼接,避免格式问题
return {
"result": result
}
# 示例测试
print(main("API达成率", "null\nnull")) # 预期: "2025-03 湖北 API达成率"
print(main("保险客户统计", "")) # 预期: "2025-03 湖北 保险客户统计"
print(main("保险客户统计", "null")) # 预期: "2025-03 湖北 保险客户统计"
print(main("保险客户统计", "湖北\nnull")) # 预期: "2025-03 湖北 保险客户统计"
print(main("保险客户统计", "null\n今年2月")) # 预期: "今年2月 湖北 保险客户统计"
print(main("客户增长情况", "上海\n2025-03")) # 预期: "2025-03 上海 客户增长情况"
print(main("湖北25年1月API达成率", "湖北\n25年1月")) # 预期: "湖北25年1月API达成率"
print(main('25年1月湖北个险API是多少?','湖北\n25年1月')) # 预期: "25年1月湖北个险API是多少?"
3.2. 评估生成 SQL 🔗
本节测试生成 SQL 的效果也需要另建一个新的流程,在原流程的基础上让“生成 SQL”的节点直接连接到回复答案的节点,剩下多余的节点都去掉,这样人类提出问题后,AI 给出的答案就是生成的 SQL。
评估生成 SQL 是否符合预期的指标用的是 RAGAS 中的LLMSQLEquivalence,等于是使用 LLM 评估生成的 SQL 与人类提供的正确答案是否等价。整个评估过程的代码可分为三个步骤,如下。
第一步,提前封装好评估指标要调用的模型,这里的 evaluator_llm 后面会用到。
from langchain_community.llms.tongyi import Tongyi
from ragas.llms import LangchainLLMWrapper
tongyi_model = Tongyi(api_key="sk-xx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
evaluator_llm = LangchainLLMWrapper(tongyi_model)
第二步,准备问题和正确答案,以及数据库表结构。
批量测试多个不同的问题,用于确定答案不符合预期的问题源头。而单个问题重复多次,用于确定失误发生的概率,比如键者发现问题重写时偶尔会把2025写成205,但概率低于50分之一,可以忽略不计。
# 批量导入不同的问题和答案
questions = ['2025年1月河南个险的 API 达成率是多少?',
'2025年河南个险的 API 达成率是多少?',
'在2025年1月,哪家分公司的金星人力超过300,且 VIP 客户数超过1000?'
]
references = ["SELECT `月达成率` FROM t_ge_api WHERE `分公司` = '河南' AND `月份` = '2025-01';",
"SELECT max(`年达成率`) FROM t_ge_api WHERE `分公司` = '河南' AND `月份` LIKE '2025%';",
"SELECT s.分公司 FROM t_ge_star s JOIN t_vip_customer_ge v ON s.分公司 = v.分公司 AND s.月份 = v.月份 WHERE s.月份 = '2025-01' AND s.金星人力 > 300 AND v.客户数量 > 1000;"
]
# 重复的问题和答案,用来测试问题发生的概率
# 定义单个问题
question = "河南个险从2024年3月开始最近三个月的 API 达成率是多少?"
reference = "SELECT `月份`,`月达成率` FROM t_ge_api WHERE `分公司` = '河南' AND `月份` IN ('2024-03', '2024-04', '2024-05');"
# 重复
questions = [question for _ in range(10)]
references = [reference for _ in range(10)]
# 数据库表结构
reference_contexts = [
"""
Table t_ge_api:
- `分公司`: VARCHAR
- `月份`: VARCHAR
- `月达成`: INT
- `月达成率`: INT
- `月同期`: VARCHAR
- `月同比`: VARCHAR
- `年同期`: VARCHAR
- `年同比`: VARCHAR
""",
"""
Table t_ge_star
- `分公司`: VARCHAR
- `月份`: VARCHAR
- `日均出勤`: INT
- `金星人力`: INT
- `钻星人力`: INT
- `出勤率`: VARCHAR
- `金星率`: VARCHAR
- `钻星率`: VARCHAR
""",
"""
Table t_vip_customer_ge
- `分公司`: VARCHAR
- `月份`: VARCHAR
- `客户数量`: INT
- `新增数量`: INT
- `流失数量`: INT
"""
]
第三步,评估结果。
import requests
qa_url = 'https://dify-test.xxxx/v1/chat-messages'
qa_headers = {
'content-type': 'application/json; charset=UTF-8',
'Authorization': 'Bearer app-cJEtJu0ykdqSOuWuIHhw3aWD'
}
from ragas import SingleTurnSample,EvaluationDataset
# 存储所有样本
samples = []
for question, reference in zip(questions, references):
qa_input = {
"inputs": {},
"query": question,
"response_mode": "blocking",
"conversation_id": "",
"user": '阿木狗',
"files": {}
}
# 发送请求获取回答
response = requests.post(url=qa_url, headers=qa_headers, json=qa_input, timeout=600)
res = response.json()
# 提取答案
response.sql = res['answer']
# 创建单轮样本并添加到列表
sample = SingleTurnSample(
response=response.sql,
reference=reference,
reference_contexts=reference_contexts
)
samples.append(sample)
# 创建评估数据集
eval_dataset = EvaluationDataset(samples=samples)
# 选择评估指标进行评估
from ragas import evaluate
from ragas.metrics import LLMSQLEquivalence
metrics = [LLMSQLEquivalence(llm=evaluator_llm)]
results = evaluate(dataset=eval_dataset, metrics=metrics)
# 设置显示所有列
import pandas as pd
pd.set_option('display.max_columns', None)
print(results.to_pandas())
# 将结果转换为 pandas 数据框
results_df = results.to_pandas()
# 导出数据框到 CSV 文件
results_df.to_csv("/home/evaluation_results.csv", index=False, encoding='utf-8')
3.3. 评估生成答案 🔗
原以为只要 SQL 写对了,答案就会符合预期,哪知还是碰上了奇葩情况。比如用户提问“江苏和浙江分公司哪个 API 达成更高”,生成的 SQL 执行后得到的就是更高的那个分公司以及指标值,结果到了生成答案那步,AI 却说只得到了一个分公司的数值,另一个没有得到,因此无法比较……
未完待续。