键者平日使用 glmnet 包中的 cv.glmnet()函数来做交叉验证,下面是编造的一份并不算太复杂的数据。执行一次代码,得到的一个结果如下。
library(glmnet)
X <- matrix(rnorm(6e5 * 200), 6e5, 200)
Y <- rnorm(6e5)
system.time(cv.glmnet(X, Y))
user system elapsed
150.318 23.750 173.996
在不开启并行计算的情况下,流逝时间(elapsed)约等于系统时间(system)和用户时间(user)之和。
- 用户时间(user):当前 R 进程及子进程执行代码的运行时间。
- 系统时间(system):操作系统为当前 R 进程及子进程提供服务的系统时间,包括启动其他进程、查看系统时钟等。
- 流逝时间(elapsed):从开始执行到结束执行的实际时间。
前些天无意中从 glmnet 包官网翻到它支持并行计算,仅需设定 cv.glmnet(..., parallel = TRUE),但让这个参数起作用的前提是 R 环境也得支持并行计算。虽然数据量和模型复杂度不同时,使用并行时提升的效率也不同,但是可以推理得出的结论大致是相似的。键者近日浅浅接触了一丁点1并行计算的知识,但所学再粗浅也得整理一番后,才能成为被记住的知识。
话又说回来,R 中做并行计算的包数量极多,那到底有多少呢?在https://r-pkg.org/上搜索 parallel,或者根据 pkgsearch 包的文档、网站介绍,在 R 中执行pkg_search("parallel")可以看到已经有1721个,并且仍然会继续增长。统计之都论坛上曾有一篇R与并行计算简要介绍了一些基础概念,可是直到键者切身实践之前,仍然对那些概念感到一片混沌,不明所以,即便使用了并行计算,也仅仅只是让它跑(RUN)起来了而已。鉴于之前已经梳理过并行/串行、隐式并行/显示并行的概念,这里不再重复,但对线程(thread)、核心(core)、进程(process)、节点(node)、集群(cluster)等概念再捋一捋。
-
在键者的个人电脑(Windows 系统)上安装了 R 和 Rstudio,单击 Rstudio 的图标可以打开一个 R 会话界面,也相当于将个人电脑中的一部分内存资源分配给了一个 R 进程,将此 R 会话命名为 R session1。
-
在1的基础上,再单击 Rstudio 的图标就可以打开另一个 R 会话界面,相当于将个人电脑中的另一部分内存资源分配给了另一个 R 进程,并将新开的 R 会话命名为 R session2。此时,个人电脑上的两个 R 会话 R session1 和 R session2 彼此之间相互独立,会话对应的进程也相互独立。
-
在1的基础上,键者使用了支持多进程并行的包,即使只打开了一个 R 会话即 R session1 也可以开启多个进程,但与2有区别的是将 R session1作为父进程,并且在此基础上打开多个作为分支的子进程如 R process1、R process2、R process3。三个子进程可以共享父进程的资源。
-
键者的个人电脑资源不够用,于是调用服务器(Linux)上面的资源。服务器上面有五个节点,分别是node1、node2、node3、node4、node5,假定这五个节点上面分别打开了一个 R 进程,各自对应的进程命名为 R node process1、R node process2、R node process3、R node process4、R node process5。为了同时使用这五个节点的资源,键者将 node1 设置主节点,将 node2-node5 设置为从节点,并且节点之间互相能免密登录,那么此时跨多节点的并行就是多进程的并行。
事实上,一个进程还可开启多个线程(thread)任务。如果计算资源允许,或者使用的包中有相关的函数或函数中的参数可以设置并行线程数,那么在多进程的前提下开启多线程也是可行的。但需注意的是,不管是设置多少进程或进程中设置多少线程,真正在运行的资源都是硬件上的 CPU 核心,一旦进程、线程数总和超过可用核心数,并行计算的运算效率也会打折扣。所以,在实施并行计算之前,一定要先确认清楚可用核心数。
# 得到当前节点上的物理核心数
parallel::detectCores(logical = F)
# 得到当前 R 进程上可用的逻辑核心数
parallelly::availableCores()
future::availableCores()
上面这个任务,键者认为单进程、单线程执行太慢,而节点上可用的资源并不只有一个核心,可以使用并行计算来提升运算效率、节省时间花销,便依次如此尝试:
-
单节点、单进程:在一个服务器节点(node)上打开一个 R 会话(session),且只开启一个进程( process)。一个核心(core)可以独立执行一个线程(thread)任务。
-
单节点、多进程:通过打开多个 R 会话(session)的方式开启多个进程( process);或者只打开一个 R 会话(session),但开启一个父进程和多个分支子进程。
-
多节点、多进程:使用多个远程节点(node)开启多个进程( process)。可建立集群(cluster)对节点上的任务进行统一调度管理。或者在多个节点可以连接的基础上区分主节点、从节点,在主节点上执行任务。
doParallel:单节点 🔗
doParallel 包依赖于 foreach 和 parallel,支持开启多个进程或多个线程任务,但不支持多个节点的并行。执行makeCluster()函数可以创建一个用于并行计算的虚拟集群,相当于在单个节点上运行多个进程。多进程并行的方式通常有两种。
-
其一,默认情况下并行多个 R 后端进程。
-
其二,创建多个分支子进程,比如执行
cl <- makeForkCluster(nnodes = 3)来指定子进程数量为3。由于子进程共享父进程的资源和对象,不需要再次加载计算任务需要用到的数据和包,可以省去clusterExport和clusterEvalQ这两步。
library(foreach)
library(iterators)
library(parallel)
library(doParallel)
# 设定核心数,创建多个独立进程的虚拟集群
cores <- 3
cl <- makeCluster(cores)
# 或设定子进程数量,创建多个分支子进程的虚拟集群
# cl <- makeForkCluster(nnodes = 3)
# 注册并行后端
registerDoParallel(cl)
# 检查注册并行后端是否生效,假如设定3核会得到数字3
getDoParWorkers()
# 把要用到的包和全部对象(包括数据)加载到虚拟集群
clusterExport(cl, c('X', 'Y'))
clusterEvalQ(cl, expr = { library(glmnet) })
# 计算运行时间
system.time(cv.glmnet(X, Y, parallel = TRUE))
# 关闭隐式集群对象,即用 registerDoParallel() 函数注册的并行后端
stopImplicitCluster()
# 关闭显式集群对象,即用 makeCluster() 函数创建并赋值给某个变量的集群对象
stopCluster(cl)
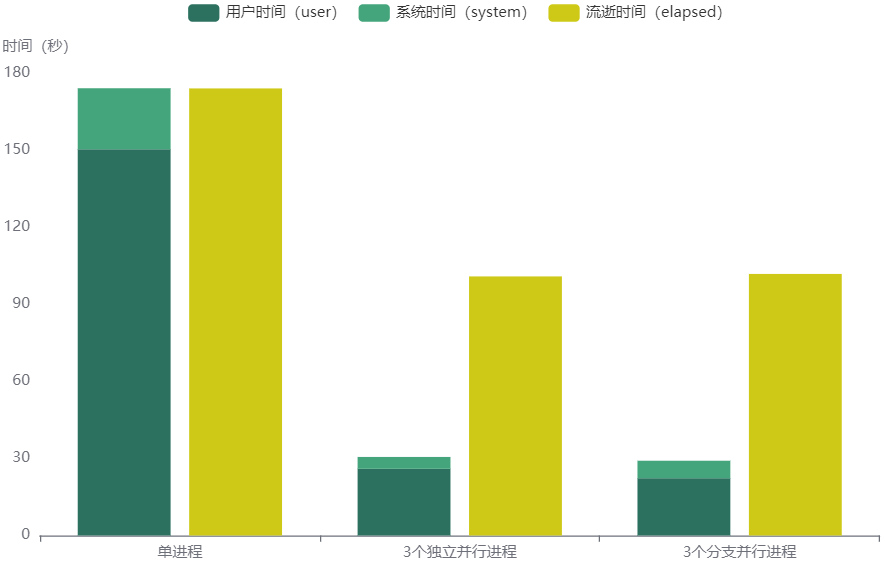
分别执行一次在单个节点上建立3个独立并行进程、3个分支子进程,各得到一次结果。将这两个结果和单进程不并行的结果简单对比,在本文设定的数据场景下,可以得到以下结论。
- 3个并行进程比单进程不并行的时间花销低。
- 对比3个独立并行进程、3个分支子进程,两者时间花销非常接近。
- 单进程不并行时,
流逝时间(elapsed) = 系统时间(system)+ 用户时间(user)。 启动多进程并行后,流逝时间(elapsed) > 系统时间(system)+ 用户时间(user)。
查看绘图的数据和代码
library(echarts4r)
data <- data.frame(
type = c('单进程', '3个独立并行进程', '3个分支并行进程'),
user = c(150.318, 25.954, 22.294),
system = c(23.750, 4.617, 6.806),
elapsed = c(173.996, 100.830, 101.799)
)
data |>
e_charts(type) |>
e_bar(user,
name = '用户时间(user)',
color = '#2C715FFF',
stack = 'grp1') |>
e_bar(system,
name = '系统时间(system)',
color = '#44A57CFF',
stack = 'grp1') |>
e_bar(elapsed, name = '流逝时间(elapsed)', color = '#CEC917FF') |>
e_y_axis(
name = '时间(秒)',
nameLocation = 'end',
splitLine = list(show = FALSE)
)
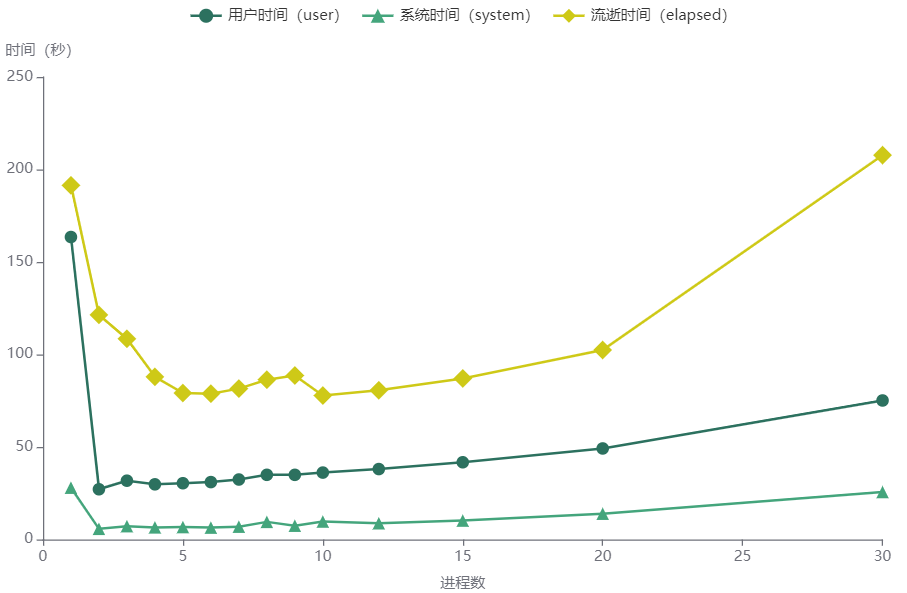
在默认建立独立并行进程的情况下,分别使用1-10、12、15、20、30等不同核心数来开启并行,并得到对应的结果,绘制图形如下。显然,在本文设定的数据场景下,并不是设定并行进程数越多,可提升的运行效率越高。
查看绘图的数据和代码
library(echarts4r)
data <- data.frame(
cores = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 15, 20, 30),
user = c(163.5, 27.153, 31.789, 29.822, 30.421, 31.031, 32.429, 34.965, 34.956, 36.177, 38.072, 41.748, 49.211, 75.145),
system = c(28.011, 5.766, 7.211, 6.547, 6.717, 6.429, 6.938, 9.525, 7.462, 9.713, 8.779, 10.233, 13.948, 25.664),
elapsed = c(191.452, 121.407, 108.479, 87.913, 79.174, 78.811, 81.551, 86.362, 88.652, 77.815, 80.658, 87.056, 102.428, 207.726))
data |>
e_charts(cores) |>
e_line(
user,
name = '用户时间(user)',
symbol = 'circle',
symbolSize = 10,
color = '#2C715FFF'
) |>
e_line(
system,
name = '系统时间(system)',
symbol = 'triangle',
symbolSize = 10,
color = '#44A57CFF'
) |>
e_line(
elapsed,
name = '流逝时间(elapsed)',
symbol = 'diamond',
symbolSize = 15,
color = '#CEC917FF'
) |>
e_x_axis(
name = '进程数',
nameLocation = 'center',
nameGap = '30',
splitLine = list(show = FALSE)
) |>
e_y_axis(
name = '时间(秒)',
nameLocation = 'end',
splitLine = list(show = FALSE)
)
snow:多节点 🔗
根据 snow 包文档在 snow-startstop 小节详细描述中的一处链接,snow 支持三种连接多节点做并行计算的方法,即 PVM(Parallel Virtual Machine)、MPI(Message Passing Interface)、SOCK(Socket)。由于前两种需要额外安装其他包或软件,键者仅尝试了第三种类型。
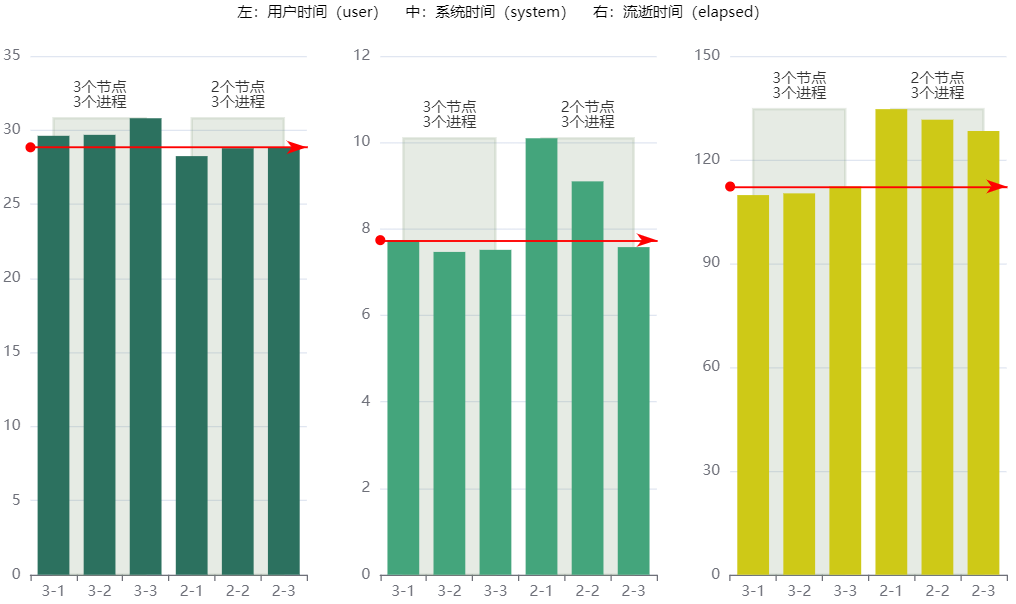
键者可使用的服务器上有两个节点安装了 R,其中一个节点上有两个端口可用,于是一共可看作有三个节点可用于并行计算。设置其中一个节点为主节点,其他节点为从节点。这里的主节点和从节点的关系可看做客户端和服务器,但是主节点上的进程和从节点上的进程并不等于父进程和子进程,而是相互独立的。使用多个节点上的计算资源,但是设定核心数依然为3,最终得到的结果显示,和在单个节点上使用3个进程并行的时间花销十分接近。这也说明,本文设定的数据场景实际上远不需要使用多节点并行。
library(snow)
workerList <- list(
list(host = "xx.xx.x.84", port = 10187, outfile = "~/log1.log", rshcmd = "ssh -p 22"),
list(host = "xx.xx.x.84", port = 10188, outfile = "~/log2.log", rshcmd = "ssh -p 22"),
list(host = "xx.xx.x.85", port = 10187, outfile = "~/log3.log", rshcmd = "ssh -p 22"))
# 创建一个集群对象,设置主节点
cl <- makeCluster(workerList, type = "SOCK", master = "xx.xx.x.84")
# 统一注册并行后端
registerDoParallel(cl, cores = 3)
# 检查注册并行后端是否生效,假如设定8核会得到数字8
getDoParWorkers()
# 把要用到的包和全部对象(包括数据)加载到集群
clusterExport(cl, c('X','Y'))
clusterEvalQ(cl,expr= { library(glmnet)
library(doParallel)})
# 计算运行时间
system.time(cv.glmnet(X, Y, parallel = TRUE))
# 关闭隐式集群对象,即用 registerDoParallel() 函数注册的并行后端
stopImplicitCluster()
# 关闭显式集群对象,即用 makeCluster() 函数创建并赋值给某个变量的集群对象
stopCluster(cl)
分别在连接3个节点和2个节点的情况下,开启3个进程并行,且将每种情况执行了3次再进行统计。两种情况在时间花销上存在微弱差异。整体上看,3个节点、3个进程的时间花销比2个节点、3个进程低。
查看绘图的数据和代码
library(echarts4r)
library(data.table)
data <- data.table(
type = c('3-1', '3-2', '3-3', '2-1', '2-2', '2-3'),
user = c(29.616, 29.681, 30.8, 28.245, 28.778, 28.843),
system = c(7.736, 7.468, 7.516, 10.097, 9.1, 7.579),
elapsed = c(109.784, 110.283, 112.263, 134.634, 131.584, 128.314))
#使用melt函数将数据从宽变长
data.facet <-
data.table::melt(
data,
id = "type", #长数据中第一个字段
measure = c('user','system','elapsed'),
variable.name='variable', #长数据中第二个字段,内容是'num1', 'num2', 'num3', 'num4'等四个类别
value.name = 'num' #长数据中第三个字段,内容是num1-num4等原四个字段中的具体数值
)
data.facet$color <- c(rep('#2C715FFF', 6), rep('#44A57CFF', 6), rep('#CEC917FF', 6))
data.facet |>
group_by(variable) |>
e_charts(type) |>
e_bar(num) |>
e_facet(
rows = 1,
cols = 3,
) |>
e_legend(show = FALSE) |>
e_add_nested("itemStyle", color) |>
e_mark_line(
serie = 'user',
data = list(yAxis = 28.843),
label = list(show = FALSE),
lineStyle = list(
width = 1.5,
type = 'solid',
color = 'red',
cap = 'square'
)
) |>
e_mark_line(
'system',
data = list(yAxis = 7.736),
label = list(show = FALSE),
lineStyle = list(
width = 1.5,
type = 'solid',
color = 'red',
cap = 'square'
)
) |>
e_mark_line(
'elapsed',
data = list(yAxis = 112.263),
label = list(show = FALSE),
lineStyle = list(
width = 1.5,
type = 'solid',
color = 'red',
cap = 'square'
)
) |>
e_mark_area(
data = list(
list(
name = '3个节点\n3个进程',
xAxis = '3-1',
yAxis = 0
),
list(xAxis = '3-3', yAxis = 'max')
),
itemStyle = list(
color = "#819A7AFF",
borderColor = "#819A7AFF",
opacity = 0.2,
borderWidth = 2
)
) |>
e_mark_area(data = list(
list(
name = '2个节点\n3个进程',
xAxis = '2-1',
yAxis = 0
),
list(xAxis = '2-3', yAxis = 'max')
)) |>
e_text_g(
left = "center",
top = 20,
z = -1000,
style = list(text = "左:用户时间(user) 中:系统时间(system) 右:流逝时间(elapsed)",
fontSize = 12)
)
以上是多节点、多进程情况下,统一注册并行后端进程;以下是单独为每个节点注册并行后端进程,此种情况下,每个节点执行程序的时间会单独统计。
# 单独为每个节点设置核心数
clusterApply(cl, 1:length(cl), function(x) {
# 注册并行后端
registerDoParallel(cores = 1)
# 需要并行的代码
system.time(cv.glmnet(X, Y, parallel = TRUE))
})
# 为每个节点分别设置不同的核心数
clusterApply(cl, 1:length(cl), function(x) {
if (x == 1) {
registerDoParallel(cores = 1)
} else if (x == 2) {
registerDoParallel(cores = 2)
} else {
registerDoParallel(cores = 3)
}
system.time(cv.glmnet(X, Y, parallel = TRUE))
})
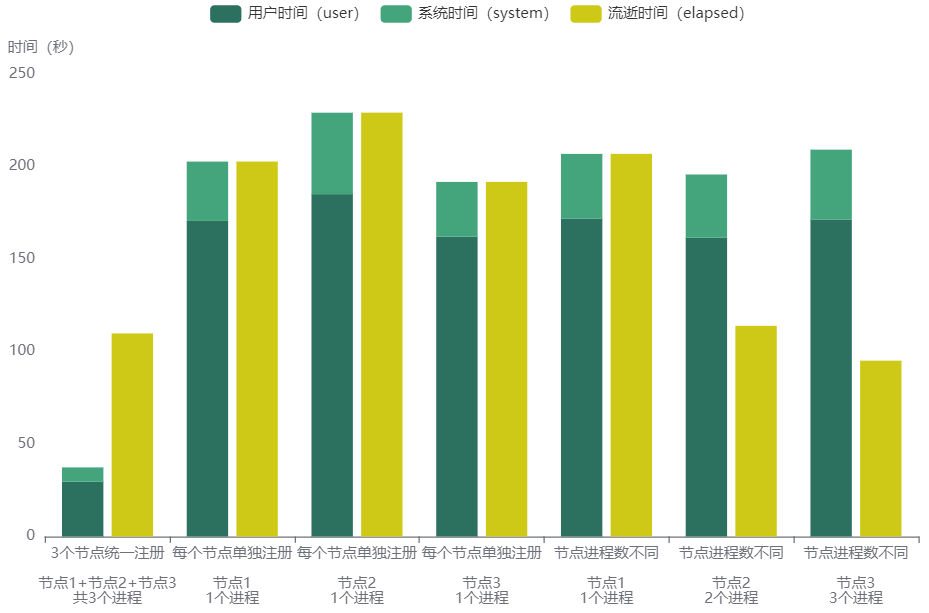
在本文的数据场景中,关于流逝时间(elapsed)与系统时间(system)+ 用户时间(user)的关系,可以简要总结出以下几点:
- 大于
- (1)单节点、多进程
- (2)多节点、多进程,且统一注册并行后端,且节点数等于进程数
- 等于
- (3)单节点、单进程,不开启并行
- (4)多节点、多进程,且每个节点单独注册并行后端,且每个节点设置仅1个进程
- 小于
- (5)多节点、多进程,且每个节点单独注册并行后端,且每个节点设置多于1个进程
看上去,(1)(2)与(5)是相互矛盾的,同样是多个进程并行,但流逝时间(elapsed)与系统时间(system)+ 用户时间(user)的关系却不同。键者认为,这是因为在(2)的情况下,多个节点统一注册并行后端,流逝时间(elapsed)为多个节点的系统时间(system)+ 用户时间(user)之和,其中也包含了多出系统时间(system)+ 用户时间(user)的时间花销,比如各个进程的CPU核心在执行代码之前的等待时间、资源分配与调度的时间、时间信息在各进程传递和接收的时间等,而因多进程并行后减少的时间花销比这部分多出来的时间花销更少,于是造成了“大于”的效果。而在(5)的情况下,每个节点单独注册并行后端,流逝时间(elapsed)仅仅包括每个节点的系统时间(system)+ 用户时间(user),并且由于多进程并行而使得时间花销减少,于是造成了“小于”的效果。而(1)与(2)情况相似。
查看绘图的数据和代码
library(echarts4r)
data <- data.frame(
type = c('3个节点统一注册\n\n节点1+节点2+节点3\n共3个进程', '每个节点单独注册\n\n节点1\n1个进程','每个节点单独注册\n\n节点2\n1个进程','每个节点单独注册\n\n节点3\n1个进程','节点进程数不同\n\n节点1\n1个进程','节点进程数不同\n\n节点2\n2个进程','节点进程数不同\n\n节点3\n3个进程'),
user = c(29.616, 170.58, 185.062, 162.08,171.886, 161.493, 171.347),
system = c(7.736, 32.074, 44.024, 29.587,34.932, 34.183, 37.758),
elapsed = c(109.784, 202.67, 229.107, 191.692,206.836, 113.864, 95.029)
)
data |>
e_charts(type) |>
e_bar(user,
name = '用户时间(user)',
color = '#2C715FFF',
stack = 'grp1') |>
e_bar(system,
name = '系统时间(system)',
color = '#44A57CFF',
stack = 'grp1') |>
e_bar(elapsed, name = '流逝时间(elapsed)', color = '#CEC917FF') |>
e_y_axis(
name = '时间(秒)',
nameLocation = 'end',
splitLine = list(show = FALSE)
) |>
e_x_axis(axisLabel = list(interval = 0))
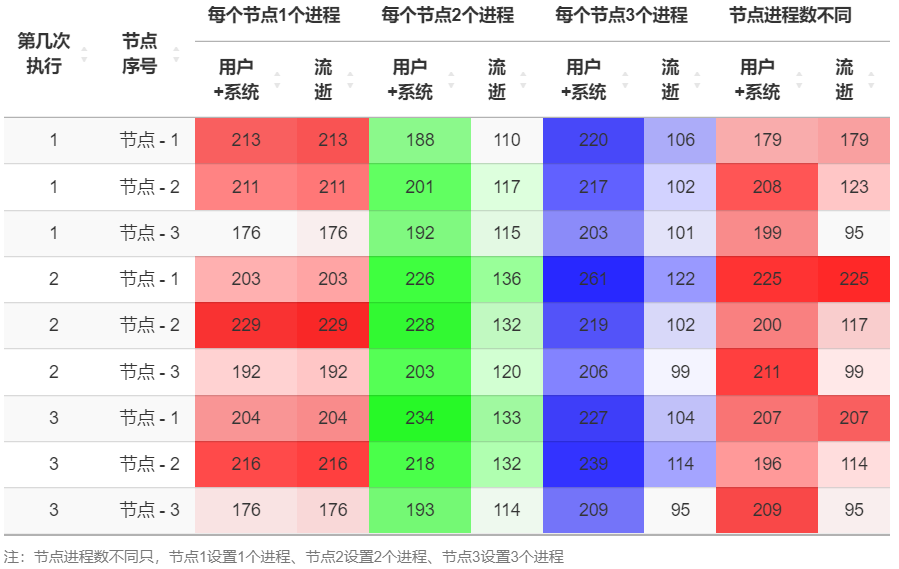
另外,键者用的三个节点其实对应的是两个服务器 IP 地址的三个端口,即xx.xx.x.84:10187、xx.xx.x.84:10188、xx.xx.x.85:10187,并将xx.xx.x.84设置为主节点。在对每个节点单独注册并行后端时,这三个地址分别对应节点1、节点2、节点3。键者怀疑,尽管3个节点应该看做互相独立,但节点1和节点2之间可能会存在争夺资源的情形,而导致节点3的运行效率在多数时候高于节点1和节点2。由于每一次执行代码的时间均不相同,以下是不同情况各执行三次得到的结果。由于键者无法肯定百分百了解后台程序运行的逻辑关系,因此也无法严谨地得到结论,只能成为一点点个人经验2。
查看绘图的数据和代码
library(DT)
library(data.table)
data2 <- data.table(
type1 = c(rep('每个节点1个进程',9),rep('每个节点2个进程',9),rep('每个节点3个进程',9),rep('节点进程数不同',9)),
type2=rep(c(1,1,1,2,2,2,3,3,3),4),
# 节点序号
rank=rep(c('节点 - 1','节点 - 2','节点 - 3'),12),
user = c(174.562, 172.729, 150.514, 170.58, 185.062, 162.08, 166.433, 173.957, 151.369, 159.262, 169.13, 160.206, 181.814, 184.752, 165.084, 186.861, 179.302, 160.259, 180.922, 177.435, 164.977, 206.496, 182.892, 167.452, 185.177, 192.228, 170.579, 154.321, 169.498, 162.175, 180.128, 164.658, 171.657, 171.886, 161.493, 171.347),
system = c(38.392, 37.908, 25.346, 32.074, 44.024, 29.587, 37.866, 42.14, 24.528, 28.422, 31.972, 31.613, 44.001, 43.693, 38.323, 47.393, 38.826, 32.465, 38.916, 39.922, 38.14, 54.737, 35.629, 38.51, 41.994, 47.235, 38.2, 24.551, 38.394, 36.903, 45.185, 34.983, 39.039, 34.932, 34.183, 37.758),
elapsed = c(212.973, 210.651, 175.883, 202.67, 229.107, 191.692, 204.401, 216.112, 175.948, 109.591, 116.541, 115.455, 136.039, 132, 120.456, 133.262, 132.115, 114.109, 106.004, 102.319, 101.06, 121.899, 101.687, 99.377, 103.531, 113.994, 94.516, 178.883, 123.378, 94.916, 225.331, 116.645, 99.295, 206.836, 113.864, 95.029))
data2$us<-data2$user+data2$system
data2.dt <-
data.table::dcast(data2,
type2 + rank ~ type1,
value.var = c('us', 'elapsed'))
data2.dt<-data2.dt[,c(1:2,3,7,4,8,5,9,6,10)]
sketch = htmltools::withTags(table(class = 'display',
thead(
tr(
th(rowspan = 2, '第几次执行'),
th(rowspan = 2, '节点序号'),
th(rowspan = 1, colspan = 2, '每个节点1个进程'),
th(rowspan = 1, colspan = 2, '每个节点2个进程'),
th(rowspan = 1, colspan = 2, '每个节点3个进程'),
th(rowspan = 1, colspan = 2, '节点进程数不同')
),
tr(lapply(rep(
c('用户+系统', '流逝'), 4
), th))
)))
# 第一组渐变颜色
brks1 <-
quantile(data2.dt[, 3:4], probs = seq(.05, .95, .05), na.rm = TRUE)
clrs1 <-
round(seq(255, 40, length.out = length(brks1) + 1), 0) %>% {
paste0("rgb(255,", ., ",", ., ")")
}
# 第二组渐变颜色
brks2 <-
quantile(data2.dt[, 5:6], probs = seq(.05, .95, .05), na.rm = TRUE)
clrs2 <-
round(seq(255, 40, length.out = length(brks2) + 1), 0) %>% {
paste0("rgb(" , . , ",255,", ., ")")
}
# 第三组渐变颜色
brks3 <-
quantile(data2.dt[, 7:8], probs = seq(.05, .95, .05), na.rm = TRUE)
clrs3 <-
round(seq(255, 40, length.out = length(brks3) + 1), 0) %>% {
paste0("rgb(" , . , ",", ., ",255)")
}
# 第四组渐变颜色
brks4 <-
quantile(data2.dt[, 9:10], probs = seq(.05, .95, .05), na.rm = TRUE)
clrs4 <-
round(seq(255, 40, length.out = length(brks4) + 1), 0) %>% {
paste0("rgb(255,", ., ",", ., ")")
}
datatable(
data2.dt,
rownames = FALSE,
escape = FALSE,
container = sketch,
extensions = 'RowGroup',
options = list(
dom = 't',
pageLength = 9,
scrollY = FALSE,
autoWidth = TRUE,
columnDefs = list(list(
targets = '_all', className = 'dt-center'
))
),
caption = htmltools::tags$caption(
style = 'caption-side: bottom; text-align: left;',
htmltools::p(style = 'font-size:12px;', '注:节点进程数不同只,节点1设置1个进程、节点2设置2个进程、节点3设置3个进程')
)
) |>
formatRound(columns = c(3:10), digits = 0) |>
formatStyle(columns = c(3:4),
backgroundColor = styleInterval(brks1, clrs1)) |>
formatStyle(columns = c(5:6),
backgroundColor = styleInterval(brks2, clrs2)) |>
formatStyle(columns = c(7:8),
backgroundColor = styleInterval(brks3, clrs3)) |>
formatStyle(columns = c(9:10),
backgroundColor = styleInterval(brks4, clrs4))
future:人不翻车我翻车 🔗
键者本来还想继续尝试 future 框架,但是一直错误不断,在翻了翻 future包、doFuture包的更新日志后发现,有些错误在新版本中已经修复,而且新旧版本差异很大。于是乎,键者决定3,就像以前一样先挖坑再说吧。参照https://cran.r-project.org/web/packages/future/vignettes/future-1-overview.html,future 框架可应用于以下场景。
| 名称 | 操作系统 | 描述 |
|---|---|---|
| 同步: | 非并行: | |
| sequential | 全部 | 在当前 R 进程中按顺序(串行)执行代码 |
| 异步: | 并行: | |
| multisession | 全部 | 后台 R 会话(在当前计算机或节点上) |
| multicore | 非 Windows/非 RStudio | 多个分支 R 进程(在当前计算机或节点上) |
| cluster | 全部 | 外部 R 会话(在当前计算机或节点,或连接远程节点) |
| multiprocess | - | 自 future 1.32.0版本已弃用 |
按照键者的理解,multisession 应用于单节点、多个独立并行进程,multicore 应用于单节点、多个分支子进程,而 cluster 应用于多个节点。
在 future 包文档中关于 multicore 函数的小节里提到,在 RStudio 上用会发出警告,键者执行plan(multicore, workers = 3)后真得收到了,哈哈哈:
Warning in supportsMulticoreAndRStudio(…) : [ONE-TIME WARNING] Forked processing (‘multicore’) is not supported when running R from RStudio because it is considered unstable. For more details, how to control forked processing or not, and how to silence this warning in future R sessions, see ?parallelly::supportsMulticore
-
这里本想写的两个字分别是:“小”字去掉右边一点、“小”字去掉左边一点。两个字组成的词语音同“嘀咔”,是比“小”更小的意思。当然啦,可能换个地方这两个字的音就变了。比如我跟小花吐槽打算下班回去炒一盘油麦菜炒腊肉,小花立马质疑一般不都是用藜蒿炒腊肉么?其实我一直还以为是泥蒿呢。小花接着质疑,难道因为湖北人 l n 不分,所以叫做“泥”……(ps小花并不是地图炮,而是真得是这样)话说之前俺整理蔬菜批发价格数据时,其中一步就是把同一品种不同字的蔬菜合并,当时就知道有藜蒿、泥蒿,但是因为 l n 不分,就完全没想到这一点。 ↩︎
-
这里键者想同时比较四九三十六组数据的对比结果,本意是希望能够一目了然地看出,在不同的节点序号下,“用户+系统”与“流逝”的关系到底是大于、等于、小于中的哪一种,以及节点3比节点1和节点2时间花销低。思来想去,没有想到有什么图形可以做到,所以采用了表格的形式来展示。写到最后,俺忽然明白,这个表格里包含的信息较多,更合理的做法应该是拆成两个进行简化,一个在表格内容上仅展示“>/=/<”,仅表现不同情况下“用户+系统”与“流逝”的关系;另一个以节点序号为主,展示节点3与节点1、节点2在时间花销上的差异。 ↩︎
-
服务器上面安装的 R 还是4.0.3版本,对应安装的包的版本也不高。以后有机会升级 R 的话,再安装新版本的 future,然后再学习,这次就不为了并行而并行了。 ↩︎