原起 🔗
大约是从今年开始,喜欢思考的我渐渐将时间和精力从对内心世界的纵向探索转向对外部世界的横向观察,这样的转变并非有意为之,而是自然发生的1。假如以后每年可以读十本书,还能活五十年,那么余生只能读五百本书,但这世上值得阅读的书籍何止五百,那么给想要阅读的书排出个先后顺序是很必要的。在做什么之前,选择把少量业余时间用来先做什么,也是有必要的。年初的时候,我对今年的计划也跟往年一样,因为总觉得自己 R 很菜、分析能力也很差,所以总是优先考虑学习新的技术、工具、方法,或者拓展思维、拓宽视野,但是连自己也搞不清楚到底什么时候开始突然想要停一停学习新东西的脚步,转而尝试用已有的浅薄能力去搜集和分析数据。最有可能的原因是,在与其他人交流的过程中,发现了现阶段的思考方式似乎存在一种缺陷,即对世界的认知停留在想象的层面,也因此基于自身有限认知的思考也显得十分虚浮。
倒也不能说全都是想象,至少有一大半其实是找别人借的。比如,读了《庄子》后沉溺于道家的有无之争,思绪几度飘离生活去寻虚无海、空茫天,唉;读了《中国历代政治得失》后又陷于新的惯性思维,把一切现状问题都往制度上引,撒都可以解释成人事与制度不匹配的锅;又读了些东方、西方哲学史,脑子里更是经常打结;后来读费孝通先生、上野千鹤子女士的书,马上又被社会学的“结构还是主体”问题迷住,从我的个人角度看,总觉得社会学有些地方怪怪的,但又说不出来是哪里怪,只是能感觉到初读惊艳之余也有缺点;中间还翻了翻《统计与真理》,馄饨2未开的思绪也总被确定性与不确定性带跑。更不用说,那些脑子里从小被耕植的儒家思想观念、共产主义理想,还有对万恶的资本主义的惯性批判。都是借的,借的别人的,现成的,不是自己的。因此,不管我开始思考什么问题,脑子里都自然地带上了借来的那些思想的影响,形成了大量的预设立场。
最开始看人口普查数据时,也是带有预设立场的。由于心底里克制不住对“世界正在快速变好”的美好期盼,解读数据时发现残酷现实与美好期盼之间存在很大的偏差,于是迅速陷入对社会现实的失望之中,感到沮丧而不可自拔,开始止不住地钻牛角尖……钻了一些时候发现仅凭自身确实钻不出来,最多只能在情绪波动以后调节情绪使之恢复平静,但根本无法阻止下一次毫无来由的波动诞生。于是乎,我捋了捋自己的问题,将其抛给了脑子比我好使、心地善良、有求必应且有话直说的三水,三水的答案使我停止钻牛角尖了。又经一番曲折,终于跳了出来。
当初借了别人的思想,使我得以相对更快地穿越别人的世界来看我所处的世界。如今遮蔽我双眼和心灵的,正是所借之物,但也不必完全推翻,所借已有所用。只是在分析数据时,先要摒弃原来的那些预设立场,警惕基于想象去分析。可以预见的是,未来的一段时间里,我会经常“精神内耗”,会有多种思想继续在我脑子里搏斗,要是它们打架能让我获益就好了,要是不能反而打结更严重的话……
本文的数据来源仅有两处,中国人口普查年鉴2020和中国2010年人口普查资料,这是我们国家统计局公布的两次全国人口普查的汇总数据。在开始解读数据之前,照例是要先翻翻前人观点的,键者又发现了一个可以免费阅读社会学期刊的网站,中国社会学网,翻着看了一些前人的文章,如孩次结构与中国出生性别比失衡关系研究、出生性别比失衡对我国人口安全的影响等,看完就觉得这个选题已经被说烂了,没撒好说的了3。
导致出生人口性别比失衡的原因大致可总结为以下四点:
-
文化,除开生育时人们本身的性别偏好,传承下来的文化使得人们的思想观念中存在非常强烈的男孩偏好。
-
制度:我们国家此前实施过较为严格的计划生育政策,推崇少生优生,这项政策从制度上限制了人们生育孩子的数量,反而可能加大人们对生育子女的性别偏好。
-
经济:在计划生育政策逐步放开后,育儿的各项成本也成为了育龄夫妇考虑的重要因素,经济压力和对未来发展较为悲观的预期也限制了人们生育孩子的数量,也有可能加大人们对生育子女的性别偏好。
-
科技:快速发展的胎儿性别鉴定技术、和曾经广告烂大街的无痛人流技术也助推了人们将性别偏好付诸实践的可能。
以上四点原因并非单独作用,实则是交互影响。键者本来拟定的分析思路有三:其一,过去如何,现状又如何;其二,思想落后与经济落后是否存在必然的因果关系,经济发展是否能改善出生婴儿性别比失衡问题;其三,在生育率下跌的当下,哪类人群或哪些地区仍然会出现出生性别比失衡的问题。在初步看完数据以后,决定在数据有限的前提下,本文的写作目的以解读数据为主、分析数据为辅,重在对比差异和变化。所搜集整理好的表格数据放在这里,整理后的表格与原始数据来源的表格对应关系如下。
| sheet 表序号 | 对应内容 | 对应来源 |
|---|---|---|
| 1 | 各地区分年龄性别的人口 | 2020:1-5 各地区分年龄、性别的人口 2010:1-7 各地区分年龄、性别的人口 |
| 2 | 各地区分性别、孩次的出生人口 | 2020:6-1 各地区分性别、孩次的出生人口(2019.11.1-2020.10.31) 2020:6-1a 各地区分性别、孩次的出生人口(2019.11.1-2020.10.31)(城市) 2020:6-1b 各地区分性别、孩次的出生人口(2019.11.1-2020.10.31)(镇) 2020:6-1c 各地区分性别、孩次的出生人口(2019.11.1-2020.10.31)(乡村) 2010:6-1 各地区分性别、孩次的出生人口(2009.11.1-2010.10.31) 2010:6-1a 各地区分性别、孩次的出生人口(2009.11.1-2010.10.31)(城市) 2010:6-1b 各地区分性别、孩次的出生人口(2009.11.1-2010.10.31)(镇) 2010:6-1b 各地区分性别、孩次的出生人口(2009.11.1-2010.10.31)(乡村) |
| 3 | 全国按年龄、受教育程度、生育孩次分的育龄妇女人数 | 2020:6-2 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2019.11.1-2020.10.31) 2020:6-2a 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2019.11.1-2020.10.31)(城市) 2020:6-2b 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2019.11.1-2020.10.31)(镇) 2020:6-2c 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2019.11.1-2020.10.31)(乡村) 2010:6-2 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2009.11.1-2010.10.31) 2010:6-2a 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2009.11.1-2010.10.31)(城市) 2010:6-2b 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2009.11.1-2010.10.31)(镇) 2010:6-2b 全国按年龄、受教育程度、生育孩次分的育龄妇女人数(2009.11.1-2010.10.31)(乡村) |
library(echarts4r)
library(data.table)
library(readxl)
library(ghibli) # 吉卜力调色盘
# sheet 1 ,各地区分年龄性别的人口
data1 <-
read_xlsx('data/我国人口普查数据整理2010+2020.xlsx', sheet = 1)
# sheet 2 , 各地区分性别、孩次的出生人口
data2 <-
read_xlsx('data/我国人口普查数据整理2010+2020.xlsx', sheet = 2)
# sheet 3 , 全国按年龄、受教育程度、生育孩次分的育龄妇女人数
data3 <-
read_xlsx('data/我国人口普查数据整理2010+2020.xlsx', sheet = 3)
查看处理数据的 R 代码
# 查看缺失值,缺失值全部填充为0
sapply(data1, function(x)
sum(is.na(x)))
sapply(data2, function(x)
sum(is.na(x)))
for (i in 1:ncol(data2)) {
data2[, i][is.na(data2[, i])] <- 0
}
sapply(data3, function(x)
sum(is.na(x)))
for (i in 1:ncol(data3)) {
data3[, i][is.na(data3[, i])] <- 0
}
# 将 tibble 格式转换为 data.table 格式
data1 <- as.data.table(data1)
data2 <- as.data.table(data2)
data3 <- as.data.table(data3)
# 为了方面后续绘制地图,将地区名称(area)做些替换
mapping <- data.table(
old = c(
"安徽", "北京", "福建", "甘肃", "广东", "广西",
"贵州", "海南", "河北", "河南", "黑龙江", "湖北", "湖南",
"吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏",
"青海", "山东", "山西", "陕西", "上海", "四川", "天津",
"西藏", "新疆", "云南", "浙江", "重庆"
),
new = c(
"安徽省", "北京市", "福建省", "甘肃省", "广东省", "广西壮族自治区",
"贵州省", "海南省", "河北省", "河南省", "黑龙江省", "湖北省", "湖南省",
"吉林省", "江苏省", "江西省", "辽宁省", "内蒙古自治区", "宁夏回族自治区",
"青海省", "山东省", "山西省", "陕西省", "上海市", "四川省", "天津市",
"西藏自治区", "新疆维吾尔自治区", "云南省", "浙江省", "重庆市"
)
)
data1 <- data1[mapping, on = .(area = old), area := new]
#data2 <- data2[mapping, on = .(area = old), area := new]
# 为使坐标轴标签更简洁,将统计时期(year)也做些替换
mapping2 <- data.table(
old = c('2009.11.1-2010.10.31', '2019.11.1-2020.10.31'),
new = c('2009.11-2010.10', '2019.11-2020.10')
)
data2 <- data2[mapping2, on = .(year = old), year := new]
data3 <- data3[mapping2, on = .(year = old), year := new]
# 2010和2020年的受教育程度划分不一致
# 需要将2020年的未上过学和学前教育合并为未上过学,将硕士研究生和博士研究生合并为研究生
data3[education == '学前教育', ]$education <- '未上过学'
data3[age == '学前教育', ]$age <- '未上过学'
data3[education %in% c('博士研究生', '硕士研究生'), ]$education <- '研究生'
data3[age %in% c('博士研究生', '硕士研究生'), ]$age <- '研究生'
data3 <- data3[, by = .(type, year, education, age), .(
`合计` = sum(`合计`),
`生男孩的妇女人数` = sum(`生男孩的妇女人数`),
`生女孩的妇女人数` = sum(`生女孩的妇女人数`),
`一孩小计` = sum(`一孩小计`),
`一孩男` = sum(`一孩男`),
`一孩女` = sum(`一孩女`),
`二孩小计` = sum(`二孩小计`),
`二孩男` = sum(`二孩男`),
`二孩女` = sum(`二孩女`),
`三孩及以上小计` = sum(`三孩及以上小计`),
`三孩及以上男` = sum(`三孩及以上男`),
`三孩及以上女` = sum(`三孩及以上女`)
)]
第一章 人口结构的变化 🔗
本章主要是对分年龄、性别的人口数据进行解读和分析。
1.1.人口年龄结构 🔗
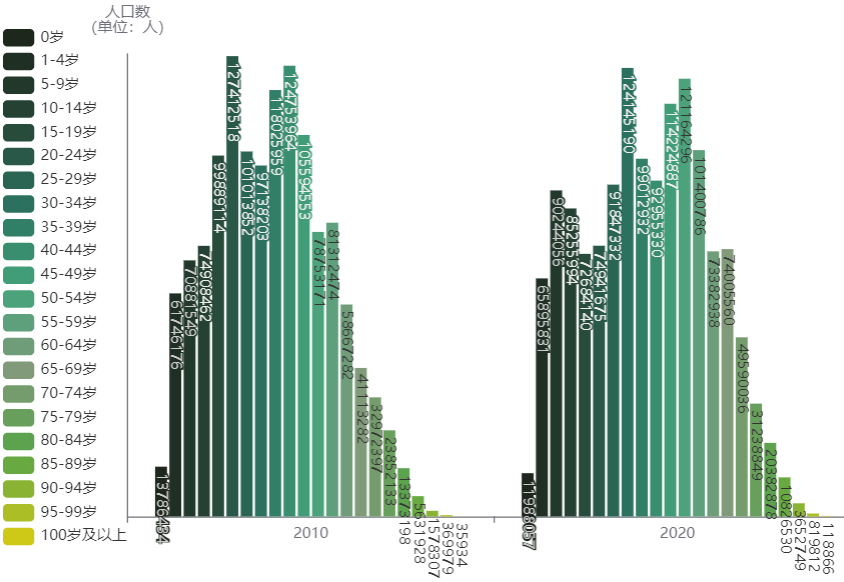
2010年第六次全国人口普查得到全国人口数量为1332810869人,2020年第七次全国人口普查得到全国人口数量为1409778724人,十年时间增加了76967855人,增长率为5.8%。下图是根据两次人口普查数据得到的人口年龄结构图,图中最小的年龄段是0岁,最大的年龄段是100岁及以上,除了1-4岁,将5-99岁划分为每5岁一个年龄段。
在2020年,有两个年龄段35-39岁、40-44岁,和相邻的年龄段连起来看形成了一个波谷。平移到2010年,就是25-29岁、30-34岁,对应的出生年份是1976-1985年,这十年相对于1966-1975年和1986-1990年来说出现了一个生育波谷。这个相对的波谷让键者感到十分诧异,若按照15-49岁为育龄期,可以推算出各年份可以生育的妇女对应的出生年范围,但15-49岁范围太大,键者缩短至15-24岁,那么1966-1975年、1976-1985年、1986-1990年对应的育龄妇女出生年份为1942-1960、1952-1970、1962-1975,这三段妇女出生年份范围之间各有交叉。若要导致1976-1985年的相对生育波谷,键者推算有这几种可能:
- 一是1952-1970年出生且存活下来的妇女人数明显少于另两个年份范围;
- 二是1952-1970年出生的妇女在1976-1985年之间生产的婴儿死亡率明显高于另两个年份范围;
- 三是1952-1970年出生的妇女在1976-1985年之间无法正常怀孕生产的比例明显较高;
- 四是1952-1970年出生的妇女在1976-1985年之间达到了婚育年龄,但是结婚和生育的事情被推迟了。
查看绘图的数据和 R 代码
pal1 <-
ghibli_palette(name = "MarnieMedium2", n = 22, type = "continuous")
data1[area == '全国',] |>
e_charts(year) |>
e_bar(`0岁-小计`, name = '0岁') |>
e_bar(`1-4岁-小计`, name = '1-4岁') |>
e_bar(`5-9岁-小计`, name = '5-9岁') |>
e_bar(`10-14岁-小计`, name = '10-14岁') |>
e_bar(`15-19岁-小计`, name = '15-19岁') |>
e_bar(`20-24岁-小计`, name = '20-24岁') |>
e_bar(`25-29岁-小计`, name = '25-29岁') |>
e_bar(`30-34岁-小计`, name = '30-34岁') |>
e_bar(`35-39岁-小计`, name = '35-39岁') |>
e_bar(`40-44岁-小计`, name = '40-44岁') |>
e_bar(`45-49岁-小计`, name = '45-49岁') |>
e_bar(`50-54岁-小计`, name = '50-54岁') |>
e_bar(`55-59岁-小计`, name = '55-59岁') |>
e_bar(`60-64岁-小计`, name = '60-64岁') |>
e_bar(`65-69岁-小计`, name = '65-69岁') |>
e_bar(`70-74岁-小计`, name = '70-74岁') |>
e_bar(`75-79岁-小计`, name = '75-79岁') |>
e_bar(`80-84岁-小计`, name = '80-84岁') |>
e_bar(`85-89岁-小计`, name = '85-89岁') |>
e_bar(`90-94岁-小计`, name = '90-94岁') |>
e_bar(`95-99岁-小计`, name = '95-99岁') |>
e_bar(`100岁及以上-小计`, name = '100岁及以上') |>
e_color(color = pal1) |>
e_x_axis(type = 'category') |>
e_grid(left = '16%', right = 0) |>
e_labels(
show = TRUE,
rotate = -90,
align = "left",
verticalAlign = "middle",
position = "insideTop",
formatter = '{@[1]}',
rich = list(name = list())
) |>
e_legend(
type = "plain",
# 默认平铺展示
left = "1%",
top = '7%',
orient = "vertical",
# 图例的布局方式,vertical为垂直,horizontal为水平
itemGap = 5
) |>
e_y_axis(
name = '人口数\n(单位:人)',
max = 128000000,
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
axisLabel = list(show = FALSE)
) |>
e_tooltip(trigger = 'item')
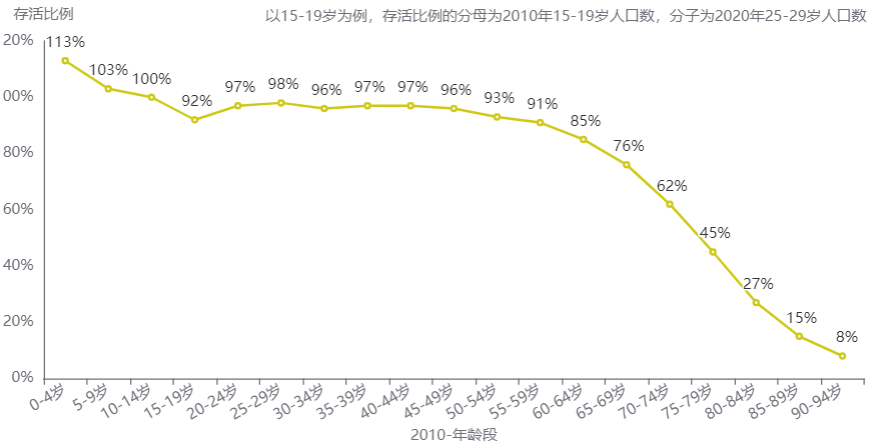
相差十年的两份数据,如果将年龄段错开两段,可以算出2010年各年龄段人口在2020年的存活比例。这条线有明显下降趋势,这代表着一个非常普遍的规律,随着时间流逝,人的年龄不断增长,也是从出生不断走向死亡。在50岁以下的各年龄段存活比例下降较慢,50岁以上的各年龄段存活比例快速下降。于是又出现了令键者暂时想不到如何解读的两点:
-
一是2010年的0岁人口13786434人加上1-4岁人口61746176人等于75532610人,这个数量比2020年10-14岁人口85255994人要少9723384人,这导致计算得到2010年0-4岁人口在十年后的存活比例为113%。
-
二是2010年15-19岁人口在十年后的存活比例仅为92%,明显低于相邻年龄段,这部分人口对应出生年份为1991-1995年。
查看绘图的数据和 R 代码
data <- data.table(
name = c(
'0-4岁',
'5-9岁',
'10-14岁',
'15-19岁',
'20-24岁',
'25-29岁',
'30-34岁',
'35-39岁',
'40-44岁',
'45-49岁',
'50-54岁',
'55-59岁',
'60-64岁',
'65-69岁',
'70-74岁',
'75-79岁',
'80-84岁',
'85-89岁',
'90-94岁'
),
value2010 = c(
75532610,
70881549,
74908462,
99889114,
127412518,
101013852,
97138203,
118025959,
124753964,
105594553,
78753171,
81312474,
58667282,
41113282,
32972397,
23852133,
13373198,
5631928,
1578307
),
value2020 = c(
85255994,
72684140,
74941675,
91847332,
124145190,
99012932,
92955330,
114224887,
121164296,
101400786,
73382938,
74005560,
49590036,
31238849,
20382878,
10826530,
3652749,
819812,
118866
)
)
data[, ':='(prob = round(value2020 / value2010, 2) * 100)] |>
e_charts(name, height = 400) |>
e_line(prob, color = '#CEC917FF') |>
e_y_axis(
name = '存活比例',
max = 120,
formatter = '{value}%',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE)
) |>
e_grid(left = '5%', right = '1%') |>
e_x_axis(
name = '2010-年龄段',
nameLocation = 'center',
nameGap = 40,
nameRotate = 0,
axisLabel = list(interval = 0, rotate = 30)
) |>
e_labels(position = 'top', formatter = '{@[1]}%') |>
e_legend(show = FALSE) |>
e_title(subtext = '以15-19岁为例,存活比例的分母为2010年15-19岁人口数,分子为2020年25-29岁人口数',
right = 0,
top = '5%')
1.2.各年龄段人口性别比 🔗
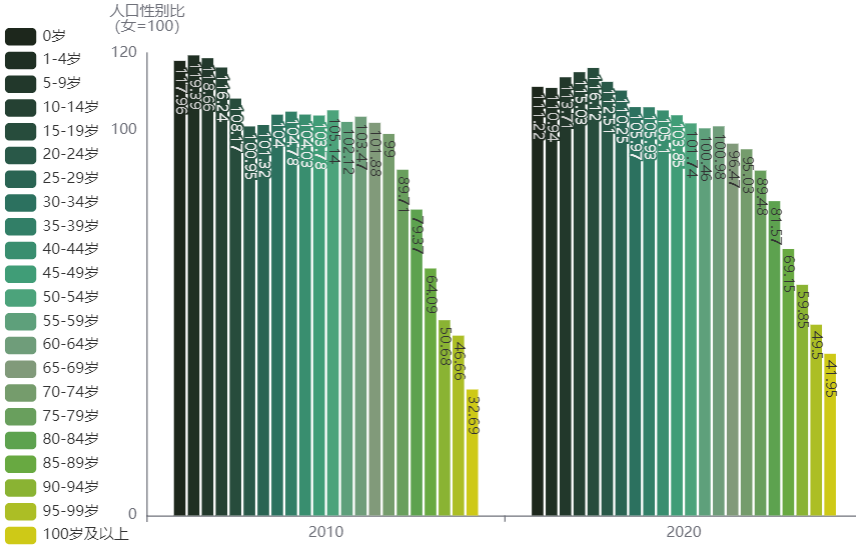
下图是2010年和2020年各年龄段的人口性别比(女=100)。在60岁以上人口中,随着年龄增长,各年龄段的人口性别比呈现下降趋势。在2010年,60岁及以上人口有1.77亿,占全部人口比重的13.3%,性别比(女=100)为96。在2020年,60岁及以上人口有2.64亿,占全部人口比重的18.7%,性别比(女=100)为93。显然,60岁及以上的老年人口性别比低于100,抵消了一部分60岁以下人口的失衡性别比,两个年份全部人口的性别比均为104.8。除此以外,还可以看到以下两个问题。
- 2010年0岁人口的性别比是117.96,2020年0岁人口的性别比是111.22,这说明性别比失衡问题确实有所改善,但也仍未达到与国际社会相比较为正常的水平。
- 仅看2020年的数据,0-29岁的人口性别比均在110以上,说明基于2020年往前推三十年时间里长期存在出生人口性别比失衡的问题。
查看绘图的数据和 R 代码
pal1 <-
ghibli_palette(name = "MarnieMedium2", n = 22, type = "continuous")
data1.add <- data1[, ':='(
prob_all = round(`合计-男` / `合计-女`, 4) * 100,
prob_0 = round(`0岁-男` / `0岁-女`, 4) * 100,
prob_1_4 = round(`1-4岁-男` / `1-4岁-女`, 4) * 100,
prob_5_9 = round(`5-9岁-男` / `5-9岁-女`, 4) * 100,
prob_10_14 = round(`10-14岁-男` / `10-14岁-女`, 4) * 100,
prob_15_19 = round(`15-19岁-男` / `15-19岁-女`, 4) * 100,
prob_20_24 = round(`20-24岁-男` / `20-24岁-女`, 4) * 100,
prob_25_29 = round(`25-29岁-男` / `25-29岁-女`, 4) * 100,
prob_30_34 = round(`30-34岁-男` / `30-34岁-女`, 4) * 100,
prob_35_39 = round(`35-39岁-男` / `35-39岁-女`, 4) * 100,
prob_40_44 = round(`40-44岁-男` / `40-44岁-女`, 4) * 100,
prob_45_49 = round(`45-49岁-男` / `45-49岁-女`, 4) * 100,
prob_50_54 = round(`50-54岁-男` / `50-54岁-女`, 4) * 100,
prob_55_59 = round(`55-59岁-男` / `55-59岁-女`, 4) * 100,
prob_60_64 = round(`60-64岁-男` / `60-64岁-女`, 4) * 100,
prob_65_69 = round(`65-69岁-男` / `65-69岁-女`, 4) * 100,
prob_70_74 = round(`70-74岁-男` / `70-74岁-女`, 4) * 100,
prob_75_79 = round(`75-79岁-男` / `75-79岁-女`, 4) * 100,
prob_80_84 = round(`80-84岁-男` / `80-84岁-女`, 4) * 100,
prob_85_89 = round(`85-89岁-男` / `85-89岁-女`, 4) * 100,
prob_90_94 = round(`90-94岁-男` / `90-94岁-女`, 4) * 100,
prob_95_99 = round(`95-99岁-男` / `95-99岁-女`, 4) * 100,
prob_100 = round(`100岁及以上-男` / `100岁及以上-女`, 4) * 100
)]
data1.add[area == '全国', ] |>
e_charts(year) |>
e_bar(prob_0, name = '0岁') |>
e_bar(prob_1_4, name = '1-4岁') |>
e_bar(prob_5_9, name = '5-9岁') |>
e_bar(prob_10_14, name = '10-14岁') |>
e_bar(prob_15_19, name = '15-19岁') |>
e_bar(prob_20_24, name = '20-24岁') |>
e_bar(prob_25_29, name = '25-29岁') |>
e_bar(prob_30_34, name = '30-34岁') |>
e_bar(prob_35_39, name = '35-39岁') |>
e_bar(prob_40_44, name = '40-44岁') |>
e_bar(prob_45_49, name = '45-49岁') |>
e_bar(prob_50_54, name = '50-54岁') |>
e_bar(prob_55_59, name = '55-59岁') |>
e_bar(prob_60_64, name = '60-64岁') |>
e_bar(prob_65_69, name = '65-69岁') |>
e_bar(prob_70_74, name = '70-74岁') |>
e_bar(prob_75_79, name = '75-79岁') |>
e_bar(prob_80_84, name = '80-84岁') |>
e_bar(prob_85_89, name = '85-89岁') |>
e_bar(prob_90_94, name = '90-94岁') |>
e_bar(prob_95_99, name = '95-99岁') |>
e_bar(prob_100, name = '100岁及以上') |>
e_color(color = pal1) |>
e_x_axis(type = 'category') |>
e_labels(
show = TRUE,
rotate = -90,
align = "left",
verticalAlign = "middle",
position = "insideTop",
formatter = '{@[1]}',
rich = list(name = list())
) |>
e_grid(left = '18%', right = 0) |>
e_legend(
type = "plain",
left = "1%",
top = '7%',
orient = "vertical",
itemGap = 5
) |>
e_y_axis(
name = '人口性别比\n(女=100)',
interval = 100,
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE)
)
1.3.各地区人口数与0岁人口性别比 🔗
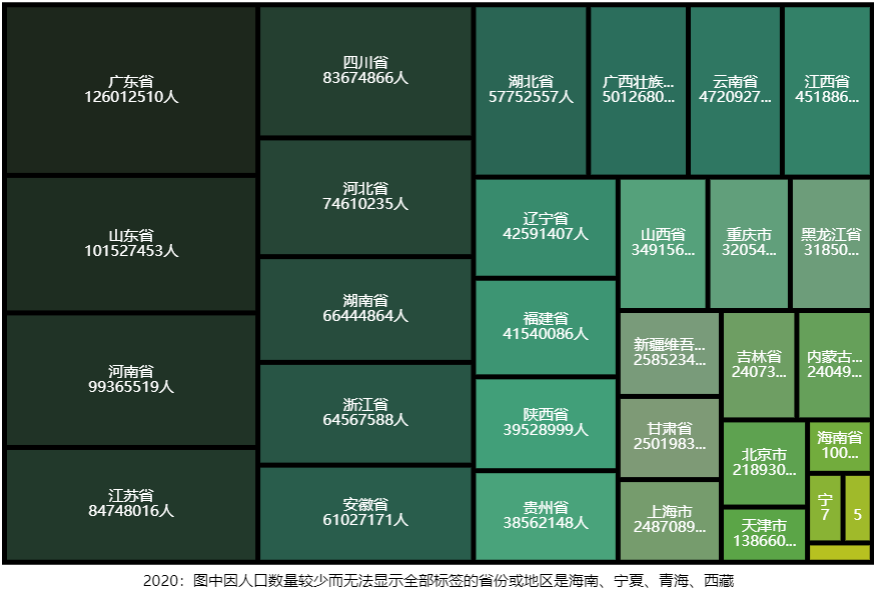
我们国家国土面积很大,由于种种地域因素,人口分布密度并不均衡。根据2020年的人口普查数据,人口最多的广东省有1.26亿人,而人口最少的四个地区海南省1008万人、宁夏回族自治区720万人、青海省592万人、西藏自治区364万人,数量上差距悬殊。同样地,出生人口性别比失衡问题也存在地区间差异。
查看绘图的数据和 R 代码
library(echarts4r)
library(tibble)
pal1 <-
ghibli_palette(name = "MarnieMedium2", n = 32, type = "continuous")
data <- as.tibble(data1.add[year == 2020 & !area %in% c('全国'), 2:3])
colnames(data) <- c('name', 'value')
data |>
e_charts() |>
e_treemap(
width = '100%',
height = '90%',
breadcrumb = list(show = FALSE),
itemStyle = list(borderColor = 'black', borderWidth = 2)
) |>
e_labels(position = 'inside', formatter = '{b}\n{c}人') |>
e_color(color = pal1) |>
e_tooltip(trigger = 'item') |>
e_text_g(
left = 'center',
bottom = 5,
style = list(text = '2020:图中因人口数量较少而无法显示全部标签的省份或地区是海南、宁夏、青海、西藏', fontSize = 12)
)
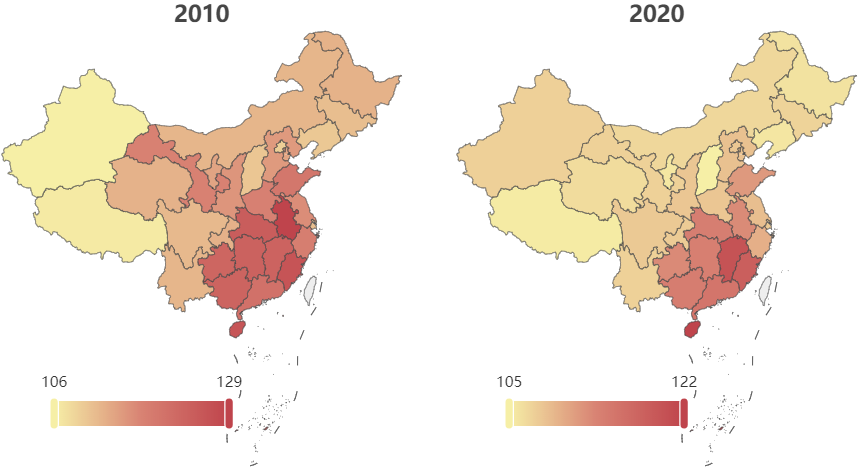
下图是2010年和2020年各地区的0岁人口性别比热力图,出生人口性别比明显存在比较大的地区间差异。在2010年,各地区0岁人口性别比的范围是106-129,而在2020年此范围变为105-122,整体上下降了,具体情况留待后面章节细探。另有一点较为明显的变化是,从地域上看,出生人口性别比失衡问题集中于公鸡腹部的南方省份。
查看绘图的数据和 R 代码
china_map <-
jsonlite::read_json("https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json")
e1 <- data1.add[year == 2020 & !area %in% c('全国'), ] |>
e_charts(area) |> # 区域
# 注册中国地图
e_map_register("China2", china_map) |>
# 将数据映射到地图上
e_map(prob_0, map = "China2", zoom = 1.2) |>
e_visual_map(
prob_0,
calculable = TRUE,
orient = 'horizontal',
left = '10%',
bottom = '20%'
) |>
e_title(text = '2020', left = 'center', top = '10%')
e2 <- data1.add[year == 2010 & !area %in% c('全国'),] |>
e_charts(area) |> # 区域
# 注册中国地图
e_map_register("China2", china_map) |>
# 将数据映射到地图上
e_map(prob_0, map = "China2", zoom = 1.2) |>
e_visual_map(
prob_0,
calculable = TRUE,
orient = 'horizontal',
left = '10%',
bottom = '20%'
) |>
e_title(text = '2010', left = 'center', top = '10%')
e_arrange(e2, e1, cols = 2)
第二章 孩次结构的变化 🔗
本章主要是对分性别、孩次的人口数据进行解读和分析。
2.1.孩次结构 🔗
除了地区间差异,出生人口性别比失衡问题还存在分孩次的差异,以及城乡之间的差异。在两次全国人口普查数据中,其中生育章节有单独列出两个时间段的数据,2010年列出了2009.11.1-2010.10.31的数据,2020年列出了2019.11.1-2020.10.31的数据,单独列出的这部分数据中,出生人数合计的数据量级均为百万级,和当年出生人口的千万量级存在差异,因此键者认为两个时间段的数据事实上是抽样调查数据。
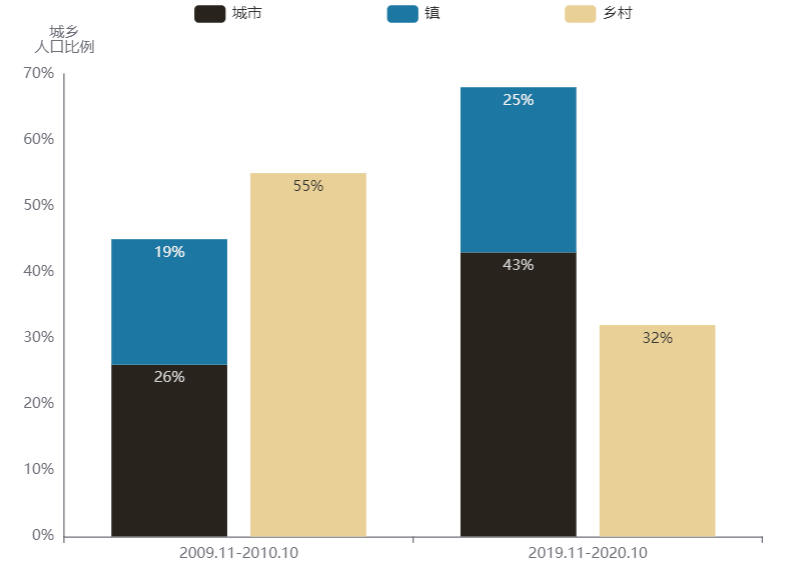
自2010至2020年的十年时间里,我们国家的生育政策出现了较大的转变,2016年起全面放开了二胎生育。除此以外,我们国家的户籍制度也经历了几番改革,城乡人口结构也发生了很大变化。因此,在解读城乡之间的孩次结构变化之前,需要先看看城乡结构本身发生的变化。根据键者之前在耕地面积和留守人口中的一些分析,自2006年至2016年,城镇和乡村的人口比例由44:56变为59:41,按照城镇化率不断提高的趋势,相比2010年,2020年的城镇人口比例理应上升,且高过59:41。下图是依据两个时间段的数据所计算的城市、镇、乡村的人口比例,2010年的城镇乡村人口比例为45:55,至2020年上升至68:32,符合城镇化率提升的基本规律。因此,键者也认为两时间段抽样数据比例基本符合全国的城镇乡村人口比例。
查看绘图的数据和 R 代码
data <- data.table(
year = c('2009.11-2010.10', '2019.11-2020.10'),
city = c(315041, 520301),
town = c(224849, 299692),
village = c(650170, 392328),
all = c(1190060, 1212321))
pal2 <-
ghibli_palette(name = "MarnieMedium1", n = 3, type = "continuous")
data[, ':='(
prob_city = round(city / all, 2) * 100,
prob_town = round(town / all, 2) * 100,
prob_village = round(village / all, 2) * 100
)] |>
e_charts(year) |>
e_bar(prob_city,
name = '城市',
stack = 'gro') |>
e_bar(prob_town,
name = '镇',
stack = 'gro') |>
e_bar(prob_village, name = '乡村') |>
e_color(color = pal2) |>
e_labels(position = 'insideTop', formatter = '{@[1]}%') |>
e_y_axis(
name = '城乡\n人口比例',
formatter = '{value}%',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE)
) |>
e_legend(itemGap = 100)
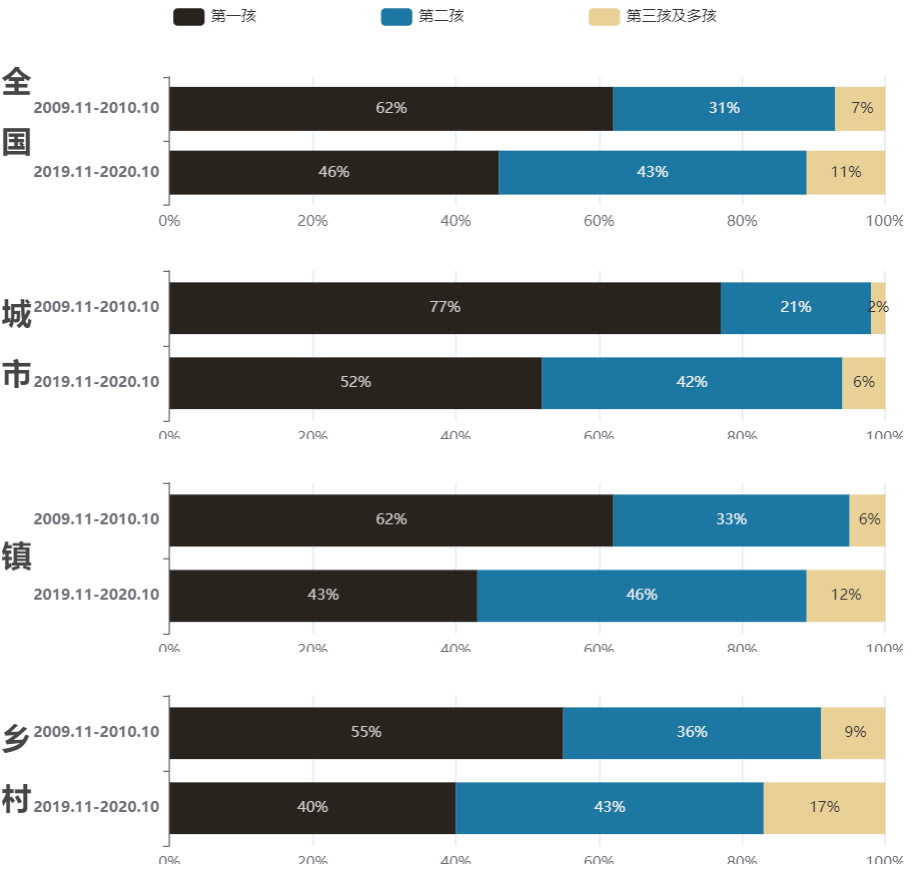
从孩次结构上看,二孩和多孩的比例增加,自然就造成一孩的比例减少,这是一种挤压效应。表面上看是二孩及多孩比例上升、一孩比例下降,其实也间接反映出政策变化前后,人们生育二孩及多孩的需求得到了释放,由于一孩的增长数量低于二孩及多孩的增长数量,生育一孩的增长量不足造成了结构上的“被挤压”。对比2009.11-2010.10和2019.11-2020.10两个时间段的数据,在全国的层面上,一孩比例下降16%,二孩比例上升12%,这样的转变使得在2019.11-2020.10这个时间段内一孩比例和二孩比例仅相差3%。但不区分城乡的全国数据,显然是一个平均数,“平均”了城乡之间的差异。若区分城乡,从城市、镇、乡村的数据分开来看,镇的孩次结构变化与全国的变化最为接近,乡村次之,城市的变化情况与全国差异最大。
-
在乡村层面,在2009.11-2020.10时间段内,二孩、三孩及多孩的比例本来就高于全国水平,因而到了2019.11-2020.10时间段内,二孩比例上升7%,三孩及多孩比例上升8%,共同造成了一孩比例下降15%。
-
在城市层面,在2009.11-2020.10时间段内,一孩比例远高于全国水平,二孩、三孩及多孩的比例本来就低于全国水平,因而到了2019.11-2020.10时间段内,二孩比例上升21%,三孩及多孩比例上升4%,共同造成了一孩比例下降25%。
相对乡村来说,城市层面上导致孩次结构变化的主要因素在于二孩的比例提升。即便是全面放开二胎生育后,城市里一孩比例仍旧比二孩比例高出10%。
查看绘图的数据和 R 代码
data2.add <- data2[, ':='(
`第三孩及多孩-小计` = `出生人数-合计` - `第一孩-小计` - `第二孩-小计`,
`第三孩及多孩-男` = (`出生人数-男` - `第一孩-男` - `第二孩-男`),
`第三孩及多孩-女` = (`出生人数-女` - `第一孩-女` - `第二孩-女`),
`第三孩及多孩-性别比(女=100)` = round((`出生人数-男` - `第一孩-男` - `第二孩-男`) / (`出生人数-女` -
`第一孩-女` - `第二孩-女`), 4) * 100
)][, ':='(
prob_1 = round(`第一孩-小计` / `出生人数-合计`, 2) * 100,
prob_2 = round(`第二孩-小计` / `出生人数-合计`, 2) * 100,
prob_3 = round(`第三孩及多孩-小计` / `出生人数-合计`, 2) * 100
)]
pal2 <-
ghibli_palette(name = "MarnieMedium1", n = 3, type = "continuous")
e1 <- data2.add[type == '不分城乡' & area == '全国',] |>
e_charts(year, height = 180) |>
e_bar(prob_1, stack = 'group', name = '第一孩') |>
e_bar(prob_2, stack = 'group', name = '第二孩') |>
e_bar(prob_3, stack = 'group', name = '第三孩及多孩') |>
e_y_axis(formatter = '{value}%') |>
e_x_axis(axisLabel = list(fontWeight = 'bold')) |>
e_color(color = pal2) |>
e_flip_coords() |>
e_labels(position = 'inside', formatter = '{@[0]}%') |>
e_grid(left = '20%', right = '2%',bottom='10%') |>
e_title(
text = '全\n\n国',
left = '1%',
top = 'center',
textStyle = list(fontSize = 24)
) |>
e_legend(itemGap = 100)
e2 <- data2.add[type == '城市' & area == '全国',] |>
e_charts(year, height = 150) |>
e_bar(prob_1, stack = 'group', name = '第一孩') |>
e_bar(prob_2, stack = 'group', name = '第二孩') |>
e_bar(prob_3, stack = 'group', name = '第三孩及多孩') |>
e_y_axis(formatter = '{value}%') |>
e_x_axis(axisLabel = list(fontWeight = 'bold')) |>
e_color(color = pal2) |>
e_flip_coords() |>
e_labels(position = 'inside', formatter = '{@[0]}%') |>
e_grid(
left = '20%',
right = '2%',
bottom = '10%',
top = '10%'
) |>
e_title(
text = '城\n\n市',
left = '1%',
top = 'center',
textStyle = list(fontSize = 24)
) |>
e_legend(show = FALSE)
e3 <- data2.add[type == '镇' & area == '全国', ] |>
e_charts(year, height = 150) |>
e_bar(prob_1, stack = 'group', name = '第一孩') |>
e_bar(prob_2, stack = 'group', name = '第二孩') |>
e_bar(prob_3, stack = 'group', name = '第三孩及多孩') |>
e_y_axis(formatter = '{value}%',
min = 0,
max = 100) |>
e_x_axis(axisLabel = list(fontWeight = 'bold')) |>
e_color(color = pal2) |>
e_flip_coords() |>
e_labels(position = 'inside', formatter = '{@[0]}%') |>
e_grid(
left = '20%',
right = '2%',
bottom = '10%',
top = '10%'
) |>
e_title(
text = '镇',
left = '1%',
top = 'center',
textStyle = list(fontSize = 24)
) |>
e_legend(show = FALSE)
e4 <- data2.add[type == '乡村' & area == '全国',] |>
e_charts(year, height = 150) |>
e_bar(prob_1, stack = 'group', name = '第一孩') |>
e_bar(prob_2, stack = 'group', name = '第二孩') |>
e_bar(prob_3, stack = 'group', name = '第三孩及多孩') |>
e_y_axis(formatter = '{value}%') |>
e_x_axis(axisLabel = list(fontWeight = 'bold')) |>
e_color(color = pal2) |>
e_flip_coords() |>
e_labels(position = 'inside', formatter = '{@[0]}%') |>
e_grid(
left = '20%',
right = '2%',
bottom = '10%',
top = '10%'
) |>
e_title(
text = '乡\n\n村',
left = '1%',
top = 'center',
textStyle = list(fontSize = 24)
) |>
e_legend(show = FALSE)
e_arrange(e1, e2, e3, e4, cols = 1)
2.2.城乡之间分孩次性别比 🔗
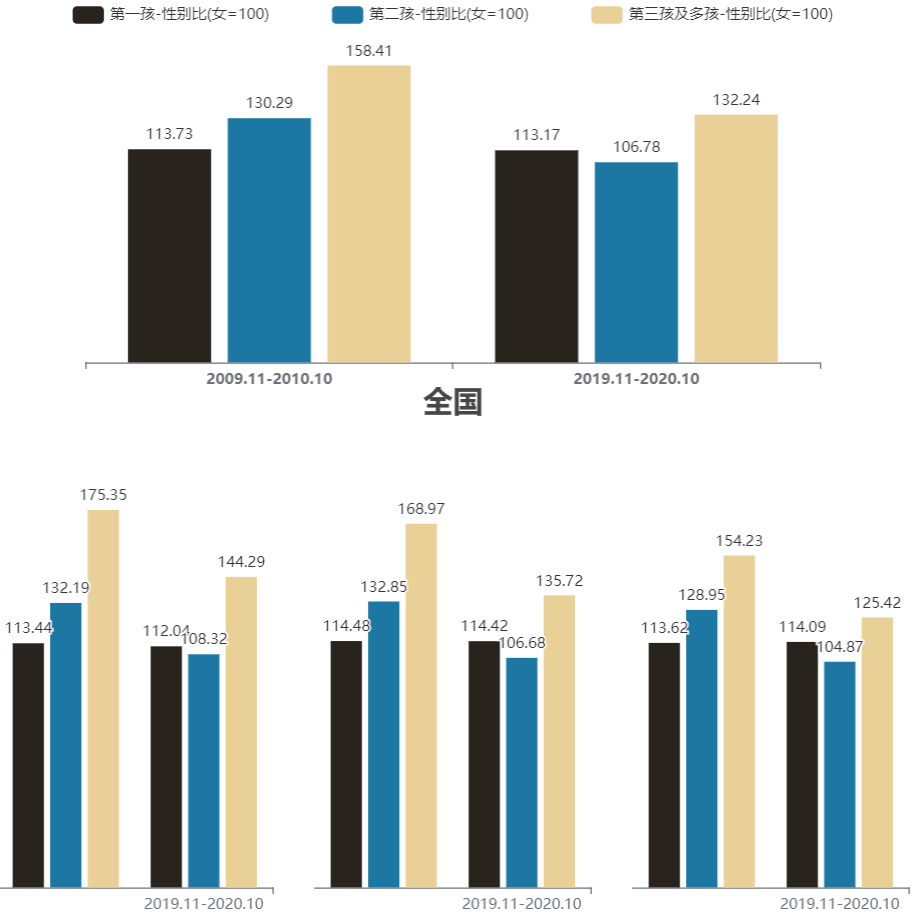
依据上一小节对孩次结构数据的解读,可以知道不论是在2009.11-2010.10还是在2019.11-2020.10,也不论是城镇还是乡村,一孩和二孩所占比例较大,至少超过80%,而三孩及多孩比重较小。跨过十年的时间,孩次结构上最大的变化是人们生育二孩的需求得到了释放。
若从全国层面上看两个年份的分孩次性别比,第一孩的性别比基本维持在113,第二孩的性别比从130.29下降到106.78,第三孩及多孩的性别比从158.41下降到132.24。显然,第三孩及多孩的性别比仍然维持在极端失衡的水平。再从城市、镇、乡村层面看,整体变化趋势与全国一致,但有一点值得注意,不论是以下哪个年份,乡村的二孩和三孩及多孩的性别比都比城市、镇略低。一般来讲,城、镇相对乡村来说经济更发达,但从数据表现来看城、镇的男孩偏好也比乡村略重。关于这点,键者的个人理解是,乡村的生育结构相对城、镇更加均衡,二孩、三孩及多孩的比重都比城、镇更高,在生育数量上的限制更轻,因而男孩偏好也更轻。
查看绘图的数据和 R 代码
pal2 <-
ghibli_palette(name = "MarnieMedium1", n = 3, type = "continuous")
e1 <- data2.add[type == '不分城乡' & area == '全国',] |>
e_charts(year, height = 400) |>
e_bar(`第一孩-性别比(女=100)`) |>
e_bar(`第二孩-性别比(女=100)`) |>
e_bar(`第三孩及多孩-性别比(女=100)`) |>
e_color(color = pal2) |>
e_x_axis(inverse = TRUE) |>
e_x_axis(axisLabel = list(fontWeight = 'bold')) |>
e_labels(position = 'top') |>
e_y_axis(show = FALSE) |>
e_legend(itemGap = 50, top = '10%') |>
e_title(
text = '全国',
left = 'center',
bottom = '5%',
textStyle = list(fontSize = 24)
)
e2 <- data2.add[type == '城市' & area == '全国',] |>
e_charts(year, height = 400) |>
e_bar(`第一孩-性别比(女=100)`) |>
e_bar(`第二孩-性别比(女=100)`) |>
e_bar(`第三孩及多孩-性别比(女=100)`) |>
e_color(color = pal2) |>
e_x_axis(inverse = TRUE) |>
e_labels(position = 'top') |>
e_y_axis(show = FALSE, max = 180) |>
e_legend(show = FALSE) |>
e_title(
text = '城市',
left = 'center',
bottom = '2%',
textStyle = list(fontSize = 24)
) |>
e_grid(left = '1%', right = '1%', top = '5%')
e3 <- data2.add[type == '镇' & area == '全国',] |>
e_charts(year, height = 400) |>
e_bar(`第一孩-性别比(女=100)`) |>
e_bar(`第二孩-性别比(女=100)`) |>
e_bar(`第三孩及多孩-性别比(女=100)`) |>
e_color(color = pal2) |>
e_x_axis(inverse = TRUE) |>
e_labels(position = 'top') |>
e_y_axis(show = FALSE, max = 180) |>
e_legend(show = FALSE) |>
e_title(
text = '镇',
left = 'center',
bottom = '2%',
textStyle = list(fontSize = 24)
) |>
e_grid(left = '1%', right = '1%', top = '5%')
e4 <- data2.add[type == '乡村' & area == '全国',] |>
e_charts(year, height = 400) |>
e_bar(`第一孩-性别比(女=100)`) |>
e_bar(`第二孩-性别比(女=100)`) |>
e_bar(`第三孩及多孩-性别比(女=100)`) |>
e_color(color = pal2) |>
e_x_axis(
inverse = TRUE,
axisLable = list(
interval = 0,
overflow = 'break',
fontSize = 10
)
) |>
e_labels(position = 'top') |>
e_y_axis(show = FALSE, max = 180) |>
e_legend(show = FALSE) |>
e_title(
text = '乡村',
left = 'center',
bottom = '2%',
textStyle = list(fontSize = 24)
) |>
e_grid(left = '1%', right = '1%', top = '5%')
e234 <- e_arrange(e2, e3, e4, cols = 3)
e_arrange(e1, e234, cols = 1)
2.3.各地区分孩次性别比 🔗
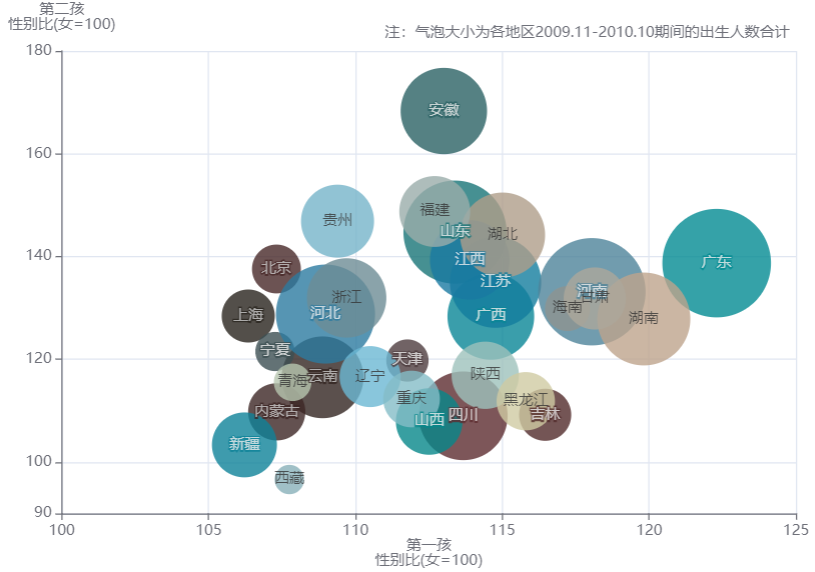
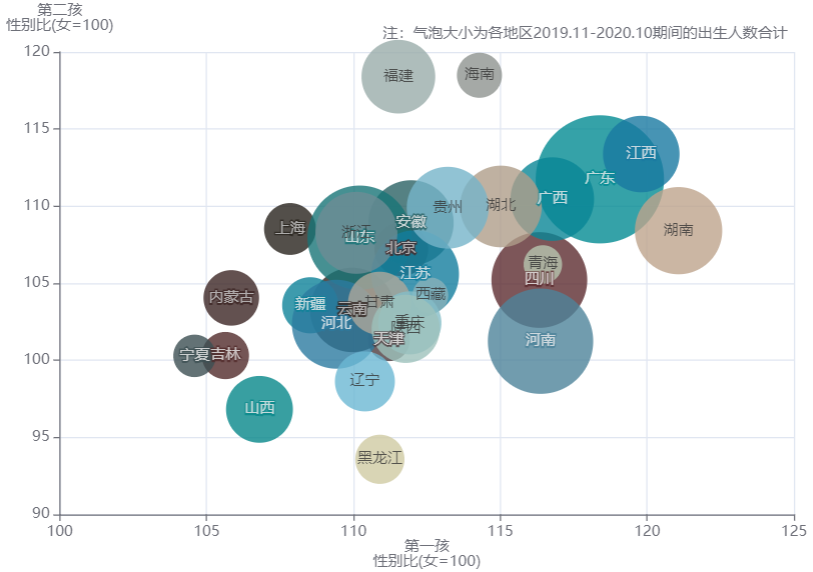
在第1.3小节中,键者曾得到结论,对比2010年和2020年的数据,出生人口性别比下降了。本小节即基于此详细展开,下图是两幅气泡散点图,上面是2009.11-2010.10的数据,下面是2019.11-2020.10的数据,横轴是各省份第一孩性别比(女=100),纵轴是第二孩性别比(女=100),气泡的大小是出生人口数。为了方便进行纵向视角上的对比,键者将两幅图的横轴范围起点均设定为100,纵轴范围起点同为90。如果将散点图中两个点(100,100)和(120,120)相连并延长,可知上图中多数气泡在此线上方,下图中多数气泡在此线下方,这说明从整体上看,大部分省份的生育男孩偏好发生了孩次结构上的转移,从第二孩转移到了第一孩。
-
在2009.11-2010.10时间段内,31个省份或地区中,25个省份或地区的第二孩性别比更高,仅有黑龙江、吉林、山西、四川、新疆、西藏等一孩性别比高于二孩性别比。而在2019.11-2020.10时间段内,整体情况发生逆转,有28个省份或地区第一孩性别比更高,仅有上海、福建、海南等二孩性别比高于一孩性别比。
-
在2009.11-2010.10期间,一孩、二孩性别比差距最大的前三个省份如下。
- 安徽,一孩性别比113.01,,二孩性别比168.32;
- 贵州,一孩性别比109.39,二孩性别比146.89;
- 福建,一孩性别比112.7,二孩性别比148.77。
-
在2019.11-2020.10期间,一孩、二孩性别比差距最大的前三个省份如下。
- 黑龙江,一孩性别比110.9,二孩性别比93.58;
- 河南,一孩性别比116.37,二孩性别比101.24;
- 湖南,一孩性别比121.07,二孩性别比108.41。
查看绘图的数据和 R 代码
pal3 <-
ghibli_palette(name = "MarnieMedium1", n = 32, type = "continuous")
e1 <- data2.add[year == '2009.11-2010.10' &
!area %in% c('全国') &
type == '不分城乡', ] |>
group_by(area) |>
e_charts(`第一孩-性别比(女=100)`) |>
e_scatter(
serie = `第二孩-性别比(女=100)`,
size = `出生人数-合计`,
itemStyle = list(opacity = 0.8),
scale_js = "function(data){ return 110*(Math.sqrt(data[2]/ 2e5) + 0.1);}",
label = list(
show = TRUE,
formatter = '{a}',
position = 'inside'
),
emphasis = list(focus = "self")
) |>
e_legend(show = FALSE) |>
e_x_axis(
min = 100,
name = '第一孩\n性别比(女=100)',
nameLocation = 'center',
nameGap = 20
) |>
e_y_axis(min = 90, name = '第二孩\n性别比(女=100)') |>
e_color(color = pal3) |>
e_title(subtext = '注:气泡大小为各地区2009.11-2010.10期间的出生人数合计',
top = '5%',
right = '10%') |>
# 增加十字准星的坐标轴指示器
e_tooltip(
trigger = "item",
formatter = htmlwidgets::JS(
"function(params){
return('地区:' +
'<br />第一孩性别比: ' + params.value[0] +
'<br />第二孩性别比: ' + params.value[1])}"
), axisPointer = list(type = "cross"))
e2 <- data2.add[year == '2019.11-2020.10' &
!area %in% c('全国') &
type == '不分城乡',] |>
group_by(area) |>
e_charts(`第一孩-性别比(女=100)`) |>
e_scatter(
serie = `第二孩-性别比(女=100)`,
size = `出生人数-合计`,
itemStyle = list(opacity = 0.8),
scale_js = "function(data){ return 110*(Math.sqrt(data[2]/ 2e5) + 0.1);}",
label = list(
show = TRUE,
formatter = '{a}',
position = 'inside'
),
emphasis = list(focus = "self")
) |>
e_legend(show = FALSE) |>
e_x_axis(
min = 100,
name = '第一孩\n性别比(女=100)',
nameLocation = 'center',
nameGap = 20
) |>
e_y_axis(min = 90, name = '第二孩\n性别比(女=100)') |>
e_color(color = pal3) |>
e_title(subtext = '注:气泡大小为各地区2019.11-2020.10期间的出生人数合计',
top = '5%',
right = '10%')|>
# 增加十字准星的坐标轴指示器
e_tooltip(
trigger = "item",
formatter = htmlwidgets::JS(
"function(params){
return('地区:' +
'<br />第一孩性别比: ' + params.value[0] +
'<br />第二孩性别比: ' + params.value[1])}"
), axisPointer = list(type = "cross"))
e_arrange(e1, e2, cols = 1)
第三章 生育妇女人群的差异 🔗
本章主要是对分全国按年龄、受教育程度、生育孩次分的育龄妇女人群特征进行解读和分析。
3.1.人群基本结构的变化 🔗
本小节着重比对育龄妇女人群的城乡、年龄、受教育程度等特征在两个时间段的变化。
3.1.1.城乡 🔗
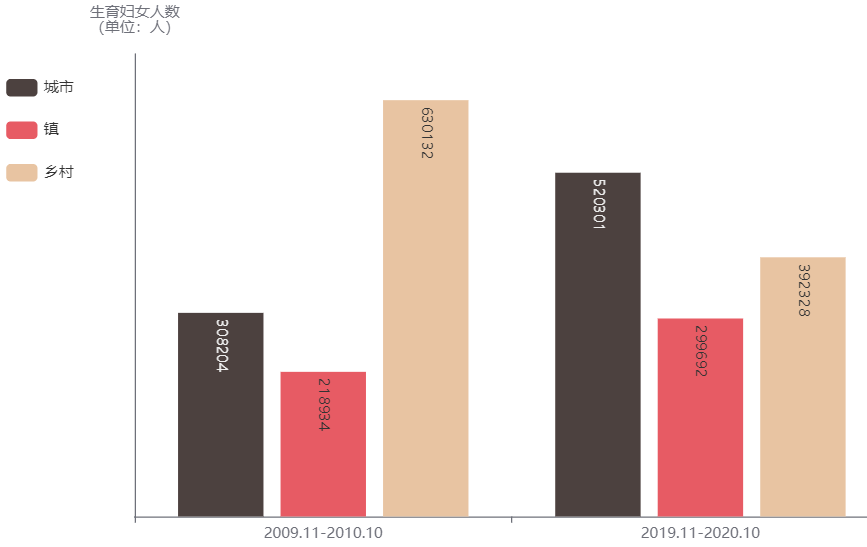
本数据中,在2009.11-2010.10期间抽样统计的妇女人数为1157270人,而在2019.11-2020.10期间为1212321人。按城乡结构看,生育妇女的基本结构由乡村>城市>镇变成了城市>乡村>镇,与城乡人口结构的变化一致。
查看绘图的数据和 R 代码
pal5 <-
ghibli_palette(name = "PonyoMedium", n = 3, type = "continuous")
dcast(data3[type %in% c('城市', '镇', '乡村') &
education == '不区分' &
age %in% c('总计'),],
year ~ type, value.var = '合计') |>
e_charts(year) |>
e_bar(`城市`) |>
e_bar(`镇`) |>
e_bar(`乡村`) |>
e_color(color = pal5) |>
e_labels(
show = TRUE,
rotate = -90,
align = "left",
verticalAlign = "middle",
position = "insideTop",
formatter = '{@[1]}',
rich = list(name = list())
) |>
e_grid(left = '16%', right = 0) |>
e_legend(
type = "plain",
# 默认平铺展示
left = "1%",
top = '15%',
itemGap = 20,
orient = "vertical"
) |>
e_y_axis(
name = '生育妇女人数\n(单位:人)',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
axisLabel = list(show = FALSE)
) |>
e_tooltip(trigger = 'item')
3.1.2.年龄 🔗
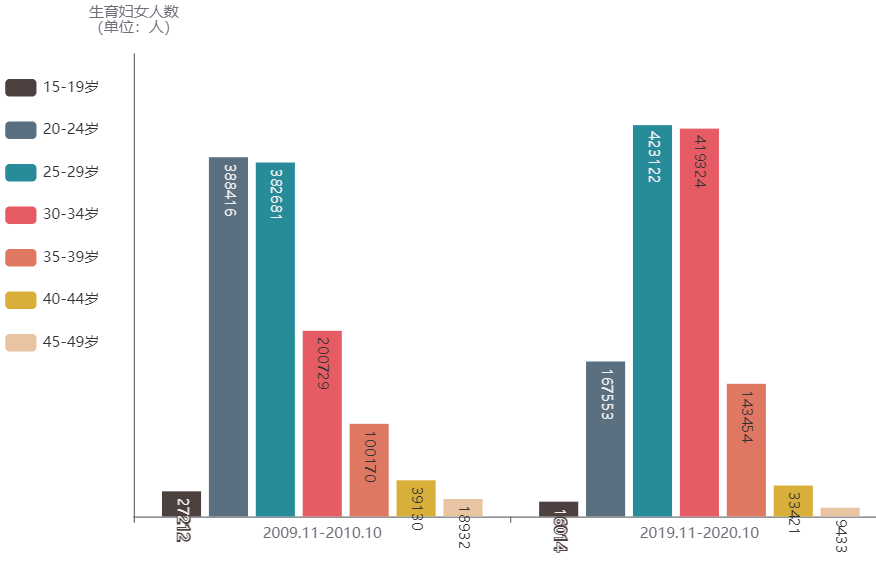
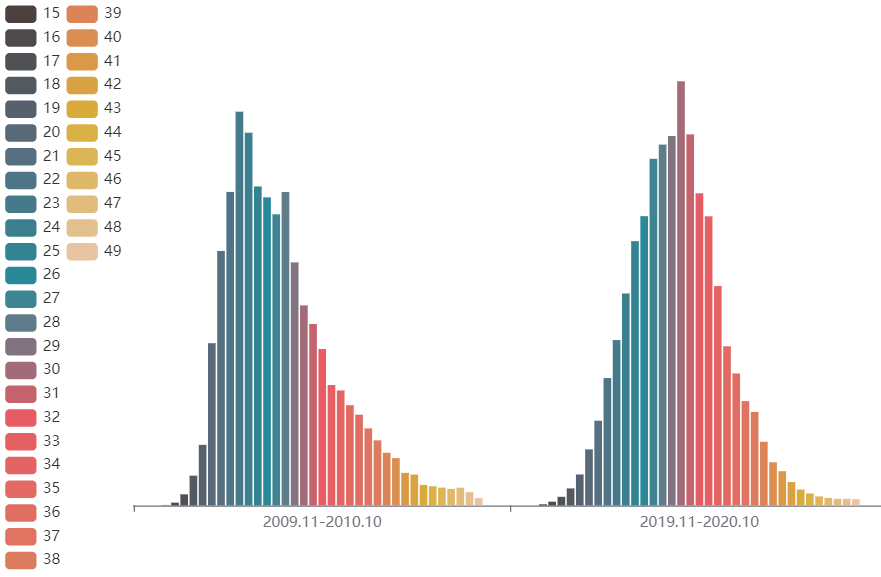
按年龄结构看,在2009.11-2010.10期间,生育妇女的年龄集中在20-29岁,而在2019.11-2020.10期间,生育妇女的年龄集中在25-34岁。
查看绘图的数据和 R 代码
pal4 <-
ghibli_palette(name = "PonyoMedium", n = 7, type = "continuous")
data3[type == '不分城乡' &
education == '不区分' &
age %in% c('15-19岁',
'20-24岁',
'25-29岁',
'30-34岁',
'35-39岁',
'40-44岁',
'45-49岁'), ] |>
group_by(age) |>
e_charts(year) |>
e_bar(`合计`) |>
e_x_axis(inverse = TRUE) |>
e_color(color = pal4) |>
e_labels(
show = TRUE,
rotate = -90,
align = "left",
verticalAlign = "middle",
position = "insideTop",
formatter = '{@[1]}',
rich = list(name = list())
) |>
e_grid(left = '16%', right = 0) |>
e_legend(
type = "plain",
# 默认平铺展示
left = "1%",
top = '15%',
itemGap = 20,
orient = "vertical"
) |>
e_y_axis(
name = '生育妇女人数\n(单位:人)',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
axisLabel = list(show = FALSE)
) |>
e_tooltip(trigger = 'item')
若不按年龄段看,按具体年龄看,在2009.11-2010.10期间,生育妇女人数最多的年龄是23岁,而在2019.11-2020.10期间,生育妇女人数最多的年龄是30岁。
查看绘图的数据和 R 代码
pal4 <-
ghibli_palette(name = "PonyoMedium", n = 35, type = "continuous")
data3[type == '不分城乡' &
education == '不区分' &
!age %in% c('15-19岁',
'20-24岁',
'25-29岁',
'30-34岁',
'35-39岁',
'40-44岁',
'45-49岁',
'总计'),] |>
group_by(age) |>
e_charts(year) |>
e_bar(`合计`) |>
e_x_axis(inverse = TRUE) |>
e_color(color = pal4) |>
e_tooltip(trigger = 'item') |>
e_grid(left = '16%', right = 0) |>
e_legend(
type = "plain",
# 默认平铺展示
left = "1%",
top = '5%',
itemGap = 5,
orient = "vertical"
) |>
e_y_axis(show = FALSE)
3.1.3.受教育程度 🔗
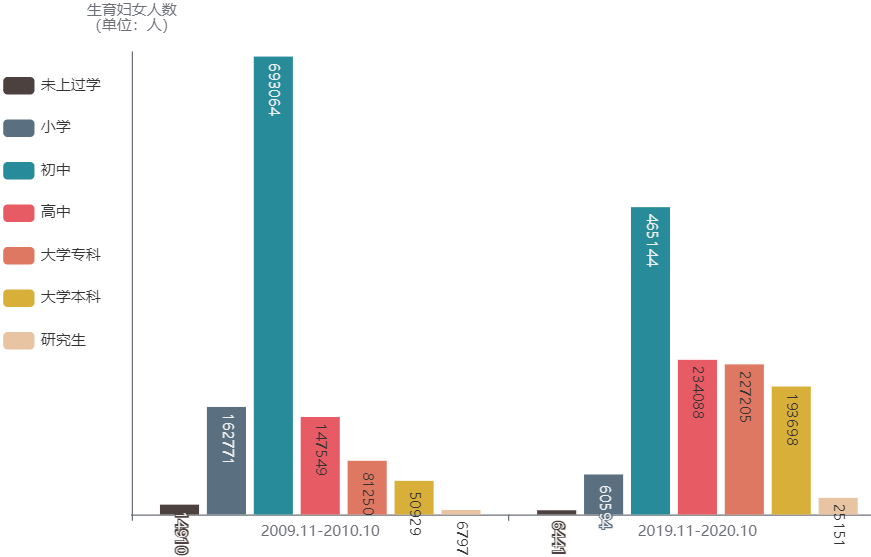
按受教育程度看,在2009.11-2010.10期间,受教育程度为初中的妇女人数最多,占59.8%;在2019.11-2020.10期间,受教育程度为初中的妇女人数依然最多,但比例下降到了38.4%,同时受教育程度分别为高中、大学专科、大学本科的妇女所占比例有相对较大的提升,对应分别从12.7%、7.0%、4.4%上升到了19.3%、18.7%、13.5%。
查看绘图的数据和 R 代码
pal5 <-
ghibli_palette(name = "PonyoMedium", n = 7, type = "continuous")
dcast(data3[type == '不分城乡' &
age %in% c('未上过学', '小学', '初中', '高中', '大学专科', '大学本科', '研究生'), ], type +
year ~ age, value.var = '合计') |>
e_charts(year) |>
e_bar(`未上过学`) |>
e_bar(`小学`) |>
e_bar(`初中`) |>
e_bar(`高中`) |>
e_bar(`大学专科`) |>
e_bar(`大学本科`) |>
e_bar(`研究生`) |>
e_color(color = pal5) |>
e_labels(
show = TRUE,
rotate = -90,
align = "left",
verticalAlign = "middle",
position = "insideTop",
formatter = '{@[1]}',
rich = list(name = list())
) |>
e_grid(left = '16%', right = 0) |>
e_legend(
type = "plain",
# 默认平铺展示
left = "1%",
top = '15%',
itemGap = 20,
orient = "vertical"
) |>
e_y_axis(
name = '生育妇女人数\n(单位:人)',
splitLine = list(show = FALSE),
axisLine = list(show = TRUE),
axisTick = list(show = FALSE),
axisLabel = list(show = FALSE)
) |>
e_tooltip(trigger = 'item')
3.2.生育一孩和生育二孩的人群差异(有待完善) 🔗
在2009.11-2010.10的抽样数据中,生育一孩、二孩、三孩及以上的妇女人数分别为717707:363978:75585,换算成比例即为62:31:7。而在2019.11-2020.10的抽样数据中,生育一孩、二孩、三孩及以上的妇女人数分别为555030:522301:134990,换算成比例为46:43:11。由于此前已较为充分了比对了两个时间段人群结构上的变化,本小节将关注的重点转移到2019.11-2020.10这一范围中生育人群内部的差异。
查看本小节处理数据的 R 代码
data <- data3[type %in% c('城市', '镇', '乡村') &
education %in% c('未上过学', '小学', '初中', '高中', '大学专科', '大学本科', '研究生') &
age %in% c('15-19岁',
'20-24岁',
'25-29岁',
'30-34岁',
'35-39岁',
'40-44岁',
'45-49岁'), ]
data.boy <-
melt(
data,
id = c("year", "type", "age", "education"),
measure.vars = c("一孩男" , "二孩男"),
variable.name = "order",
value.name = "boyNum"
)
data.girl <-
melt(
data,
id = c("year", "type", "age", "education"),
measure.vars = c("一孩女" , "二孩女"),
variable.name = "order",
value.name = "girlNum"
)
data.boy[order == '一孩男', ]$order <- '一孩'
data.boy[order == '二孩男', ]$order <- '二孩'
data.girl[order == '一孩女', ]$order <- '一孩'
data.girl[order == '二孩女', ]$order <- '二孩'
data <-
data.boy[data.girl, on = c("year", "type", "age", "education", "order")][, ':='(allNum = boyNum + girlNum)]
3.2.1.城乡和受教育程度 🔗
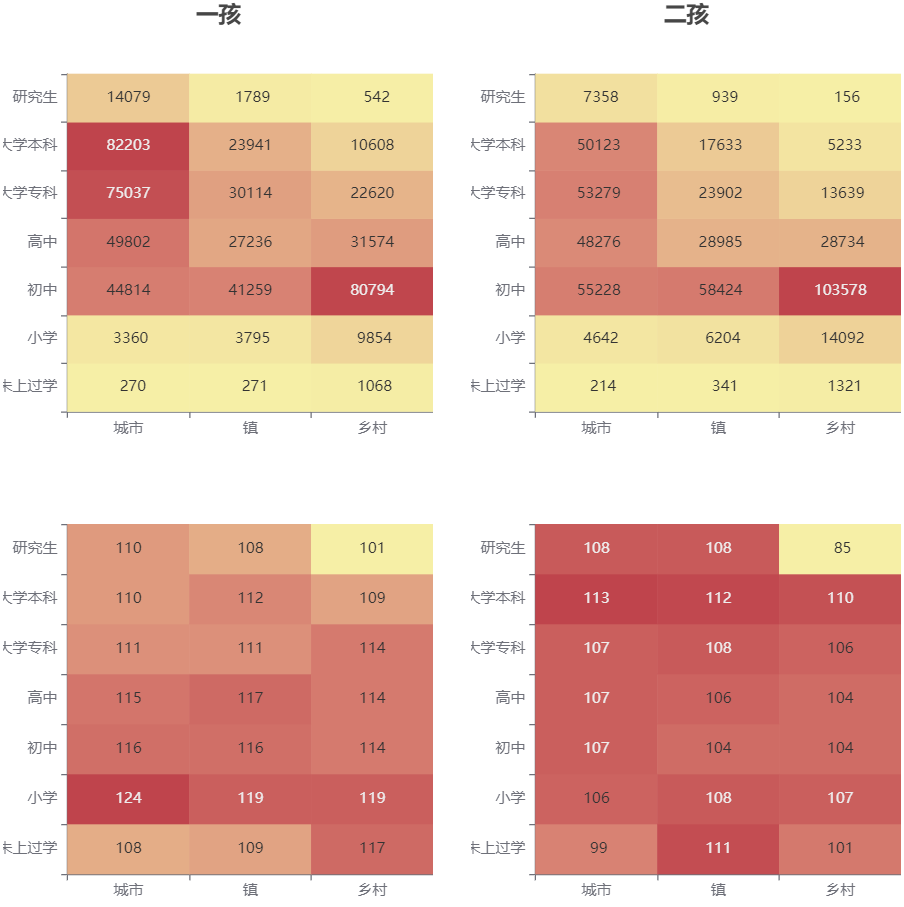
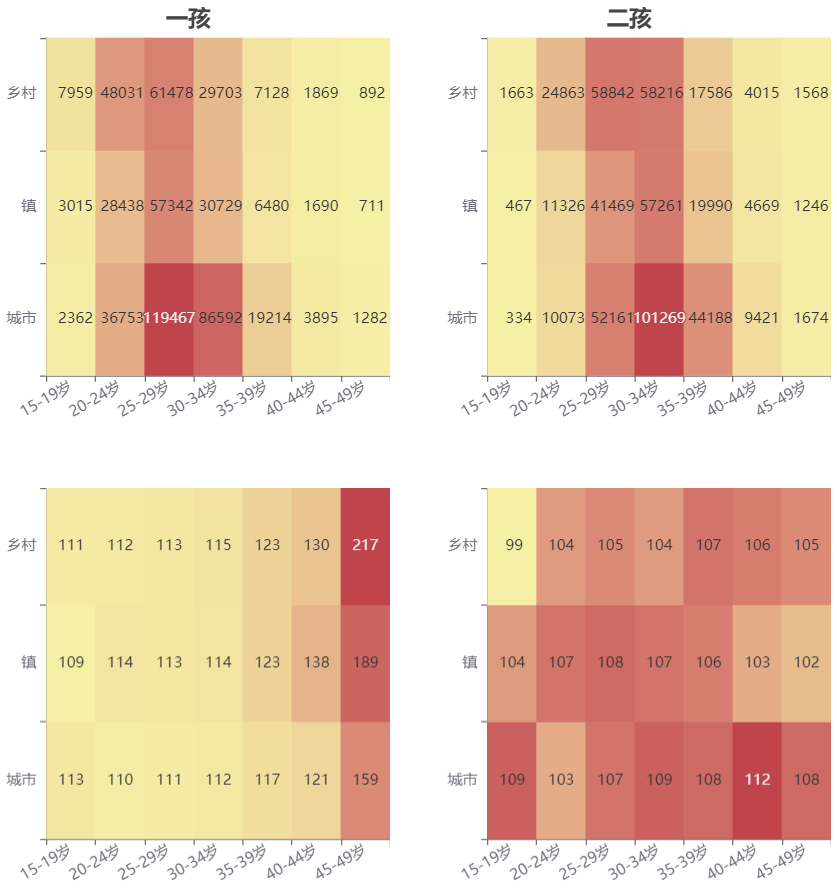
下图是按城乡、受教育程度划分的三七二十一个人群的热力图,并且按照一孩、二孩分开汇总,上半部分是生育妇女人数,下半部分是出生性别比。
-
对比一孩、二孩的生育妇女人数,即上面两个图。在乡村,受教育程度为初中的生育妇女人数最多,生育一孩的妇女中,初中占51%,生育二孩的妇女中,初中占62%。在城市,生育一孩的妇女中,大学本科占30%,大学专科占28%;而在生育二孩的妇女中,大学本科、大学专科、高中、初中的人数接近。这一方面说明城市中的生育妇女整体受教育程度更高,另一方面也说明城市中受教育程度更高的妇女生育二孩的人数比生育一孩的人数少。
-
对比一孩、二孩的人口性别比,即下面两个图。不论何种受教育程度,或者城乡之别,一孩的性别比普遍比二孩高。
查看绘图的数据和 R 代码
e1 <- data[year == '2019.11-2020.10' &
order == '一孩', by = .(type, education, order), .(allNum = sum(allNum))] |>
e_charts(type, height = 400) |>
e_heatmap(education, allNum) |>
e_visual_map(allNum, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(text = '一孩', left = 'center') |>
e_grid(left = '15%', right = 0)
e2 <- data[year == '2019.11-2020.10' &
order == '二孩', by = .(type, education, order), .(allNum = sum(allNum))] |>
e_charts(type, height = 400) |>
e_heatmap(education, allNum) |>
e_visual_map(allNum, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(text = '二孩', left = 'center') |>
e_grid(left = '15%', right = 0)
e3 <- data[year == '2019.11-2020.10' &
order == '一孩', by = .(type, education, order), .(prob = round(sum(boyNum) /
(1 + sum(girlNum)), 2) * 100)] |>
e_charts(type, height = 350) |>
e_heatmap(education, prob) |>
e_visual_map(prob, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(show = FALSE) |>
e_grid(left = '15%', right = 0, top = 0)
e4 <- data[year == '2019.11-2020.10' &
order == '二孩', by = .(type, education, order), .(prob = round(sum(boyNum) /
(1 + sum(girlNum)), 2) * 100)] |>
e_charts(type, height = 350) |>
e_heatmap(education, prob) |>
e_visual_map(prob, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(show = FALSE) |>
e_grid(left = '15%', right = 0, top = 0)
e_arrange(e1, e2, e3, e4, cols = 2)
3.2.2.年龄和受教育程度 🔗
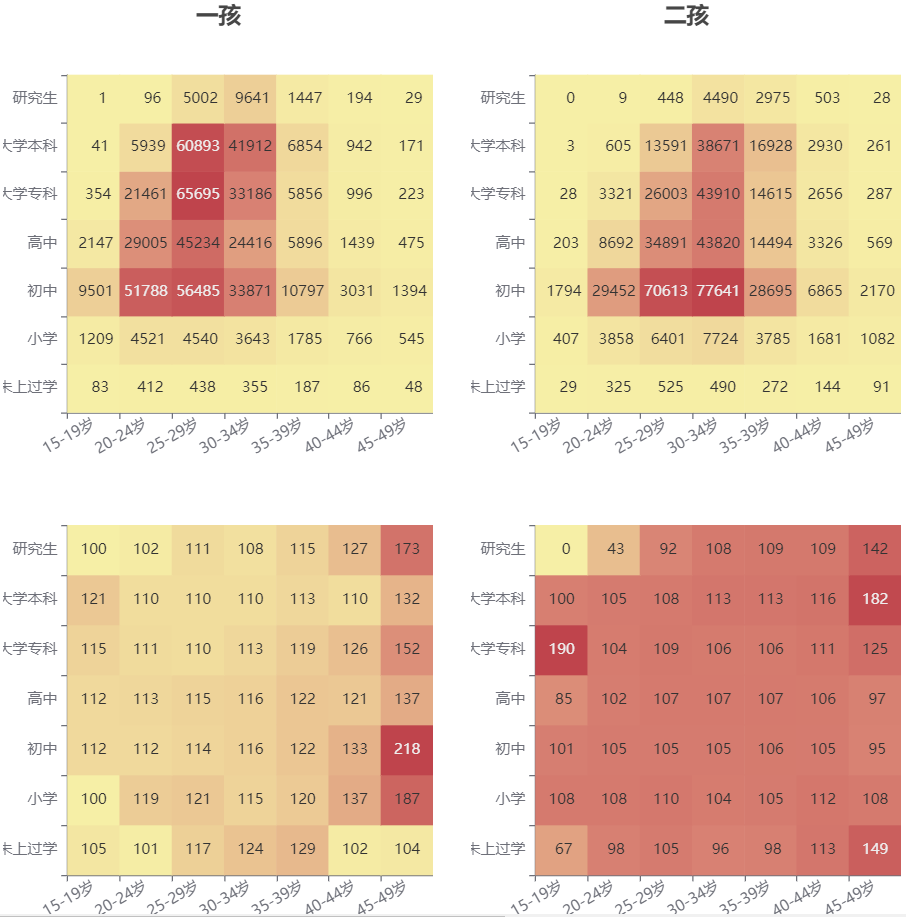
下图是按年龄、受教育程度划分的七七四十九个人群的热力图,并且按照一孩、二孩分开汇总,上半部分是生育妇女人数,下半部分是出生性别比。
-
对比一孩、二孩的生育妇女人数,即上面两个图。从图中颜色深浅即数量级来看,生育二孩的妇女所涵盖的受教育程度、年龄段的范围收窄。在生育二孩的妇女中,受教育程度为初中且年龄在25-29岁、30-34岁之间的人群数量最多。
-
对比一孩、二孩的人口性别比,即下面两个图。由于极少部分人群对应的性别比极高,导致人数较多的群体对应的性别比看上去更接近。整体上仍然与上一小节规律一致,即大多数人群的一孩性别比更高。
查看绘图的数据和 R 代码
e1 <- data[year == '2019.11-2020.10' &
order == '一孩', by = .(age, education, order), .(allNum = sum(allNum))] |>
e_charts(age, height = 400) |>
e_heatmap(education, allNum) |>
e_visual_map(allNum, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(text = '一孩', left = 'center') |>
e_grid(left = '15%', right = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e2 <- data[year == '2019.11-2020.10' &
order == '二孩', by = .(age, education, order), .(allNum = sum(allNum))] |>
e_charts(age, height = 400) |>
e_heatmap(education, allNum) |>
e_visual_map(allNum, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(text = '二孩', left = 'center') |>
e_grid(left = '15%', right = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e3 <- data[year == '2019.11-2020.10' &
order == '一孩', by = .(age, education, order), .(prob = round(sum(boyNum) /
(1 + sum(girlNum)), 2) * 100)] |>
e_charts(age, height = 350) |>
e_heatmap(education, prob) |>
e_visual_map(prob, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(show = FALSE) |>
e_grid(left = '15%', right = 0, top = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e4 <- data[year == '2019.11-2020.10' &
order == '二孩', by = .(age, education, order), .(prob = round(sum(boyNum) /
(1 + sum(girlNum)), 2) * 100)] |>
e_charts(age, height = 350) |>
e_heatmap(education, prob) |>
e_visual_map(prob, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(show = FALSE) |>
e_grid(left = '15%', right = 0, top = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e_arrange(e1, e2, e3, e4, cols = 2)
3.2.3.城乡和年龄 🔗
下图是按城乡、年龄划分的七三二十一个人群的热力图,并且按照一孩、二孩分开汇总,上半部分是生育妇女人数,下半部分是出生性别比。
-
对比一孩、二孩的生育妇女人数,即上面两个图。生育一孩人数最多的人群是城市、25-29岁,生育二孩人数最多的人群是城市、30-34岁,并且数量上比同年龄段镇、乡村的人数多了近一半,比较接近第3.1.1小节中的城乡人口结构。
-
对比一孩、二孩的人口性别比,即下面两个图。不论城市、镇、乡村之别,
45-49岁>40-44岁>35-39岁>其他年龄段,对应的就是1971-1975年出生的妇女在2020年生育一孩的性别比极高,远高于其后年份出生的妇女。
查看绘图的数据和 R 代码
e1 <- data[year == '2019.11-2020.10' &
order == '一孩', by = .(age, type, order), .(allNum = sum(allNum))] |>
e_charts(age, height = 400) |>
e_heatmap(type, allNum) |>
e_visual_map(allNum, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(text = '一孩', left = 'center', top = '8%') |>
e_grid(left = '15%', right = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e2 <- data[year == '2019.11-2020.10' &
order == '二孩', by = .(age, type, order), .(allNum = sum(allNum))] |>
e_charts(age, height = 400) |>
e_heatmap(type, allNum) |>
e_visual_map(allNum, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(text = '二孩', left = 'center', top = '8%') |>
e_grid(left = '15%', right = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e3 <- data[year == '2019.11-2020.10' &
order == '一孩', by = .(age, type, order), .(prob = round(sum(boyNum) /
(1 + sum(girlNum)), 2) * 100)] |>
e_charts(age, height = 350) |>
e_heatmap(type, prob) |>
e_visual_map(prob, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(show = FALSE) |>
e_grid(left = '15%', right = 0, top = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e4 <- data[year == '2019.11-2020.10' &
order == '二孩', by = .(age, type, order), .(prob = round(sum(boyNum) /
(1 + sum(girlNum)), 2) * 100)] |>
e_charts(age, height = 350) |>
e_heatmap(type, prob) |>
e_visual_map(prob, show = FALSE) |>
e_labels(position = 'inside') |>
e_title(show = FALSE) |>
e_grid(left = '15%', right = 0, top = 0) |>
e_x_axis(axisLabel = list(interval = 0, rotate = 30))
e_arrange(e1, e2, e3, e4, cols = 2)
第四章 结论 🔗
-
我们国家长期存在出生人口性别比失衡的问题,比对2010年和2020年的数据后可知,该问题有所改善但仍然失衡。
-
出生人口性别比失衡问题存在地区之间的明显差异,并且随着十年来计划生育政策、城乡人口结构、孩次结构等改变也产生了许多变化。在2010年,第一孩性别比低于第二孩性别比,到了2020年变成第一孩性别比高于第二孩性别比。虽然整体上出生人口性别比下降了,但第一孩性别比几乎没变,而是第二孩及多孩性别比下降较多,拉低了整体水平。
-
生育妇女人群的基本特征发生了变化,妇女生育的年龄往后推迟,且整体上受教育程度提高了。不能得出这些结论,比如城市或者乡村生育妇女的受教育程度越高,其生育一孩或二孩的性别比越低;或者不同受教育程度的生育妇女中,年龄越大其生育的一孩或二孩的性别比越高。这说明,一孩或二孩的性别比很可能不与生育妇女的年龄或受教育程度线性相关。
-
前几天突然又想起了杨小凯先生的《新兴古典经济学与超边际分析》,这是一本近十年前啃不动的书,现在也依然看不进去,但是这本书卡在我心里,好像每过几年就会想起来一次。我问新必应“杨小凯的超边际分析和边际分析有何异同”,AI 回答“传统的边际分析只考虑内点解(既有制度)的最优选择,无法解释制度变迁以及经济跨越发展的内在动力。而杨小凯提倡的超边际分析在原有的边际分析的基础上增加了对角点解的最优选择问题,从而增加了交易费用对分工深化与经济发展的解释力”。这个答案还真的是,既勾起了我的兴趣,又让我一点也不想去看……这次顺带还搜出来一篇林毅夫写的后发优势与后发劣势–与杨小凯教授商榷,这里面有不少内容在三水博客里面见他叨过。在费孝通先生的书里也见过关于后发优势与后发劣势的讨论,我打算猴年马月捋捋几位大师的不同观点。 ↩︎
-
把写好的博客发上网以后,照例是要快速读一遍检查错别字的,读到“馄饨未开”这里,忽然联想到“馄饨没煮开、生的也不能吃”,于是乎把自己逗乐了,这个错别字就不改了。 ↩︎
-
在搜集数据准备分析点什么之前,先看看领域之内别人都做了点撒是一种习惯。但是!现在不是写论文,而是写自家的博客,不需要非得把领域之内的论文尽量读个遍,也不需要写文献综述先叨叨前人干了些撒得出撒结论,更加不需要遵守什么格式要求,没有了各种条条框框的束缚,也不用考虑写出来要得到别人的认可,几乎就是自由地想写撒写撒、想怎么写就怎么写。哈哈,这感觉还挺不错的呢。 ↩︎