有一个神奇的网站叫红黑统计公报库,网站维护者们用爱发电搜集了很多县级的国民经济与社会发展统计公报。基于此,键者尝试抓取这些网页上的文本数据。在写代码抓取之前,先需要对页面的特点做些观察。
其一,键者留意到初始页面上有很多不同县的统计公报,点击其中一个后会跳转到每份统计公报的详细页面。而在初始页面最底端有翻页的按钮,点击第二页、尾页后页面的地址会改变,具体的地址如下。可以看出这些地址有简单的规律,如第2页的 URL (Uniform Resource Locator,统一资源定位符)地址是由“协议”https://、“域名”<tjgb.hongheiku.com>、“路径”</category/xjtjgb>、“参数”</page/2>等四个部分组成,其中参数中的数字代表第几页。如果在浏览器中输入https://tjgb.hongheiku.com/category/xjtjgb/page/1作为第一页的地址,会跳转到首页https://tjgb.hongheiku.com/category/xjtjgb。
# 首页
https://tjgb.hongheiku.com/category/xjtjgb
# 第二页
https://tjgb.hongheiku.com/category/xjtjgb/page/2
# 尾页
https://tjgb.hongheiku.com/category/xjtjgb/page/48
其二,在那些县级公报页面中,有些是普通的网页,公报的文本内容就隐藏在网页代码中,如https://tjgb.hongheiku.com/xjtjgb/xj2020/56349.html;但也有一些并非普通网页,公报的文本内容放在一个显示 PDF 文件的框里,如https://tjgb.hongheiku.com/xjtjgb/xj2020/56304.html。因此,在提取公报的文本内容时,需要区分出两种不同情况。
一、提取所有县级统计公报的网页地址(url) 🔗
在浏览器中打开首页,按 F12 打开“开发者模式”,使用“元素选择器”选中一个县级公报,查看对应的元素内容,如下所示。
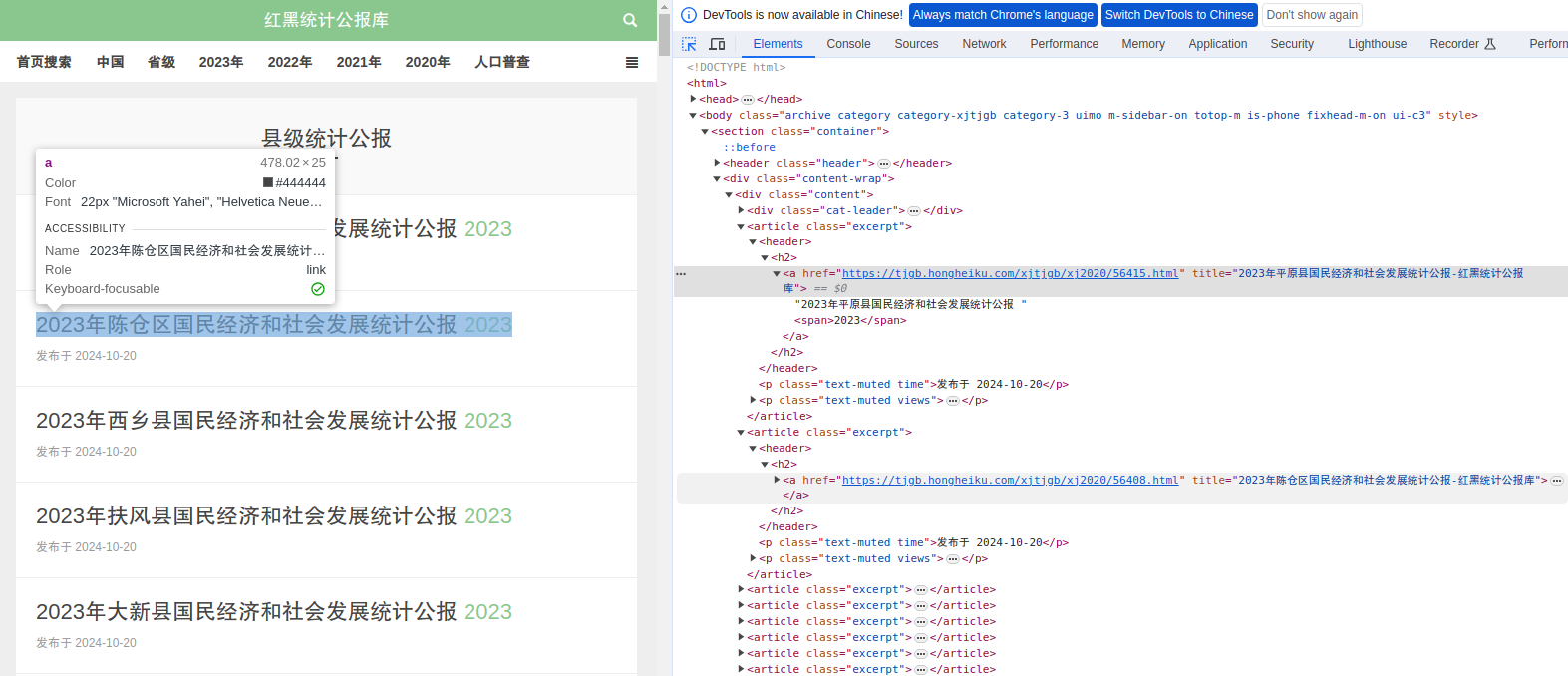
1.1.提取一个公报网页的 url 🔗
在元素窗格中,选中对应的元素内容,右键复制“outerHTML”可以得到这部分 HTML 代码,接着可以运用正则表达式提取所需要的内容。
txt <-
'<a href="https://tjgb.hongheiku.com/xjtjgb/xj2020/56415.html" title="2023年平原县国民经济和社会发展统计公报-红黑统计公报库">2023年平原县国民经济和社会发展统计公报 <span>2023</span></a>'
# 使用正则表达式匹配并提取含有 href 和 title 的 <a>
matches <-
regmatches(txt, gregexpr('<a href="([^"]+)" title="([^"]+)"', txt))
# 提取结果
hrefs <-
unlist(lapply(matches[[1]], function(x)
sub('.*href="([^"]*)".*', '\\1', x)))
titles <-
unlist(lapply(matches[[1]], function(x)
sub('.*title="([^"]*)".*', '\\1', x)))
data <- data.frame(hrefs , titles)
print(data)
| hrefs | titles | |
|---|---|---|
| 1 | https://tjgb.hongheiku.com/xjtjgb/xj2020/56415.html | 2023年平原县国民经济和社会发展统计公报-红黑统计公报库 |
1.2.遍历提取所有 url 🔗
根据提取一个 url 的方法,套上循环遍历所有页面的壳子,执行代码提取所有县级公报的 url。
all_data <- data.frame()
# 循环遍历每一页
for (i in 1:48) {
# 下载一个页面的网页源代码
url <-
paste0('https://tjgb.hongheiku.com/category/xjtjgb/page/', i)
html_lines = readLines(url)
doc = paste0(html_lines, collapse = '')
# 使用正则表达式匹配并提取含有 href 和 title 的 <a>
matches <-
regmatches(doc, gregexpr('<a href="([^"]+)" title="([^"]+)"', doc))
# 提取结果
hrefs <-
unlist(lapply(matches[[1]], function(x)
sub('.*href="([^"]*)".*', '\\1', x)))
titles <-
unlist(lapply(matches[[1]], function(x)
sub('.*title="([^"]*)".*', '\\1', x)))
data <- data.frame(hrefs , titles)
# 将每一页的数据添加到所有数据中
all_data <- rbind(all_data, data)
}
# 稍作整理
library(data.table)
setDT(all_data)
all_data$titles <-
sapply(all_data$titles, function(x)
gsub('-红黑统计公报库', '', x))
all_data <-
all_data[!(hrefs == 'https://tjgb.hongheiku.com')] # 去掉测试数据
fwrite(all_data, '/我的文件目录/honghei_urls.csv')
二、从纯文本形式的网页提取内容 🔗
2.1.提取一个网页中的文本段落 🔗
这个步骤最容易踩坑的地方是,不同的网页其文本内容被包裹在不同的 HTML 元素之中,如果不能找到一种普遍适用的匹配方式,有些内容就不能正确提取出来。
在 HTML 中,<p>(paragraph)元素代表一个文本段落。比如下面这个栗子,键者最初以为按tabindex="0" data-index="6"就可以匹配所有段落,后来发现这样不能覆盖所有情况,改为匹配所有<p>与</p>之间的文本。
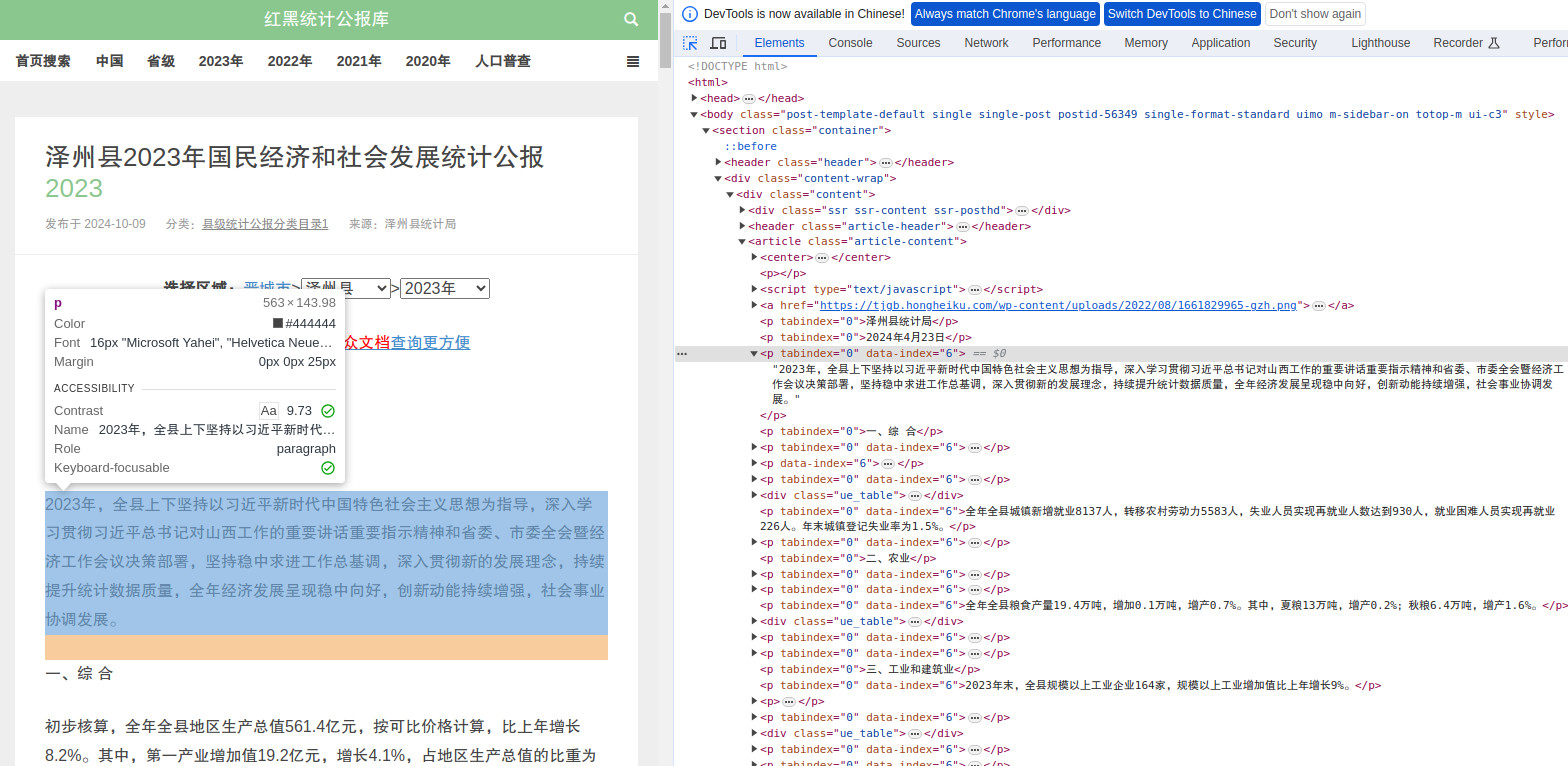
#url <- 'https://tjgb.hongheiku.com/xjtjgb/xj2020/56339.html'
url <- 'https://tjgb.hongheiku.com/xjtjgb/xj2020/56349.html'
html_lines <- readLines(url, warn = FALSE)
# 使用正则表达式提取文本
content <-
gsub('<p[^>]*>(.*?)</p>', '\\1', html_lines, perl = TRUE)
# 使用正则表达式匹配含有“养老”或“退休”且包含数字的段落
pattern <- ".*(养老保险|养老待遇|退休).*\\d+.*"
result <- grep(pattern , content, value = TRUE)
print(result)
[1] "年末全县参加城镇职工基本养老保险75209人,比上年末增加3917人;参加城乡居民基本养老保险301887人,减少1545人;参加城镇职工基本医疗保险55315人,增加6446人;参加城乡居民基本医疗保险380856人,减少11034人;参加失业保险39211人,增加2780人;参加工伤保险85558人,减少1341人。"
2.2.提取一个网页中的标签 🔗
打开一个县级统计公报的网页,在“选择区域”的菜单中可以切换同一个市不同县不同年份。由于第一步中仅提取了县级统计公报的名称和对应 url,因此第二步可以在公报网页再提取区域和年份标签。
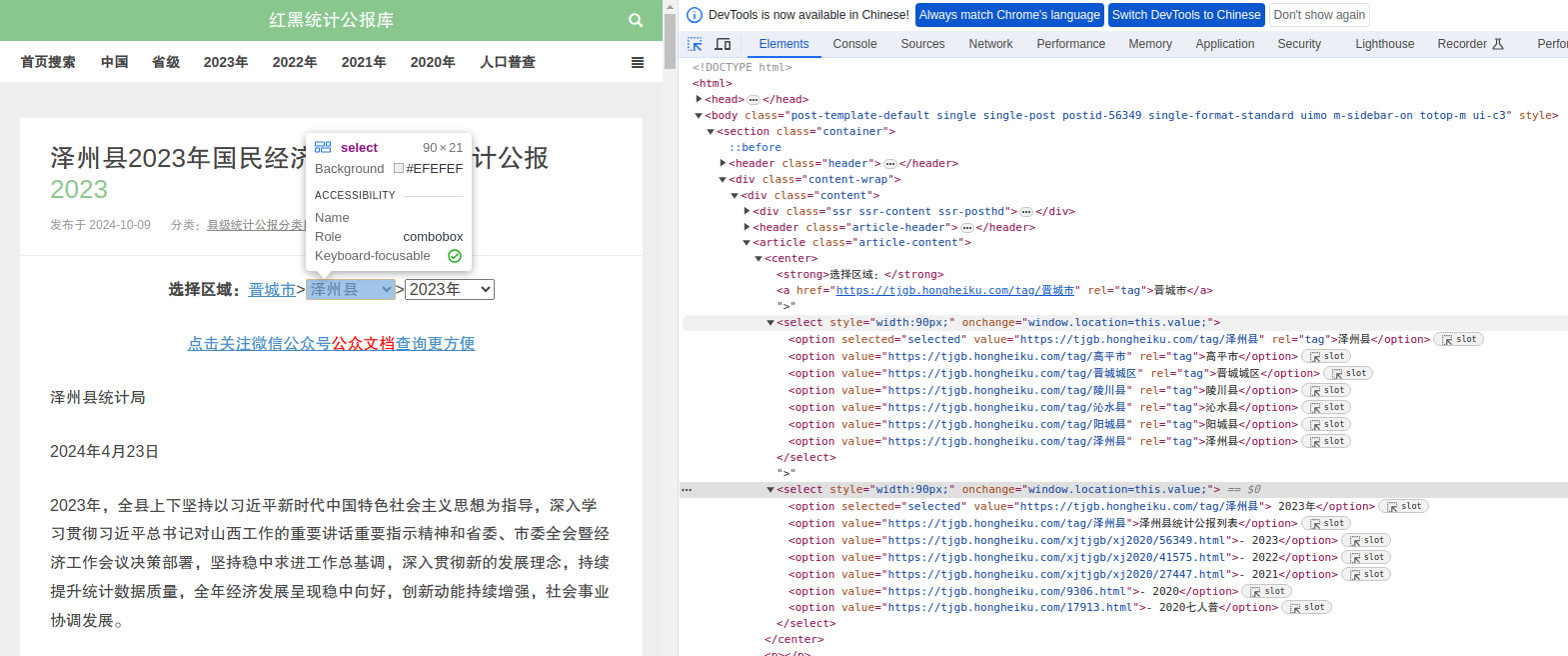
如上图所示,逐一查看所选中标签对应的元素内容,观察所需提取的标签内容。这里可以看出,“晋城市”被包裹在一个含有rel="tag"的<a>元素中,而“泽州县”、“2023年”分别被包裹在含有selected="selected"的<option>元素中,可根据这些规律运用正则表达式来提取结果。
<center>
<strong>选择区域:</strong>
<a href="https://tjgb.hongheiku.com/tag/晋城市" rel="tag">晋城市</a>>
<select style="width:90px;" onchange="window.location=this.value;">
<option selected="selected" value="https://tjgb.hongheiku.com/tag/泽州县" rel="tag">泽州县</option>
<option value="https://tjgb.hongheiku.com/tag/高平市" rel="tag">高平市</option>
<option value="https://tjgb.hongheiku.com/tag/晋城城区" rel="tag">晋城城区</option>
<option value="https://tjgb.hongheiku.com/tag/陵川县" rel="tag">陵川县</option>
<option value="https://tjgb.hongheiku.com/tag/沁水县" rel="tag">沁水县</option>
<option value="https://tjgb.hongheiku.com/tag/阳城县" rel="tag">阳城县</option>
<option value="https://tjgb.hongheiku.com/tag/泽州县" rel="tag">泽州县</option></select>
<select style="width:90px;" onchange="window.location=this.value;">
<option selected="selected" value="https://tjgb.hongheiku.com/tag/泽州县"> 2023年</option>
<option value="https://tjgb.hongheiku.com/tag/泽州县">泽州县统计公报列表</option>
<option value="https://tjgb.hongheiku.com/xjtjgb/xj2020/56349.html">- 2023</option>
<option value="https://tjgb.hongheiku.com/xjtjgb/xj2020/41575.html">- 2022</option>
<option value="https://tjgb.hongheiku.com/xjtjgb/xj2020/27447.html">- 2021</option>
<option value="https://tjgb.hongheiku.com/9306.html">- 2020</option>
<option value="https://tjgb.hongheiku.com/17913.html">- 2020七人普</option></select></center>
需要注意的是(PS这里键者也不明白为什么),“2023年”对应的<option>元素读取到 R 环境后,实际上长这样<option selected=\"selected\" value=\"https://tjgb.hongheiku.com/tag/泽州县\"> <span>2023</span>年</option>,对应提取年份的正则表达式需要据此进行修改。
url <- 'https://tjgb.hongheiku.com/xjtjgb/xj2020/56349.html'
html_lines <- readLines(url, warn = FALSE)
content_tag <- grep('选择区域', html_lines, value = TRUE)
# 提取城市名称
pattern1 <- '<a[^>]*rel="tag">([^<]*)</a>'
matches1 <- regmatches(content_tag, regexec(pattern1, content_tag))
city_name <- matches1[[1]][2]
# 提取县名称
pattern2 <-
'<option selected="selected"[^>]*rel="tag">([^<]*)</option>'
matches2 <- regmatches(content_tag, regexec(pattern2, content_tag))
county_name <- matches2[[1]][2]
# 提取年份
pattern3 <-
'<option selected="selected"[^>]*>.<span>([^<]*)</span>年</option>'
matches3 <- regmatches(content_tag, gregexec(pattern3, content_tag))
year <- matches3[[1]][2]
data <- data.frame(city_name , county_name, year)
print(data)
| city_name | county_name | year | |
|---|---|---|---|
| 1 | 晋城市 | 泽州县 | 2023 |
2.3.批量提取所有网页的文本 🔗
综合前面提取文本段落和标签的方法,分批次提取文本。
library(data.table)
# 导入第一章下载的县级公报的 url
data <- fread('/我的文件目录/honghei_urls.csv')
get_content <- function(url) {
attempt <- 1
max_attempts <- 3 # 设置打开每个 url 的最大尝试次数
while (attempt <= max_attempts) {
try({
html_lines <- readLines(url, warn = FALSE)
if (length(html_lines) == 0) {
return(list(
city_name = "",
county_name = "",
year = "",
result = ""
))
}
content_tag <- grep('选择区域', html_lines, value = TRUE)
# 提取城市名称
pattern1 <- '<a[^>]*rel="tag">([^<]*)</a>'
matches1 <-
regmatches(content_tag, regexec(pattern1, content_tag))
city_name <-
ifelse(length(matches1[[1]]) > 1, matches1[[1]][2], "")
# 提取县名称
pattern2 <-
'<option selected="selected"[^>]*rel="tag">([^<]*)</option>'
matches2 <-
regmatches(content_tag, regexec(pattern2, content_tag))
county_name <-
ifelse(length(matches2[[1]]) > 1, matches2[[1]][2], "")
# 提取年份
pattern3 <-
'<option selected="selected"[^>]*>.<span>([^<]*)</span>年</option>'
matches3 <-
regmatches(content_tag, gregexec(pattern3, content_tag))
year <-
ifelse(length(matches3[[1]]) > 1, matches3[[1]][2], "")
# 使用正则表达式提取文本段落
content <-
gsub('<p[^>]*>(.*?)</p>', '\\1', html_lines, perl = TRUE)
# 使用正则表达式匹配含有“养老”或“退休”且包含数字的段落
pattern <- ".*(养老保险|养老待遇|退休).*\\d+.*"
result <- grep(pattern, content, value = TRUE)
result <-
paste(unique(gsub("\n| ", "", result)), collapse = " ")
return(
list(
city_name = city_name,
county_name = county_name,
year = year,
result = result
)
)
}, silent = TRUE)
attempt <- attempt + 1
Sys.sleep(5) # 等待5秒后重试
}
return(list(
city_name = "",
county_name = "",
year = "",
result = ""
)) # 如果多次尝试后仍失败,返回空字符串
}
# 定义批处理函数
batch_process <- function(data, batch_size = 500) {
num_batches <- ceiling(nrow(data) / batch_size) # 计算批次数量
for (i in 1:num_batches) {
start_row <- (i - 1) * batch_size + 1
end_row <- min(i * batch_size, nrow(data))
# 获取当前批次的 hrefs
current_hrefs <- data[start_row:end_row, hrefs]
# 获取每个 URL 的内容
content_list <- lapply(current_hrefs, get_content)
# 将列表转换为数据框
content_df <- rbindlist(content_list)
# 赋值给 data.table 的相应列
data[start_row:end_row, c("city_name", "county_name", "year", "result") := .(
content_df$city_name,
content_df$county_name,
content_df$year,
content_df$result
)]
Sys.sleep(60) # 每批次执行结束后暂停60秒
}
return(data)
}
data <- batch_process(data)
# 去掉<>符号包裹的内容
data$result <- gsub("<[^>]+>", "", data$result)
fwrite(data, '/我的文件目录/honghei_href_text.csv')
三、从 PDF 文件形式的网页提取内容 🔗
此类网页是在页面上放了一个可以展示 PDF 文件的框(<iframe>元素),这样可以直接在浏览器中查看 PDF 文件,因此提取具体的文本内容需要分为多个步骤。
- 其一,从网页中提取 PDF 文件的网页链接(url)。
- 其二,下载 PDF 文件。
- 其三,读取 PDF 文件,提取所需文本。
3.1.提取一个 PDF 文件的 url 🔗
如下图所示,同样打开浏览器的开发者模式,使用元素选择器查看对应的元素内容。
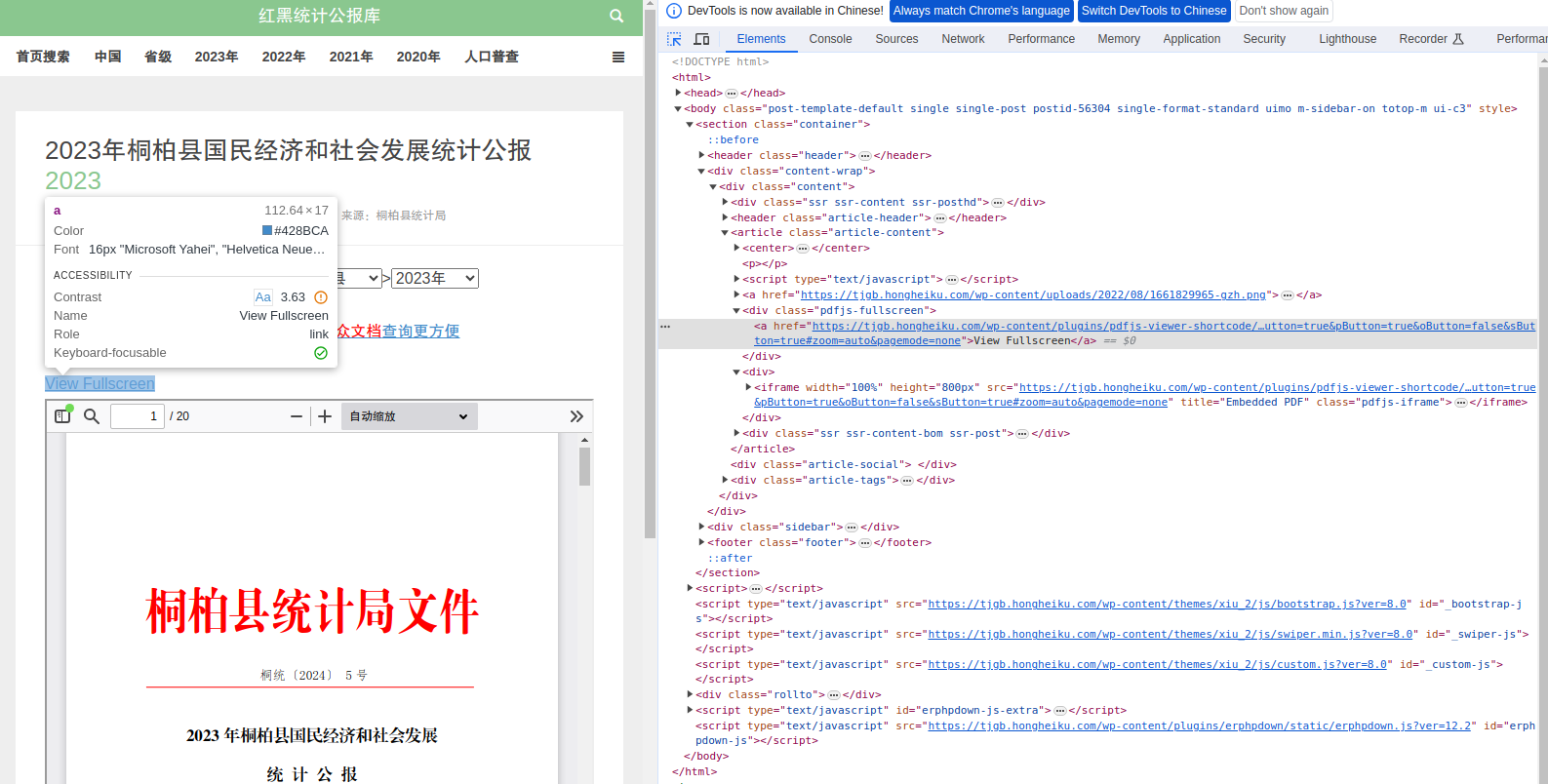
但是<a>元素里面存放的 pdf 文件的 url 特别长,这是因为原始网页使用了一个名为 pdfjs-viewer-shortcode 的插件(plugin),并且用了 file 参数来来指定文件路径,因此还可以进一步缩短 pdf 文件的 url。
<a href="https://tjgb.hongheiku.com/wp-content/plugins/pdfjs-viewer-shortcode/pdfjs/web/viewer.php?file=/wp-content/uploads/2024/10/1728310399-20240807164034233.pdf&dButton=true&pButton=true&oButton=false&sButton=true#zoom=auto&pagemode=none">View Fullscreen</a>
url <- 'https://tjgb.hongheiku.com/xjtjgb/xj2020/56304.html'
html_lines = readLines(url)
doc = paste0(html_lines, collapse = '')
# 使用正则表达式匹配含有 View Fullscreen 的 <a> 元素
matches <-
regmatches(doc, gregexpr('<a href="([^"]+)".*>View Fullscreen</a>', doc))
# 提取结果
pdf <- sub('.*(https://.*?\\.pdf).*', '\\1', matches)
pdf_url <-
sub(
'plugins/pdfjs-viewer-shortcode/pdfjs/web/viewer\\.php\\?file=/wp-content/',
'',
pdf)
print(pdf_url)
警告: incomplete final line found on 'https://tjgb.hongheiku.com/xjtjgb/xj2020/56304.html'[1] "https://tjgb.hongheiku.com/wp-content/uploads/2024/10/1728310399-20240807164034233.pdf"
3.2.批量提取 PDF 文件的 url 🔗
同样地,根据提取一个 PDF 文件 url 的方法封装函数,设置分批次执行。
library(data.table)
# 导入第一章下载的县级公报的 url
data <- fread('/我的文件目录/honghei_urls.csv')
ExtractPDFURL <- function(web_url, max_attempts = 3) {
attempt <- 1
while (attempt <= max_attempts) {
try({
html_lines <- readLines(web_url)
doc <- paste0(html_lines, collapse = '')
matches <-
regmatches(doc,
gregexpr('<a href="([^"]+)".*>View Fullscreen</a>', doc))
pdf <- sub('.*(https://.*?\\.pdf).*', '\\1', matches)
pdf_url <-
sub(
'plugins/pdfjs-viewer-shortcode/pdfjs/web/viewer\\.php\\?file=/wp-content/',
'',
pdf
)
return(pdf_url)
}, silent = TRUE)
attempt <- attempt + 1
Sys.sleep(5) # 设置等待秒数
}
return(NA) # 所有尝试均失败返回 NA
}
batch_process <- function(data, batch_size = 500) {
num_batches <- ceiling(nrow(data) / batch_size) # 计算批次数量
for (i in 1:num_batches) {
start_row <- (i - 1) * batch_size + 1
end_row <- min(i * batch_size, nrow(data))
data[start_row:end_row, pdf_url := sapply(hrefs, ExtractPDFURL)]
Sys.sleep(60) # 每个批次执行结束暂停60秒
}
return(data)
}
data <- batch_process(data)
out <- data[pdf_url %like% 'pdf'] # 留下 pdf 的 url
fwrite(out,'/我的文件目录/honghei_pdf_urls.csv')
3.3.读取一个 PDF 文件并提取文本 🔗
R base 中没有可以直接读取 PDF 文件的函数,这里使用 pdftools 包的 pdf_text 函数来实现此功能。
library(pdftools)
url <- 'https://tjgb.hongheiku.com/wp-content/uploads/2024/10/1728310399-20240807164034233.pdf'
# 指定工作目录
destPDFPath <- file.path('/我的文件目录/PDF', basename(url))
# 下载 PDF 文件
download.file(url, destPDFPath, mode = "wb")
# 读取 PDF 文件的文本内容
pdfContent <- pdf_text(destPDFPath)
# 提取所需的文本段落
pattern <- ".*(养老保险|养老待遇|退休).*\\d+.*"
result <- grep(pattern , pdfContent, value = TRUE)
result <- gsub('\n', '', result)
3.4.批量读取 PDF 文件 🔗
当键者打算用同样的套路封装函数、分批次下载并读取 PDF 文件时,踩到了一个深坑里,那就是无论分成多小的批次都会报一个错误—— R Session Aborted。
心塞之余,猜测是因为所有 PDF 文件中有极少数会出现读取失败的情况,而这极少数的失败会影响整体,即便是改成多尝试几次也不行。另外,可能也是因为键者的电脑使用的时间太长,支撑不了。最后只好分多个步骤处理。
- 第一步,先将所有 PDF 文件下载到一个指定目录。
- 第二步,再将原先的一个 PDF 文件目录拆成多个文件夹。
- 第三步,针对多个文件夹,逐一批量读取 PDF文件。
键者是按照每100个 PDF 文件存到一个新文件夹里,这样拆分了十几个文件夹以后,有一半能正常批量读取,另一半依然报错。唉,无奈叹气中……